
[GAN學習系列2] GAN的起源
本文大約 5000 字,閱讀大約需要 10 分鐘
這是 GAN 學習系列的第二篇文章,這篇文章將開始介紹 GAN 的起源之作,鼻祖,也就是 Ian Goodfellow 在 2014 年發表在 ICLR 的論文–Generative Adversarial Networks”,當然由於數學功底有限,所以會簡單介紹用到的數學公式和背後的基本原理,並介紹相應的優缺點。
基本原理
在[GAN學習系列] 初識GAN中,介紹了 GAN 背後的基本思想就是兩個網路彼此博弈。生成器 G 的目標是可以學習到輸入資料的分佈從而生成非常真實的圖片,而判別器 D 的目標是可以正確辨別出真實圖片和 G 生成的圖片之間的差異。正如下圖所示:
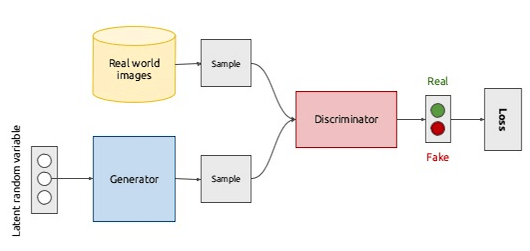
上圖給出了生成對抗網路的一個整體結構,生成器 G 和判別器 D 都是有各自的網路結構和不同的輸入,其中 G 的輸出,即生成的樣本也是 D 的輸入之一,而 D 則會為 G 提供梯度進行權重的更新。
那麼問題來了,如果 D 是一個非常好的分類器,那麼我們是否真的可以生成非常逼真的樣本來欺騙它呢?
對抗樣本
在正式介紹 GAN 的原理之前,先介紹一個概念–對抗樣本(adversarial example),它是指經過精心計算得到的用於誤導分類器的樣本。例如下圖就是一個例子,左邊是一個熊貓,但是添加了少量隨機噪聲變成右圖後,分類器給出的預測類別卻是長臂猿,但視覺上左右兩幅圖片並沒有太大改變。

所以為什麼在簡單添加了噪聲後會誤導分類器呢?
這是因為影象分類器本質上是高維空間的一個複雜的決策邊界。當然涉及到影象分類的時候,由於是高維空間而不是簡單的兩維或者三維空間,我們無法畫出這個邊界出來。但是我們可以肯定的是,訓練完成後,分類器是無法泛化到所有資料上,除非我們的訓練集包含了分類類別的所有資料,但實際上我們做不到。而做不到泛化到所有資料的分類器,其實就會過擬合訓練集的資料,這也就是我們可以利用的一點。
我們可以給圖片新增一個非常接近於 0 的隨機噪聲,這可以通過控制噪聲的 L2 範數來實現。L2 範數可以看做是一個向量的長度,這裡有個訣竅就是圖片的畫素越多,即圖片尺寸越大,其平均 L2 範數也就越大。因此,當新增的噪聲的範數足夠低,那麼視覺上你不會覺得這張圖片有什麼不同,正如上述右邊的圖片一樣,看起來依然和左邊原始圖片一模一樣;但是,在向量空間上,新增噪聲後的圖片和原始圖片已經有很大的距離了!
為什麼會這樣呢?
因為在 L2 範數看來,對於熊貓和長臂猿的決策邊界並沒有那麼遠,添加了非常微弱的隨機噪聲的圖片可能就遠離了熊貓的決策邊界內,到達長臂猿的預測範圍內,因此欺騙了分類器。
除了這種簡單的新增隨機噪聲,還可以通過影象變形的方式,使得新影象和原始影象視覺上一樣的情況下,讓分類器得到有很高置信度的錯誤分類結果。這種過程也被稱為對抗攻擊(adversarial attack),這種生成方式的簡單性也是給 GAN 提供瞭解釋。
生成器和判別器
現在如果將上述說的分類器設定為二值分類器,即判斷真和假,那麼根據 Ian Goodfellow 的原始論文的說法,它就是判別器 (Discriminator)。
有了判別器,那還需要有生成假樣本來欺騙判別器的網路,也就是生成器 (Generator)。這兩個網路結合起來就是生成對抗網路(GAN),根據原始論文,它的目標如下:
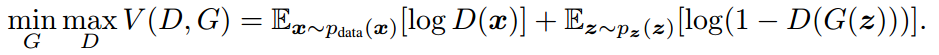
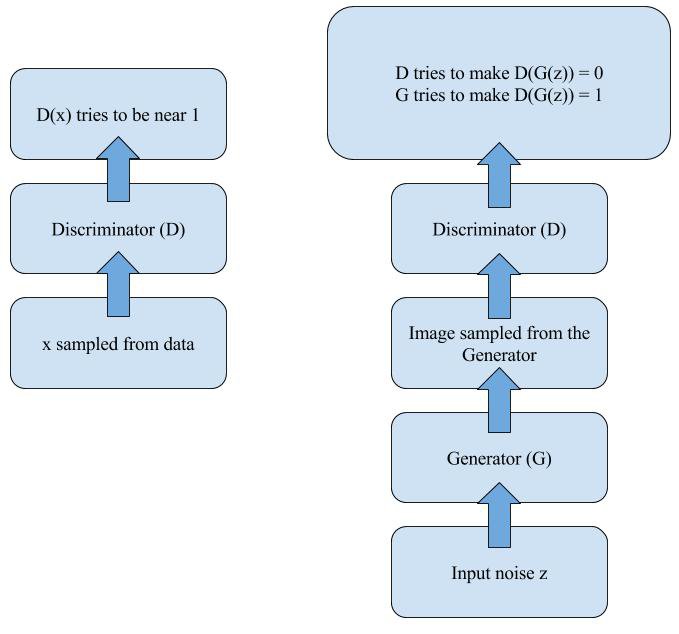
兩個網路的工作原理可以如下圖所示,D 的目標就是判別真實圖片和 G 生成的圖片的真假,而 G 是接收一個隨機噪聲來生成圖片,並努力欺騙 D 。
簡單來說,GAN 的基本思想就是一個最小最大定理,當兩個玩家(D 和 G)彼此競爭時(零和博弈),雙方都假設對方採取最優的步驟而自己也以最優的策略應對(最小最大策略),那麼結果就已經預先確定了,玩家無法改變它(納什均衡)。
因此,它們的損失函式,D 的是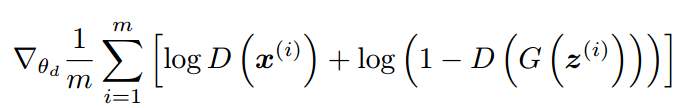
G 的是

這裡根據它們的損失函式分析下,G 網路的訓練目標就是讓 D(G(z)) 趨近於 1,這也是讓其 loss 變小的做法;而 D 網路的訓練目標是區分真假資料,自然是**讓 D(x) 趨近於 1,而 D(G(z)) 趨近於 0 。**這就是兩個網路相互對抗,彼此博弈的過程了。
那麼,它們相互對抗的效果是怎樣的呢?在論文中 Ian Goodfellow 用下圖來描述這個過程:
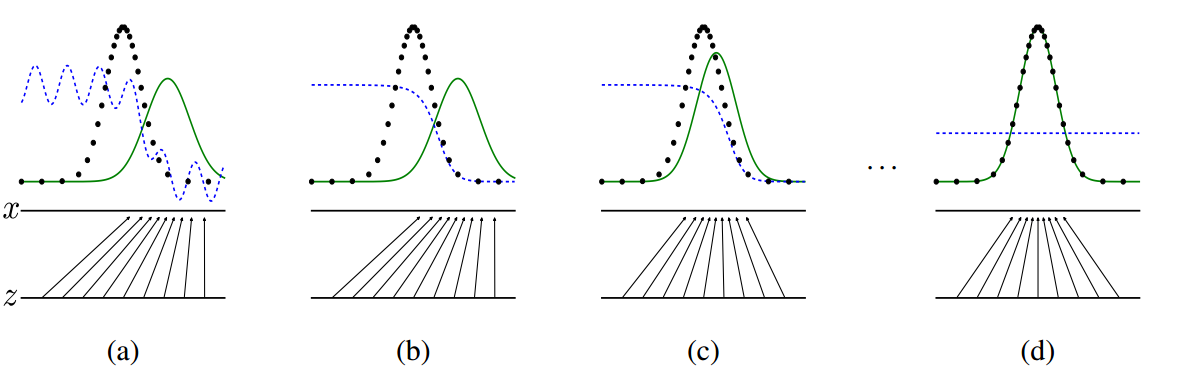
上圖中,黑色曲線表示輸入資料 x 的實際分佈,綠色曲線表示的是 G 網路生成資料的分佈,我們的目標自然是希望著兩條曲線可以相互重合,也就是兩個資料分佈一致了。而藍色的曲線表示的是生成資料對應於 D 的分佈。
在 a 圖中是剛開始訓練的時候,D 的分類能力還不是最好,因此有所波動,而生成資料的分佈也自然和真實資料分佈不同,畢竟 G 網路輸入是隨機生成的噪聲;到了 b 圖的時候,D 網路的分類能力就比較好了,可以看到對於真實資料和生成資料,它是明顯可以區分出來,也就是給出的概率是不同的;
而綠色的曲線,即 G 網路的目標是學習真實資料的分佈,所以它會往藍色曲線方向移動,也就是 c 圖了,並且因為 G 和 D 是相互對抗的,當 G 網路提升,也會影響 D 網路的分辨能力。論文中,Ian Goodfellow 做出了證明,當假設 G 網路不變,訓練 D 網路,最優的情況會是:
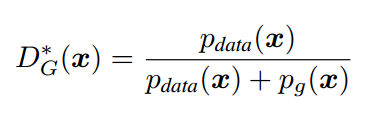
也就是當生成資料的分佈 趨近於真實資料分佈 $p_{data}(x) $的時候,D 網路輸出的概率 會趨近於 0.5,也就是 d 圖的結果,這也是最終希望達到的訓練結果,這時候 G 和 D 網路也就達到一個平衡狀態。
訓練策略和演算法實現
論文給出的演算法實現過程如下所示:

這裡包含了一些訓練的技巧和方法:
- 首先 G 和 D 是同步訓練,但兩者訓練次數不一樣,通常是 D 網路訓練 k 次後,G 訓練一次。主要原因是 GAN 剛開始訓練時候會很不穩定;
- D 的訓練是同時輸入真實資料和生成資料來計算 loss,而不是採用交叉熵(cross entropy)分開計算。不採用 cross entropy 的原因是這會讓 D(G(z)) 變為 0,導致沒有梯度提供給 G 更新,而現在 GAN 的做法是會收斂到 0.5;
- 實際訓練的時候,作者是採用 來代替 ,這是希望在訓練初始就可以加大梯度資訊,這是因為初始階段 D 的分類能力會遠大於 G 生成足夠真實資料的能力,但這種修改也將讓整個 GAN 不再是一個完美的零和博弈。
分析
優點
GAN 在巧妙設計了目標函式後,它就擁有以下兩個優點。
- 首先,GAN 中的 G 作為生成模型,不需要像傳統圖模型一樣,需要一個嚴格的生成資料的表示式。這就避免了當資料非常複雜的時候,複雜度過度增長導致的不可計算。
- 其次,它也不需要 inference 模型中的一些龐大計算量的求和計算。它唯一的需要的就是,一個噪音輸入,一堆無標準的真實資料,兩個可以逼近函式的網路。
缺點
雖然 GAN 避免了傳統生成模型方法的缺陷,但是在它剛出來兩年後,在 2016 年才開始逐漸有非常多和 GAN 相關的論文發表,其原因自然是初代 GAN 的缺點也是非常難解決:
- 首當其衝的缺點就是 GAN 過於自由導致訓練難以收斂以及不穩定;
- 其次,原始 G 的損失函式 沒有意義,它是讓G 最小化 D 識別出自己生成的假樣本的概率,但實際上它會導致梯度消失問題,這是由於開始訓練的時候,G 生成的圖片非常糟糕,D 可以輕而易舉的識別出來,這樣 D 的訓練沒有任何損失,也就沒有有效的梯度資訊回傳給 G 去優化它自己,這就是梯度消失了;
- 最後,雖然作者意識到這個問題,在實際應用中改用 來代替,這相當於從最小化 D 揪出自己的概率,變成了最大化 D 抓不到自己的概率。雖然直觀上感覺是一致的,但其實並不在理論上等價,也更沒有了理論保證在這樣的替代目標函式訓練下,GAN 還會達到平衡。這個結果會導致模式奔潰問題,其實也就是[GAN學習系列] 初識GAN中提到的兩個缺陷。
當然,上述的問題在最近兩年各種 GAN 變體中逐漸得到解決方法,比如對於訓練太自由的,出現了 cGAN,即提供了一些條件資訊給 G 網路,比如類別標籤等資訊;對於 loss 問題,也出現如 WGAN 等設計新的 loss 來解決這個問題。後續會繼續介紹不同的 GAN 的變體,它們在不同方面改進原始 GAN 的問題,並且也應用在多個方面。
參考文章:
配圖來自網路和論文 Generative Adversarial Networks 中
歡迎關注我的微信公眾號–機器學習與計算機視覺或者掃描下方的二維碼,和我分享你的建議和看法,指正文章中可能存在的錯誤,大家一起交流,學習和進步!
