
python爬蟲--旅遊景點
阿新 • • 發佈:2018-12-19
一、準備工作
1、python編譯器IDLE 或者下載pycharm(網上有教程和破解期限) 匯入requests包和BeautifulSoup4包。 (快速下載包方法見我的部落格【快速pip下載python包】文章) 2、chrome谷歌瀏覽器(ie也湊合用)
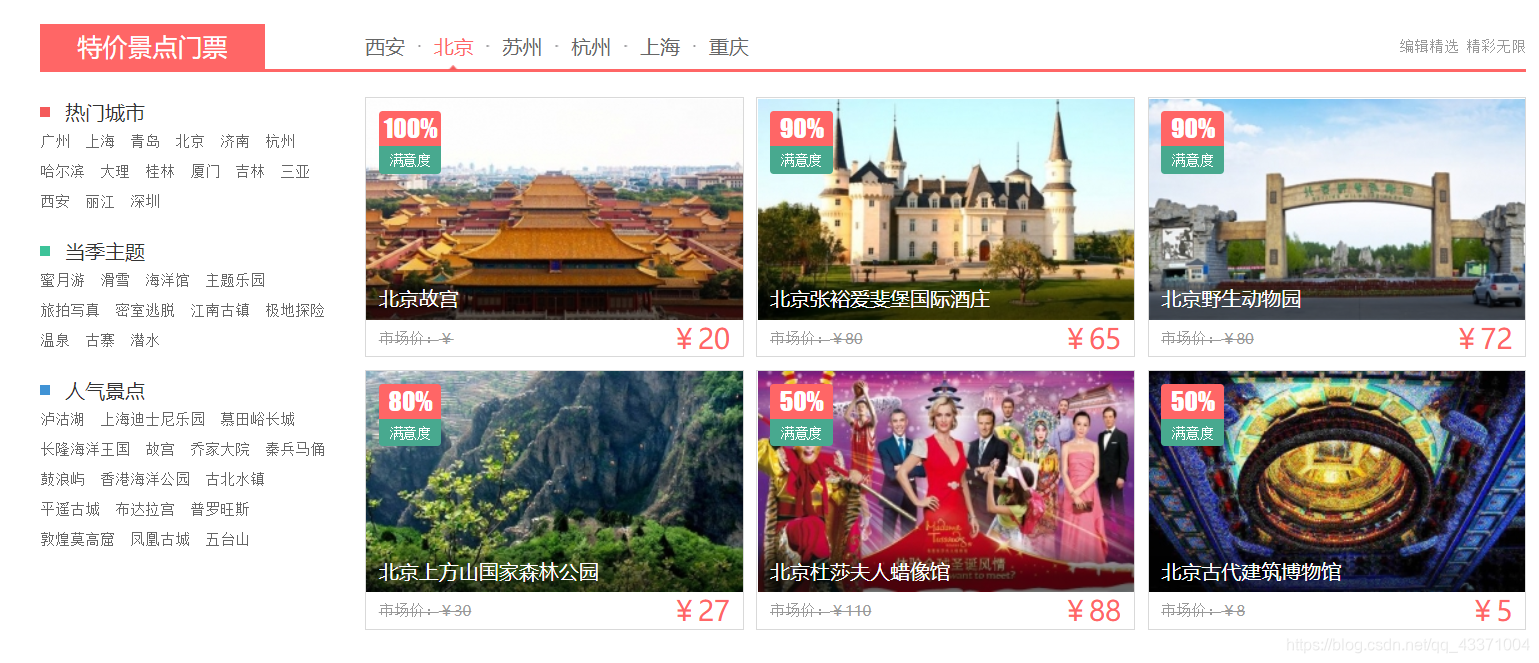
對下面這部分的資訊,包括名稱,價格,圖片的爬取。
程式碼如下
import requests from bs4 import BeautifulSoup url = requests.get('https://go.hao123.com')#請求這個網址 soup = BeautifulSoup(url.content, "lxml")#解析網址 #print(soup) #可以檢視HTML原始碼 images = soup.select('body > div.content-outer-wrapper > div > div > div > div > div > div > div > a > img') prices = soup.select('body > div.content-outer-wrapper > div > div > div.tejia-menpiao > div.container > div > div > div.price > a > div.new') names = soup.select('body > div.content-outer-wrapper > div > div > div.tejia-menpiao > div.container > div > div > div.pic > a > div') data = {} #三個同時遍歷用到zip() for name, price, image in zip(names, prices, images): data = { 'name': name.get_text(), 'price': price.get_text(), 'img': image.get('src') } print(data) #遍歷列表,並用字典儲存
程式碼中的soup.select(’*******’)這裡解釋一下使用方法。
谷歌瀏覽器開啟網頁
滑鼠放在你所要抓取的圖片上右鍵檢查
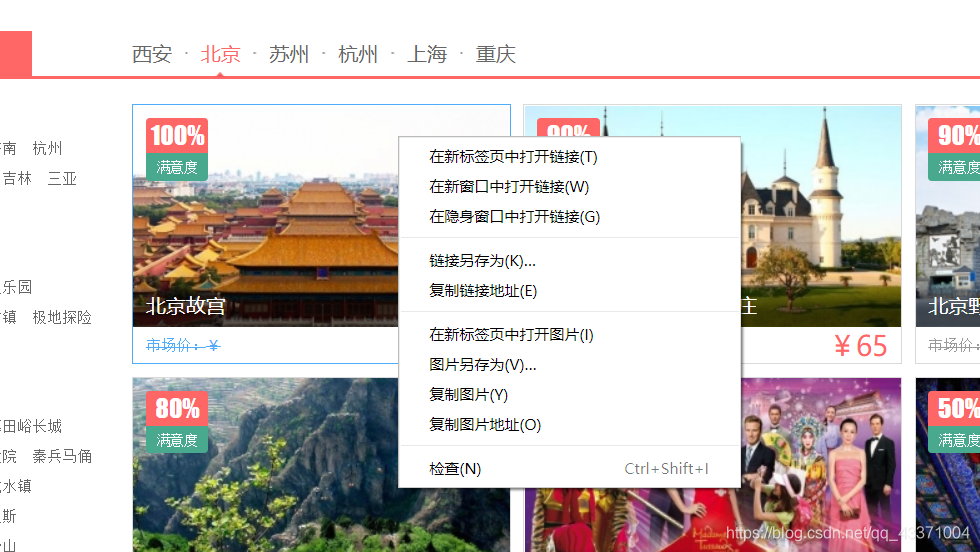 之後你會看到以下原始碼,並且有一部分被索引著。
之後你會看到以下原始碼,並且有一部分被索引著。
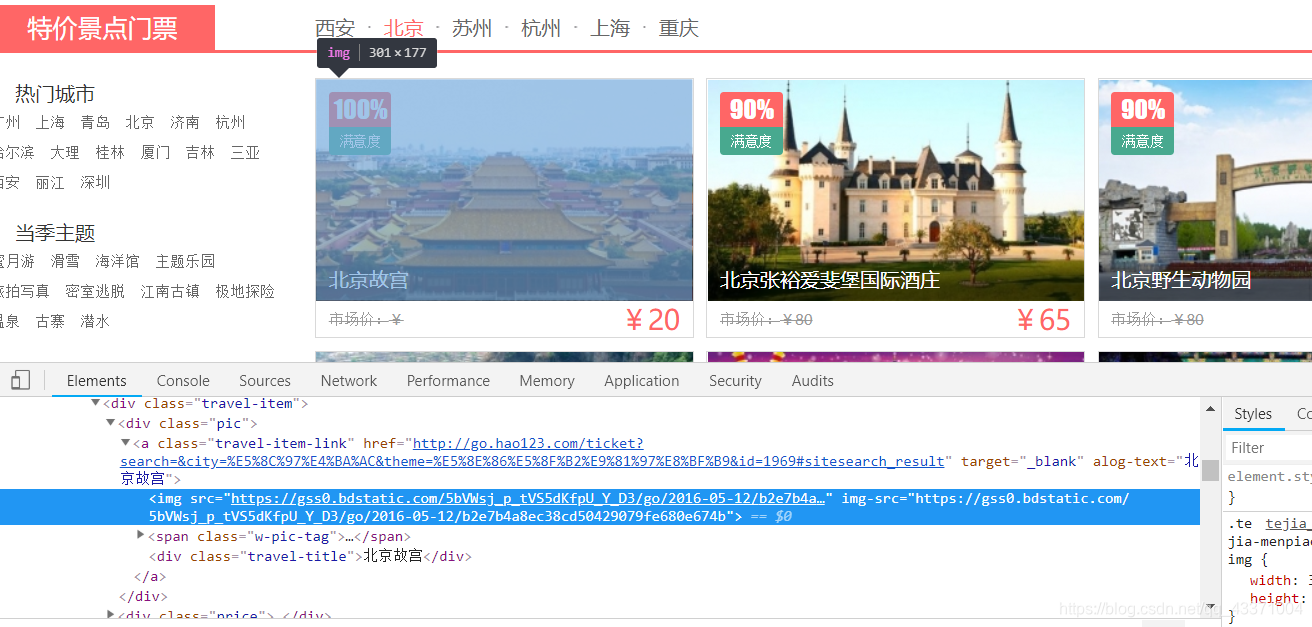 然後滑鼠放在索引著的部分右鍵 copy --> copy selector ,你會得到以下程式碼
然後滑鼠放在索引著的部分右鍵 copy --> copy selector ,你會得到以下程式碼
body > div.content-outer-wrapper > div > div:nth-child(2) > div.tejia-menpiao > div.container > div:nth-child(2) > div:nth-child(1) > div.pic > a > img
將裡面的 :nth-child(2) 或者 :nth-child(1) 之類的這種刪除,別的什麼都不用動,空格也不要刪。之後剩下的就是soup.select()裡面填寫的,挑選圖片的。挑選別的方法類似。
body > div.content-outer-wrapper > div > div > div.tejia-menpiao > div.container > div: > div > div.pic > a > img
最後輸出結果
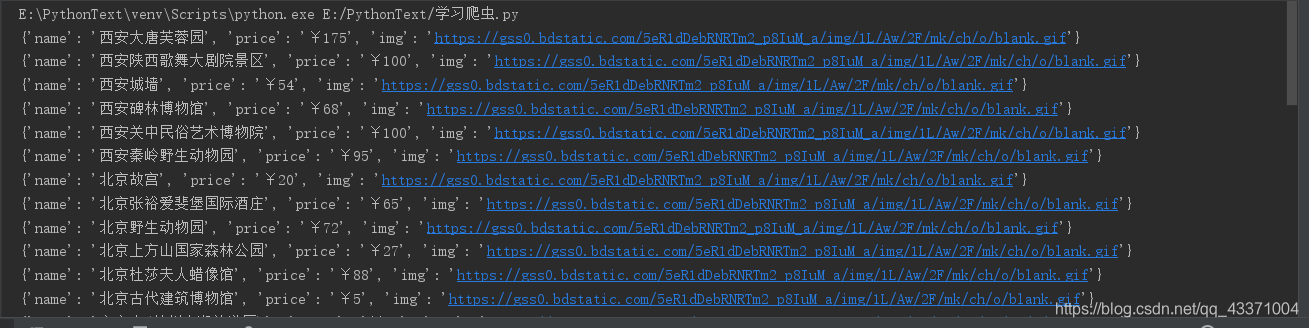
謝謝支援,本人親測成功執行。