
GAN學習總結一 GAN基本概念理解
GAN學習總結一GAN基本概念理解
GAN(Generative Adversarial Network)生成式對抗網路,由Ian Goodfellow 首先提出,是近兩年來最熱門的東西,彷彿什麼都可以利用GAN來產生,最近在進行影象超解像相關工作,也看到了利用GAN進行超解析相關工作,看了一些資料和李弘毅老師的視訊,做一些學習筆記,後續能溫故而知新。
1.什麼是GAN?
GAN啟發自博弈論中的二人零和博弈(two-player game),GAN 模型中的兩位博弈方分別由生成式模型(generative model)和判別式模型(discriminative model)充當。生成模型 G 捕捉樣本資料的分佈,用服從某一分佈(均勻分佈,高斯分佈等)的噪聲 z 生成一個類似真實訓練資料的樣本,追求效果是越像真實樣本越好;判別模型 D 是一個二分類器,估計一個樣本來自於訓練資料(而非生成資料)的概率,如果樣本來自於真實的訓練資料,D 輸出大概率,否則,D 輸出小概率。
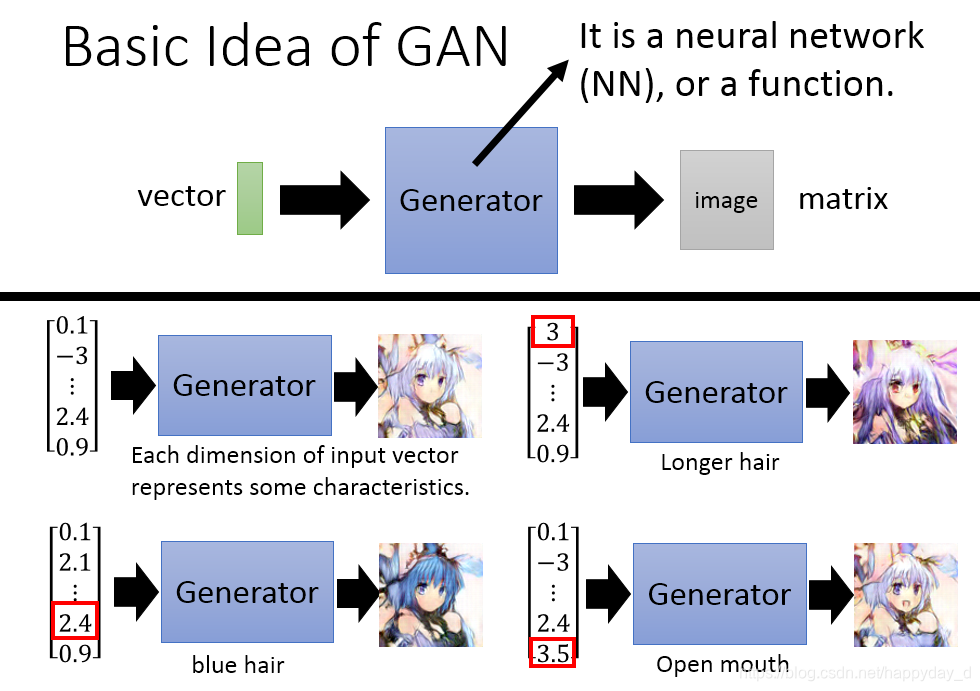
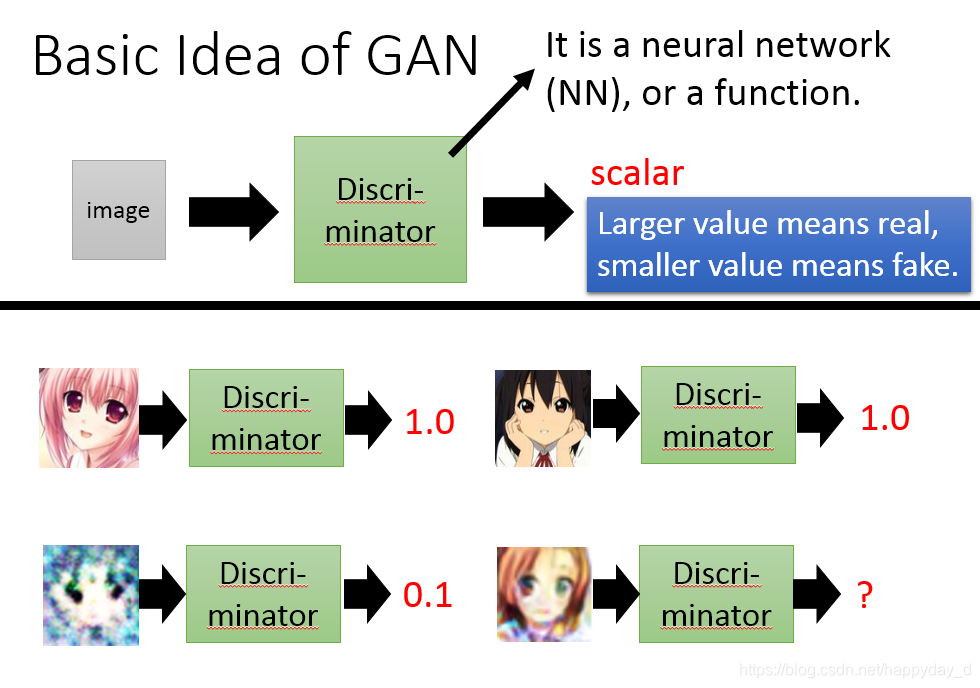
如下圖二次元人物生成過程,上圖為Generator,給出一個向量,經過Generator產生出一個影象,給出不同的向量可以得到不同的影象,存在一個問題是產生的影象是否接近真實的影象,此時需要Discriminator來判定,如下圖,真實的影象D網路給出較高的分數,而不真實的影象給出較低的分數,最終的目的是G網路產生的影象D網路也能給出很高的分數。


2.GAN網路訓練?
以上面二次元影象生成為例說明,G(Generator)和D(Discriminator)
- G作用是接收一個向量Z(隨機噪聲),通過G生成影象,記做G(Z);
- D作用是判別一張影象是否是“真實的”。輸入是X,X表示一張真實影象,則D(X)表示真實影象的概率,為1表示100%的真實的影象,而輸出0,表示不是真實的影象。
訓練過程中,固定一方,更新另一方的網路權重,交替迭代,在這個過程中,雙方都極力的優化自己的網路,從而形成競爭對抗,直到雙方達到一個動態的平衡。理想情況下,最後的結果是G生成的影象和真實的影象非常相似,D網路難以區分真實的影象和G生成的影象,此時D(G(Z)) = 0.5。
上述過程表示成如下公式:
公式說明:
- x表示真實的影象,z表示輸入的G網路噪聲,G(z)表示G網路生成的影象。
- D(x)表示真實輸入的概率,D(G(z))表示D網路判斷G生成的影象是否真實的概率;
- G的目的:D(G(z))是D網路判斷G生成的圖片是否真實的概率,G應該希望自己生成的圖片“越接近真實越好”。也就是說,G希望D(G(z))儘可能得大,這時V(D, G)會變小。因此我們看到式子的最前面的記號是min_G。
- D的目的:D的能力越強,D(x)應該越大,D(G(x))應該越小。這時V(D,G)會變大。因此式子對於D來說是求最大(max_D)。
論文中給出了利用隨機梯度下降法如何訓練網路D和G,如下圖:
先訓練D,利用梯度上升,使損失函式越大越好,再訓練G,利用梯度下降演算法,使損失函式越小越好。

3.Auto-encoder VAE 和GAN
auto-encoder(自編碼器)
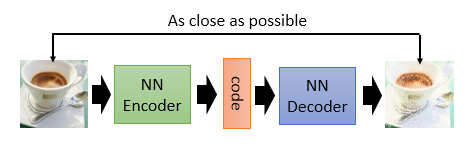
結構如下,訓練一個 encoder,把 input 轉換成 code,然後訓練一個 decoder,把 code 轉換成一個 image,然後計算得到的 image 和 input 之間的 MSE(mean square error),訓練完這個 model 之後,取出後半部分 NN Decoder,輸入一個隨機的 code,就能 generate 一個 image。
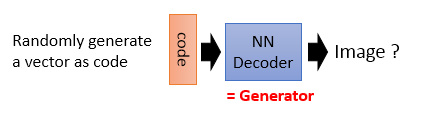
將Auto-encoder的後一部分拿出來,隨機輸入向量,即上述描述的Generator,但輸入向量怎麼設定?沒有什麼標準。
針對上述問題,提出了VAE,如下:
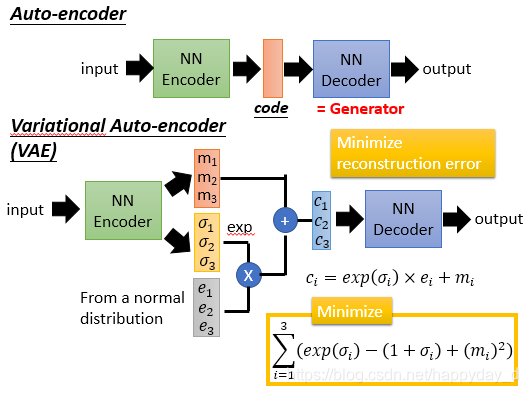
上述的兩個生成模型,其實有一個非常嚴重的弊端。比如 VAE,它生成的 image 是希望和 input 越相似越好,但是 model 是如何來衡量這個相似呢?model 會計算一個 loss,採用的大多是 MSE,即每一個畫素上的均方差。loss 小真的表示相似嘛?
如下圖,上述一行只相差一個畫素,得到的MSE最小,但結果並不是我們滿意的。

上述兩種生成網路之所以對產生影象不能達到滿意效果是由於網路只關注區域性資訊而未考慮全域性的資訊,若需要考慮全域性資訊需要更深的網路結構;
GAN網路的優缺點:
**Generator:**可以產生區域性影象,但不能顧及影象的不同部分之間的關係;
**Disciminator:**考慮的是全域性影象,但不能產生影象

4. 參考
http://www.sohu.com/a/121189842_465975
https://github.com/zhangqianhui/AdversarialNetsPapers