
牛奶盒噴碼字元識別(基於opencv)————(三)字元的識別
阿新 • • 發佈:2018-12-19
更新
效果
先看效果吧。

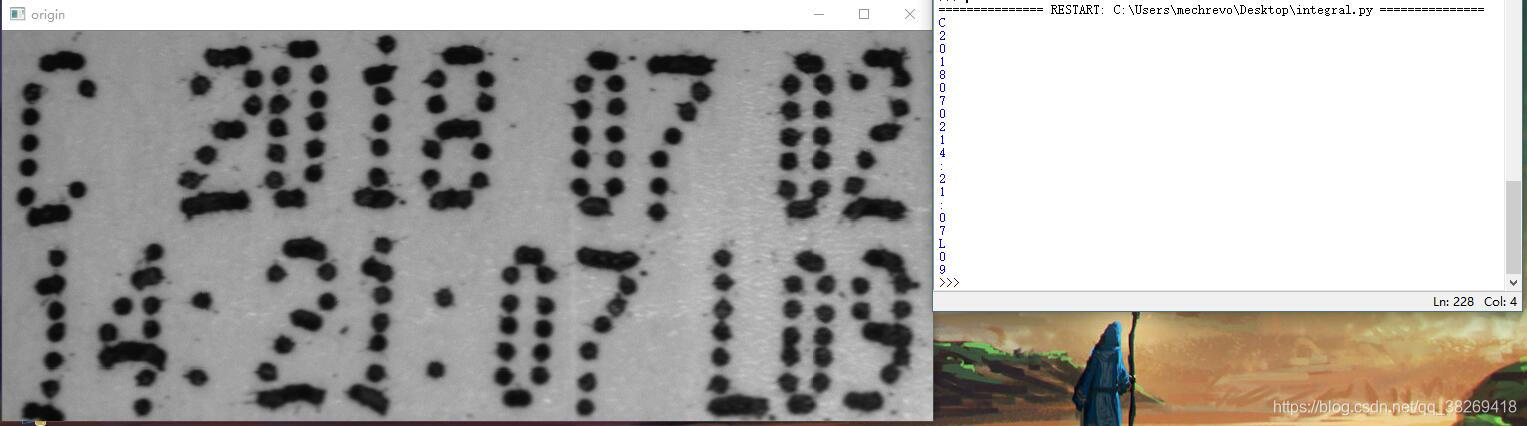

效果極佳,
方法
1.製作模板
將分割出來的數字,效果很不錯的當作我們的模板,後面用作匹配,C L :都當作數字處理

2.讀入模板,
這裡我通過建立三維陣列,採用for迴圈讀入
注意,讀取時候,要加0引數,不然會以三通道方式讀取。
templatepath="C:\\Users\\mechrevo\\Desktop\\template\\" #模板
template=np.zeros([dsize,dsize,13],np.uint8) #注意uint8為1通道,預設為 3通道
for i in range(13):
#print(i)
template[ 3.讀入分割出來的圖片
將上一節分割出來的20張圖片,都讀入進去,同樣構建三維陣列,for迴圈讀入
img=np.zeros([dsize,dsize,20],np.uint8)
for i in range(20):
# print(i)
img[:,:,i] = cv2.imread(root + "%d.png" %i, 0) #記住引數 0
#cv2.imshow("s"+ "%d" %i, img[:,:,i])
4.逐一匹配
採用巢狀for迴圈,使得每個分割的影象與模板匹配,算出來的rez值最大的,就是最有可能的字元,這裡採用cv2.TM_CCOEFF_NORMED
總之,越複雜,佔用cpu越多,越耗時,但是越準確。
res=np.zeros([13],np.float16)
for i in range(20):
for j in range(13):
res[j] = cv2.matchTemplate(img[:,:,i],template[:,:,j],cv2.TM_CCOEFF_NORMED) #注意邏輯
maxindex = np.argmax(res)
if 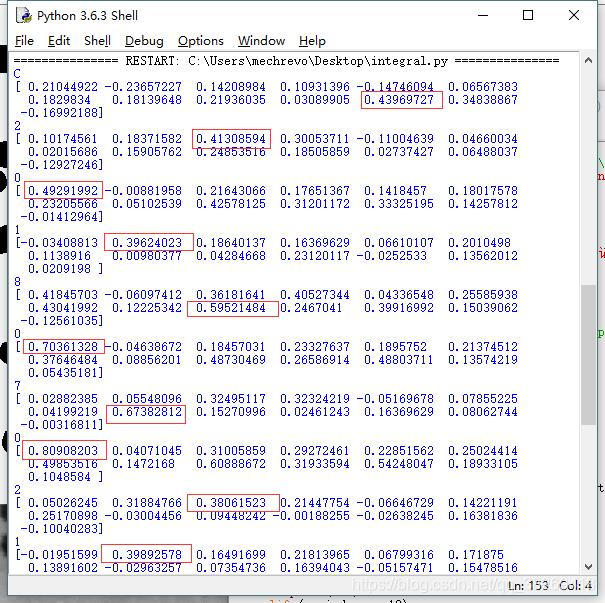
看看誰最大,使用np.argmax直接得出答案,在等於10,11,12加入判斷即可
效果如頂部那樣,統計了50張圖,也就是1000個數字,準確率為95.2%
不足
當然演算法還有一些不足之處:
比如:
1.如果字元不為20的話,演算法會出錯,只不過我的資料集90%的圖都是20個字元的,要改進,可以使用檔案操作相關函式
2.對於0和8,或扭曲數字,很容易出錯,有機會我會嘗試卷積神經網路。
3.對於一些扭曲的圖片,兩行直接沒有白色畫素,有很小几率會無法切割行。
總之,這只是一門選修課,我也不願太費心思去繼續改進,有什麼問題可以評論區交流.
等結課後公佈完整程式碼,供大家學習交流。