
Python資料結構與演算法概述
1 演算法初體驗
如果將最終寫好執行的程式比作戰場,我們程式設計師便是指揮作戰的將軍,而我們所寫的程式碼便是士兵和武器。
那麼資料結構和演算法是什麼?答曰:兵法!
我們可以不看兵法在戰場上肉搏,如此,可能會勝利,可能會失敗。即使勝利,可能也會付出巨大的代價。我們寫程式亦然:沒有看過資料結構和演算法,有時面對問題可能會沒有任何思路,不知如何下手去解決;大部分時間可能解決了問題,可是對程式執行的效率和開銷沒有意識,效能低下;有時會藉助別人開發的利器暫時解決了問題,可是遇到效能瓶頸的時候,又不知該如何進行鍼對性的優化。
如果我們常看兵法,便可做到胸有成竹,有時會事半功倍!同樣,如果我們常看資料結構與演算法,我們寫程式時也能遊刃有餘、明察秋毫,遇到問題時亦能入木三分、迎刃而解。
故,資料結構和演算法是一名程式開發人員的必備基本功,不是一朝一夕就能練成絕世高手的。冰凍三尺非一日之寒,需要我們平時不斷的主動去學習積累。
先來看一道題:
如果 a+b+c=1000,且 a^2+b^2=c^2(a,b,c 為自然數),如何求出所有a、b、c可能的組合?
第一次嘗試
import time start_time = time.time() # 注意是三重迴圈 for a in range(0, 1001): for b in range(0, 1001): for c in range(0, 1001): if a**2 + b**2 == c**2 and a+b+c == 1000: print("a, b, c: %d, %d, %d" % (a, b, c)) end_time = time.time() print("elapsed: %f" % (end_time - start_time)) print("complete!")
執行結果:
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 214.583347
complete!
注意執行的時間:214.583347秒
第二次嘗試
import time start_time = time.time() # 注意是兩重迴圈 for a in range(0, 1001): for b in range(0, 1001-a): c = 1000 - a - b if a**2 + b**2 == c**2: print("a, b, c: %d, %d, %d" % (a, b, c)) end_time = time.time() print("elapsed: %f" % (end_time - start_time)) print("complete!")
執行結果:
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 0.182897
complete!
注意執行的時間:0.182897秒
1.1 演算法的概念
演算法是計算機處理資訊的本質,因為計算機程式本質上是一個演算法來告訴計算機確切的步驟來執行一個指定的任務。一般地,當演算法在處理資訊時,會從輸入裝置或資料的儲存地址讀取資料,把結果寫入輸出裝置或某個儲存地址供以後再呼叫。
演算法是獨立存在的一種解決問題的方法和思想。
對於演算法而言,實現的語言並不重要,重要的是思想。
演算法可以有不同的語言描述實現版本(如C描述、C++描述、Python描述等),我們現在是在用Python語言進行描述實現。
1.1.1 演算法的五大特性
- 輸入: 演算法具有0個或多個輸入
- 輸出: 演算法至少有1個或多個輸出
- 有窮性: 演算法在有限的步驟之後會自動結束而不會無限迴圈,並且每一個步驟可以在可接受的時間內完成
- 確定性:演算法中的每一步都有確定的含義,不會出現二義性
- 可行性:演算法的每一步都是可行的,也就是說每一步都能夠執行有限的次數完成
1.2 演算法效率衡量
1.2.1 執行時間反應演算法效率
對於同一問題,我們給出了兩種解決演算法,在兩種演算法的實現中,我們對程式執行的時間進行了測算,發現兩段程式執行的時間相差懸殊(214.583347秒相比於0.182897秒),由此我們可以得出結論:實現演算法程式的執行時間可以反應出演算法的效率,即演算法的優劣。
1.2.2 單靠時間值絕對可信嗎?
假設我們將第二次嘗試的演算法程式執行在一臺配置古老效能低下的計算機中,情況會如何?很可能執行的時間並不會比在我們的電腦中執行演算法一的214.583347秒快多少。
單純依靠執行的時間來比較演算法的優劣並不一定是客觀準確的!
程式的執行離不開計算機環境(包括硬體和作業系統),這些客觀原因會影響程式執行的速度並反應在程式的執行時間上。那麼如何才能客觀的評判一個演算法的優劣呢?
1.2.3 時間複雜度與“大O記法”
我們假定計算機執行演算法每一個基本操作的時間是固定的一個時間單位,那麼有多少個基本操作就代表會花費多少時間單位。算然對於不同的機器環境而言,確切的單位時間是不同的,但是對於演算法進行多少個基本操作(即花費多少時間單位)在規模數量級上卻是相同的,由此可以忽略機器環境的影響而客觀的反應演算法的時間效率。
對於演算法的時間效率,我們可以用“大O記法”來表示。
“大O記法”:對於單調的整數函式f,如果存在一個整數函式g和實常數c>0,使得對於充分大的n總有f(n)<=c*g(n),就說函式g是f的一個漸近函式(忽略常數),記為f(n)=O(g(n))。也就是說,在趨向無窮的極限意義下,函式f的增長速度受到函式g的約束,亦即函式f與函式g的特徵相似。
時間複雜度:假設存在函式g,使得演算法A處理規模為n的問題示例所用時間為T(n)=O(g(n)),則稱O(g(n))為演算法A的漸近時間複雜度,簡稱時間複雜度,記為T(n)
1.2.4 如何理解“大O記法”
對於演算法進行特別具體的細緻分析雖然很好,但在實踐中的實際價值有限。對於演算法的時間性質和空間性質,最重要的是其數量級和趨勢,這些是分析演算法效率的主要部分。而計量演算法基本運算元量的規模函式中那些常量因子可以忽略不計。例如,可以認為3n2和100n2屬於同一個量級,如果兩個演算法處理同樣規模例項的代價分別為這兩個函式,就認為它們的效率“差不多”,都為n2級。
1.2.5 最壞時間複雜度
分析演算法時,存在幾種可能的考慮:
- 演算法完成工作最少需要多少基本操作,即最優時間複雜度
- 演算法完成工作最多需要多少基本操作,即最壞時間複雜度
- 演算法完成工作平均需要多少基本操作,即平均時間複雜度
對於最優時間複雜度,其價值不大,因為它沒有提供什麼有用資訊,其反映的只是最樂觀最理想的情況,沒有參考價值。
對於最壞時間複雜度,提供了一種保證,表明演算法在此種程度的基本操作中一定能完成工作。
對於平均時間複雜度,是對演算法的一個全面評價,因此它完整全面的反映了這個演算法的性質。但另一方面,這種衡量並沒有保證,不是每個計算都能在這個基本操作內完成。而且,對於平均情況的計算,也會因為應用演算法的例項分佈可能並不均勻而難以計算。
因此,我們主要關注演算法的最壞情況,亦即最壞時間複雜度。
1.2.6 時間複雜度的幾條基本計算規則
- 基本操作,即只有常數項,認為其時間複雜度為O(1)
- 順序結構,時間複雜度按加法進行計算
- 迴圈結構,時間複雜度按乘法進行計算
- 分支結構,時間複雜度取最大值
- 判斷一個演算法的效率時,往往只需要關注運算元量的最高次項,其它次要項和常數項可以忽略
- 在沒有特殊說明時,我們所分析的演算法的時間複雜度都是指最壞時間複雜度
1.2.7 常見時間複雜度
| 執行次數函式舉例 | 階 | 非正式術語 |
|---|---|---|
| 12 | O(1) | 常數階 |
| 2n+3 | O(n) | 線性階 |
| 3n2+2n+1 | O(n2) | 平方階 |
| 5log2n+20 | O(logn) | 對數階 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn階 |
| 6n3+2n2+3n+4 | O(n3) | 立方階 |
| 2n | O(2n) | 指數階 |
注意,經常將log2n(以2為底的對數)簡寫成logn
常見時間複雜度之間的關係

所消耗的時間從小到大
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
1.3 Python內建型別效能分析
1.3.1 timeit模組
timeit模組可以用來測試一小段Python程式碼的執行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是測量小段程式碼執行速度的類。
stmt引數是要測試的程式碼語句(statment);
setup引數是執行程式碼時需要的設定;
timer引數是一個定時器函式,與平臺有關。
timeit.Timer.timeit(number=1000000)
Timer類中測試語句執行速度的物件方法。number引數是測試程式碼時的測試次數,預設為1000000次。方法返回執行程式碼的平均耗時,一個float型別的秒數。
1.3.2 list的操作測試
def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000))
from timeit import Timer
t1 = Timer("test1()", "from __main__ import test1")
print("concat ",t1.timeit(number=1000), "seconds")
t2 = Timer("test2()", "from __main__ import test2")
print("append ",t2.timeit(number=1000), "seconds")
t3 = Timer("test3()", "from __main__ import test3")
print("comprehension ",t3.timeit(number=1000), "seconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list range ",t4.timeit(number=1000), "seconds")
# ('concat ', 1.7890608310699463, 'seconds')
# ('append ', 0.13796091079711914, 'seconds')
# ('comprehension ', 0.05671119689941406, 'seconds')
# ('list range ', 0.014147043228149414, 'seconds')
pop操作測試
x = range(2000000)
pop_zero = Timer("x.pop(0)","from __main__ import x")
print("pop_zero ",pop_zero.timeit(number=1000), "seconds")
x = range(2000000)
pop_end = Timer("x.pop()","from __main__ import x")
print("pop_end ",pop_end.timeit(number=1000), "seconds")
# ('pop_zero ', 1.9101738929748535, 'seconds')
# ('pop_end ', 0.00023603439331054688, 'seconds')
測試pop操作:從結果可以看出,pop最後一個元素的效率遠遠高於pop第一個元素
可以自行嘗試下list的append(value)和insert(0,value),即一個後面插入和一個前面插入???
1.3.3 list內建操作的時間複雜度

1.3.4 dict內建操作的時間複雜度

1.4 資料結構
我們如何用Python中的型別來儲存一個班的學生資訊? 如果想要快速的通過學生姓名獲取其資訊呢?
實際上當我們在思考這個問題的時候,我們已經用到了資料結構。列表和字典都可以儲存一個班的學生資訊,但是想要在列表中獲取一名同學的資訊時,就要遍歷這個列表,其時間複雜度為O(n),而使用字典儲存時,可將學生姓名作為字典的鍵,學生資訊作為值,進而查詢時不需要遍歷便可快速獲取到學生資訊,其時間複雜度為O(1)。
我們為了解決問題,需要將資料儲存下來,然後根據資料的儲存方式來設計演算法實現進行處理,那麼資料的儲存方式不同就會導致需要不同的演算法進行處理。我們希望演算法解決問題的效率越快越好,於是我們就需要考慮資料究竟如何儲存的問題,這就是資料結構。
在上面的問題中我們可以選擇Python中的列表或字典來儲存學生資訊。列表和字典就是Python內建幫我們封裝好的兩種資料結構。
1.4.1 概念
資料是一個抽象的概念,將其進行分類後得到程式設計語言中的基本型別。如:int,float,char等。資料元素之間不是獨立的,存在特定的關係,這些關係便是結構。資料結構指資料物件中資料元素之間的關係。
Python給我們提供了很多現成的資料結構型別,這些系統自己定義好的,不需要我們自己去定義的資料結構叫做Python的內建資料結構,比如列表、元組、字典。而有些資料組織方式,Python系統裡面沒有直接定義,需要我們自己去定義實現這些資料的組織方式,這些資料組織方式稱之為Python的擴充套件資料結構,比如棧,佇列等。
1.4.2 演算法與資料結構的區別
資料結構只是靜態的描述了資料元素之間的關係。
高效的程式需要在資料結構的基礎上設計和選擇演算法。
程式 = 資料結構 + 演算法
總結:演算法是為了解決實際問題而設計的,資料結構是演算法需要處理的問題載體
1.4.3 抽象資料型別(Abstract Data Type)
抽象資料型別(ADT)的含義是指一個數學模型以及定義在此數學模型上的一組操作。即把資料型別和資料型別上的運算捆在一起,進行封裝。引入抽象資料型別的目的是把資料型別的表示和資料型別上運算的實現與這些資料型別和運算在程式中的引用隔開,使它們相互獨立。
最常用的資料運算有五種:
- 插入
- 刪除
- 修改
- 查詢
- 排序
2 順序表
在程式中,經常需要將一組(通常是同為某個型別的)資料元素作為整體管理和使用,需要建立這種元素組,用變數記錄它們,傳進傳出函式等。一組資料中包含的元素個數可能發生變化(可以增加或刪除元素)。
對於這種需求,最簡單的解決方案便是將這樣一組元素看成一個序列,用元素在序列裡的位置和順序,表示實際應用中的某種有意義的資訊,或者表示資料之間的某種關係。
這樣的一組序列元素的組織形式,我們可以將其抽象為線性表。一個線性表是某類元素的一個集合,還記錄著元素之間的一種順序關係。線性表是最基本的資料結構之一,在實際程式中應用非常廣泛,它還經常被用作更復雜的資料結構的實現基礎。
根據線性表的實際儲存方式,分為兩種實現模型:
- 順序表,將元素順序地存放在一塊連續的儲存區裡,元素間的順序關係由它們的儲存順序自然表示。
- 連結串列,將元素存放在通過連結構造起來的一系列儲存塊中。
2.1 順序表的基本形式

圖a表示的是順序表的基本形式,資料元素本身連續儲存,每個元素所佔的儲存單元大小固定相同,元素的下標是其邏輯地址,而元素儲存的實體地址(實際記憶體地址)可以通過儲存區的起始地址Loc (e0)加上邏輯地址(第i個元素)與儲存單元大小(c)的乘積計算而得,即:
Loc(ei) = Loc(e0) + c*i
故,訪問指定元素時無需從頭遍歷,通過計算便可獲得對應地址,其時間複雜度為O(1)。
如果元素的大小不統一,則須採用圖b的元素外接的形式,將實際資料元素另行儲存,而順序表中各單元位置儲存對應元素的地址資訊(即連結)。由於每個連結所需的儲存量相同,通過上述公式,可以計算出元素連結的儲存位置,而後順著連結找到實際儲存的資料元素。注意,圖b中的c不再是資料元素的大小,而是儲存一個連結地址所需的儲存量,這個量通常很小。
圖b這樣的順序表也被稱為對實際資料的索引,這是最簡單的索引結構。
2.2 順序表的結構與實現
2.2.1 順序表的結構


一個順序表的完整資訊包括兩部分,一部分是表中的元素集合,另一部分是為實現正確操作而需記錄的資訊,即有關表的整體情況的資訊,這部分資訊主要包括元素儲存區的容量和當前表中已有的元素個數兩項。
2.2.2 順序表的兩種基本實現方式

圖a為一體式結構,儲存表資訊的單元與元素儲存區以連續的方式安排在一塊儲存區裡,兩部分資料的整體形成一個完整的順序表物件。
一體式結構整體性強,易於管理。但是由於資料元素儲存區域是表物件的一部分,順序表建立後,元素儲存區就固定了。
圖b為分離式結構,表物件裡只儲存與整個表有關的資訊(即容量和元素個數),實際資料元素存放在另一個獨立的元素儲存區裡,通過連結與基本表物件關聯。
2.2.3 元素儲存區替換
一體式結構由於順序表資訊區與資料區連續儲存在一起,所以若想更換資料區,則只能整體搬遷,即整個順序表物件(指儲存順序表的結構資訊的區域)改變了。
分離式結構若想更換資料區,只需將表資訊區中的資料區連結地址更新即可,而該順序表物件不變。
2.2.4 元素儲存區擴充
採用分離式結構的順序表,若將資料區更換為儲存空間更大的區域,則可以在不改變表物件的前提下對其資料儲存區進行了擴充,所有使用這個表的地方都不必修改。只要程式的執行環境(計算機系統)還有空閒儲存,這種表結構就不會因為滿了而導致操作無法進行。人們把採用這種技術實現的順序表稱為動態順序表,因為其容量可以在使用中動態變化。
擴充的兩種策略
-
每次擴充增加固定數目的儲存位置,如每次擴充增加10個元素位置,這種策略可稱為線性增長。
特點:節省空間,但是擴充操作頻繁,操作次數多。
-
每次擴充容量加倍,如每次擴充增加一倍儲存空間。
特點:減少了擴充操作的執行次數,但可能會浪費空間資源。以空間換時間,推薦的方式。
2.3 順序表的操作
2.3.1 增加元素
如圖所示,為順序表增加新元素111的三種方式

a. 尾端加入元素,時間複雜度為O(1)
b. 非保序的加入元素(不常見),時間複雜度為O(1)
c. 保序的元素加入,時間複雜度為O(n)
2.3.2 刪除元素

a. 刪除表尾元素,時間複雜度為O(1)
b. 非保序的元素刪除(不常見),時間複雜度為O(1)
c. 保序的元素刪除,時間複雜度為O(n)
2.4 Python中的順序表
Python中的list和tuple兩種型別採用了順序表的實現技術,具有前面討論的順序表的所有性質。
tuple是不可變型別,即不變的順序表,因此不支援改變其內部狀態的任何操作,而其他方面,則與list的性質類似。
2.4.1 list的基本實現技術
Python標準型別list就是一種元素個數可變的線性表,可以加入和刪除元素,並在各種操作中維持已有元素的順序(即保序),而且還具有以下行為特徵:
-
基於下標(位置)的高效元素訪問和更新,時間複雜度應該是O(1);
為滿足該特徵,應該採用順序表技術,表中元素儲存在一塊連續的儲存區中。
-
允許任意加入元素,而且在不斷加入元素的過程中,表物件的標識(函式id得到的值)不變。
為滿足該特徵,就必須能更換元素儲存區,並且為保證更換儲存區時list物件的標識id不變,只能採用分離式實現技術。
在Python的官方實現中,list就是一種採用分離式技術實現的動態順序表。這就是為什麼用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方實現中,list實現採用瞭如下的策略:在建立空表(或者很小的表)時,系統分配一塊能容納8個元素的儲存區;在執行插入操作(insert或append)時,如果元素儲存區滿就換一塊4倍大的儲存區。但如果此時的表已經很大(目前的閥值為50000),則改變策略,採用加一倍的方法。引入這種改變策略的方式,是為了避免出現過多空閒的儲存位置。
3 連結串列
為什麼需要連結串列
順序表的構建需要預先知道資料大小來申請連續的儲存空間,而在進行擴充時又需要進行資料的搬遷,所以使用起來並不是很靈活。
連結串列結構可以充分利用計算機記憶體空間,實現靈活的記憶體動態管理。
3.1 連結串列的定義
連結串列(Linked list)是一種常見的基礎資料結構,是一種線性表,但是不像順序表一樣連續儲存資料,而是在每一個節點(資料儲存單元)裡存放下一個節點的位置資訊(即地址)。

3.2 單向連結串列
單向連結串列也叫單鏈表,是連結串列中最簡單的一種形式,它的每個節點包含兩個域,一個資訊域(元素域)和一個連結域。這個連結指向連結串列中的下一個節點,而最後一個節點的連結域則指向一個空值。

- 表元素域elem用來存放具體的資料。
- 連結域next用來存放下一個節點的位置(python中的標識)
- 變數p指向連結串列的頭節點(首節點)的位置,從p出發能找到表中的任意節點。
3.2.1 節點實現
class SingleNode(object):
"""單鏈表的結點"""
def __init__(self,item):
# _item存放資料元素
self.item = item
# _next是下一個節點的標識
self.next = None
3.2.2 單鏈表的操作
- is_empty() 連結串列是否為空
- length() 連結串列長度
- travel() 遍歷整個連結串列
- add(item) 連結串列頭部新增元素
- append(item) 連結串列尾部新增元素
- insert(pos, item) 指定位置新增元素
- remove(item) 刪除節點
- search(item) 查詢節點是否存在
3.2.3 單鏈表的實現
class SingleLinkList(object):
"""單鏈表"""
def __init__(self):
self._head = None
def is_empty(self):
"""判斷連結串列是否為空"""
return self._head == None
def length(self):
"""連結串列長度"""
# cur初始時指向頭節點
cur = self._head
count = 0
# 尾節點指向None,當未到達尾部時
while cur != None:
count += 1
# 將cur後移一個節點
cur = cur.next
return count
def travel(self):
"""遍歷連結串列"""
cur = self._head
while cur != None:
print cur.item,
cur = cur.next
print ""
頭部新增元素

def add(self, item):
"""頭部新增元素"""
# 先建立一個儲存item值的節點
node = SingleNode(item)
# 將新節點的連結域next指向頭節點,即_head指向的位置
node.next = self._head
# 將連結串列的頭_head指向新節點
self._head = node
尾部新增元素
def append(self, item):
"""尾部新增元素"""
node = SingleNode(item)
# 先判斷連結串列是否為空,若是空連結串列,則將_head指向新節點
if self.is_empty():
self._head = node
# 若不為空,則找到尾部,將尾節點的next指向新節點
else:
cur = self._head
while cur.next != None:
cur = cur.next
cur.next = node
指定位置新增元素

def insert(self, pos, item):
"""指定位置新增元素"""
# 若指定位置pos為第一個元素之前,則執行頭部插入
if pos <= 0:
self.add(item)
# 若指定位置超過連結串列尾部,則執行尾部插入
elif pos > (self.length()-1):
self.append(item)
# 找到指定位置
else:
node = SingleNode(item)
count = 0
# pre用來指向指定位置pos的前一個位置pos-1,初始從頭節點開始移動到指定位置
pre = self._head
while count < (pos-1):
count += 1
pre = pre.next
# 先將新節點node的next指向插入位置的節點
node.next = pre.next
# 將插入位置的前一個節點的next指向新節點
pre.next = node
刪除節點

def remove(self,item):
"""刪除節點"""
cur = self._head
pre = None
while cur != None:
# 找到了指定元素
if cur.item == item:
# 如果第一個就是刪除的節點
if not pre:
# 將頭指標指向頭節點的後一個節點
self._head = cur.next
else:
# 將刪除位置前一個節點的next指向刪除位置的後一個節點
pre.next = cur.next
break
else:
# 繼續按連結串列後移節點
pre = cur
cur = cur.next
查詢節點是否存在
def search(self,item):
"""連結串列查詢節點是否存在,並返回True或者False"""
cur = self._head
while cur != None:
if cur.item == item:
return True
cur = cur.next
return False
測試
if __name__ == "__main__":
ll = SingleLinkList()
ll.add(1)
ll.add(2)
ll.append(3)
ll.insert(2, 4)
print "length:",ll.length()
ll.travel()
print ll.search(3)
print ll.search(5)
ll.remove(1)
print "length:",ll.length()
ll.travel()
3.2.4 連結串列與順序表的對比
連結串列失去了順序表隨機讀取的優點,同時連結串列由於增加了結點的指標域,空間開銷比較大,但對儲存空間的使用要相對靈活。
連結串列與順序表的各種操作複雜度如下所示:
| 操作 | 連結串列 | 順序表 |
|---|---|---|
| 訪問元素 | O(n) | O(1) |
| 在頭部插入/刪除 | O(1) | O(n) |
| 在尾部插入/刪除 | O(n) | O(1) |
| 在中間插入/刪除 | O(n) | O(n) |
注意雖然表面看起來複雜度都是 O(n),但是連結串列和順序表在插入和刪除時進行的是完全不同的操作。連結串列的主要耗時操作是遍歷查詢,刪除和插入操作本身的複雜度是O(1)。順序表查詢很快,主要耗時的操作是拷貝覆蓋。因為除了目標元素在尾部的特殊情況,順序表進行插入和刪除時需要對操作點之後的所有元素進行前後移位操作,只能通過拷貝和覆蓋的方法進行。
3.3 單向迴圈連結串列
單鏈表的一個變形是單向迴圈連結串列,連結串列中最後一個節點的next域不再為None,而是指向連結串列的頭節點。

3.3.1 操作
- is_empty() 判斷連結串列是否為空
- length() 返回連結串列的長度
- travel() 遍歷
- add(item) 在頭部新增一個節點
- append(item) 在尾部新增一個節點
- insert(pos, item) 在指定位置pos新增節點
- remove(item) 刪除一個節點
- search(item) 查詢節點是否存在
3.3.2 實現
class Node(object):
"""節點"""
def __init__(self, item):
self.item = item
self.next = None
class SinCycLinkedlist(object):
"""單向迴圈連結串列"""
def __init__(self):
self._head = None
def is_empty(self):
"""判斷連結串列是否為空"""
return self._head == None
def length(self):
"""返回連結串列的長度"""
# 如果連結串列為空,返回長度0
if self.is_empty():
return 0
count = 1
cur = self._head
while cur.next != self._head:
count += 1
cur = cur.next
return count
def travel(self):
"""遍歷連結串列"""
if self.is_empty():
return
cur = self._head
print cur.item,
while cur.next != self._head:
cur = cur.next
print cur.item,
print ""
def add(self, item):
"""頭部新增節點"""
node = Node(item)
if self.is_empty():
self._head = node
node.next = self._head
else:
#新增的節點指向_head
node.next = self._head
# 移到連結串列尾部,將尾部節點的next指向node
cur = self._head
while cur.next != self._head:
cur = cur.next
cur.next = node
#_head指向新增node的
self._head = node
def append(self, item):
"""尾部新增節點"""
node = Node(item)
if self.is_empty():
self._head = node
node.next = self._head
else:
# 移到連結串列尾部
cur = self._head
while cur.next != self._head:
cur = cur.next
# 將尾節點指向node
cur.next = node
# 將node指向頭節點_head
node.next = self._head
def insert(self, pos, item):
"""在指定位置新增節點"""
if pos <= 0:
self.add(item)
elif pos > (self.length()-1):
self.append(item)
else:
node = Node(item)
cur = self._head
count = 0
# 移動到指定位置的前一個位置
while count < (pos-1):
count += 1
cur = cur.next
node.next = cur.next
cur.next = node
def remove(self, item):
"""刪除一個節點"""
# 若連結串列為空,則直接返回
if self.is_empty():
return
# 將cur指向頭節點
cur = self._head
pre = None
# 若頭節點的元素就是要查詢的元素item
if cur.item == item:
# 如果連結串列不止一個節點
if cur.next != self._head:
# 先找到尾節點,將尾節點的next指向第二個節點
while cur.next != self._head:
cur = cur.next
# cur指向了尾節點
cur.next = self._head.next
self._head = self._head.next
else:
# 連結串列只有一個節點
self._head = None
else:
pre = self._head
# 第一個節點不是要刪除的
while cur.next != self._head:
# 找到了要刪除的元素
if cur.item == item:
# 刪除
pre.next = cur.next
return
else:
pre = cur
cur = cur.next
# cur 指向尾節點
if cur.item == item:
# 尾部刪除
pre.next = cur.next
def search(self, item):
"""查詢節點是否存在"""
if self.is_empty():
return False
cur = self._head
if cur.item == item:
return True
while cur.next != self._head:
cur = cur.next
if cur.item == item:
return True
return False
if __name__ == "__main__":
ll = SinCycLinkedlist()
ll.add(1)
ll.add(2)
ll.append(3)
ll.insert(2, 4)
ll.insert(4, 5)
ll.insert(0, 6)
print "length:",ll.length()
ll.travel()
print ll.search(3)
print ll.search(7)
ll.remove(1)
print "length:",ll.length()
ll.travel()3.4 雙向連結串列
一種更復雜的連結串列是“雙向連結串列”或“雙面連結串列”。每個節點有兩個連結:一個指向前一個節點,當此節點為第一個節點時,指向空值;而另一個指向下一個節點,當此節點為最後一個節點時,指向空值。

3.4.1 操作
- is_empty() 連結串列是否為空
- length() 連結串列長度
- travel() 遍歷連結串列
- add(item) 連結串列頭部新增
- append(item) 連結串列尾部新增
- insert(pos, item) 指定位置新增
- remove(item) 刪除節點
- search(item) 查詢節點是否存在
3.4.2 實現
class Node(object):
"""雙向連結串列節點"""
def __init__(self, item):
self.item = item
self.next = None
self.prev = None
class DLinkList(object):
"""雙向連結串列"""
def __init__(self):
self._head = None
def is_empty(self):
"""判斷連結串列是否為空"""
return self._head == None
def length(self):
"""返回連結串列的長度"""
cur = self._head
count = 0
while cur != None:
count += 1
cur = cur.next
return count
def travel(self):
"""遍歷連結串列"""
cur = self._head
while cur != None:
print cur.item,
cur = cur.next
print ""
def add(self, item):
"""頭部插入元素"""
node = Node(item)
if self.is_empty():
# 如果是空連結串列,將_head指向node
self._head = node
else:
# 將node的next指向_head的頭節點
node.next = self._head
# 將_head的頭節點的prev指向node
self._head.prev = node
# 將_head 指向node
self._head = node
def append(self, item):
"""尾部插入元素"""
node = Node(item)
if self.is_empty():
# 如果是空連結串列,將_head指向node
self._head = node
else:
# 移動到連結串列尾部
cur = self._head
while cur.next != None:
cur = cur.next
# 將尾節點cur的next指向node
cur.next = node
# 將node的prev指向cur
node.prev = cur
def search(self, item):
"""查詢元素是否存在"""
cur = self._head
while cur != None:
if cur.item == item:
return True
cur = cur.next
return False
指定位置插入節點

def insert(self, pos, item):
"""在指定位置新增節點"""
if pos <= 0:
self.add(item)
elif pos > (self.length()-1):
self.append(item)
else:
node = Node(item)
cur = self._head
count = 0
# 移動到指定位置的前一個位置
while count < (pos-1):
count += 1
cur = cur.next
# 將node的prev指向cur
node.prev = cur
# 將node的next指向cur的下一個節點
node.next = cur.next
# 將cur的下一個節點的prev指向node
cur.next.prev = node
# 將cur的next指向node
cur.next = node
刪除元素
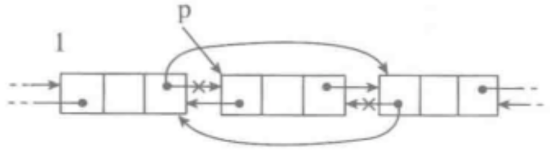
def remove(self, item):
"""刪除元素"""
if self.is_empty():
return
else:
cur = self._head
if cur.item == item:
# 如果首節點的元素即是要刪除的元素
if cur.next == None:
# 如果連結串列只有這一個節點
self._head = None
else:
# 將第二個節點的prev設定為None
cur.next.prev = None
# 將_head指向第二個節點
self._head = cur.next
return
while cur != None:
if cur.item == item:
# 將cur的前一個節點的next指向cur的後一個節點
cur.prev.next = cur.next
# 將cur的後一個節點的prev指向cur的前一個節點
cur.next.prev = cur.prev
break
cur = cur.next
測試
if __name__ == "__main__":
ll = DLinkList()
ll.add(1)
ll.add(2)
ll.append(3)
ll.insert(2, 4)
ll.insert(4, 5)
ll.insert(0, 6)
print "length:",ll.length()
ll.travel()
print ll.search(3)
print ll.search(4)
ll.remove(1)
print "length:",ll.length()
ll.travel()4 棧
棧(stack),有些地方稱為堆疊,是一種容器,可存入資料元素、訪問元素、刪除元素,它的特點在於只能允許在容器的一端(稱為棧頂端指標,英語:top)進行加入資料(英語:push)和輸出資料(英語:pop)的運算。沒有了位置概念,保證任何時候可以訪問、刪除的元素都是此前最後存入的那個元素,確定了一種預設的訪問順序。
由於棧資料結構只允許在一端進行操作,因而按照後進先出(LIFO, Last In First Out)的原理運作。
4.1 棧結構實現
棧可以用順序表實現,也可以用連結串列實現。
4.2 棧的操作
- Stack() 建立一個新的空棧
- push(item) 新增一個新的元素item到棧頂
- pop() 彈出棧頂元素
- peek() 返回棧頂元素
- is_empty() 判斷棧是否為空
- size() 返回棧的元素個數
class Stack(object):
"""棧"""
def __init__(self):
self.items = []
def is_empty(self):
"""判斷是否為空"""
return self.items == []
def push(self, item):
"""加入元素"""
self.items.append(item)
def pop(self):
"""彈出元素"""
return self.items.pop()
def peek(self):
"""返回棧頂元素"""
return self.items[len(self.items)-1]
def size(self):
"""返回棧的大小"""
return len(self.items)
if __name__ == "__main__":
stack = Stack()
stack.push("hello")
stack.push("world")
stack.push("itcast")
print stack.size()
print stack.peek()
print stack.pop()
print stack.pop()
print stack.pop()
5 佇列
佇列(queue)是隻允許在一端進行插入操作,而在另一端進行刪除操作的線性表。
佇列是一種先進先出的(First In First Out)的線性表,簡稱FIFO。允許插入的一端為隊尾,允許刪除的一端為隊頭。佇列不允許在中間部位進行操作!假設佇列是q=(a1,a2,……,an),那麼a1就是隊頭元素,而an是隊尾元素。這樣我們就可以刪除時,總是從a1開始,而插入時,總是在佇列最後。這也比較符合我們通常生活中的習慣,排在第一個的優先出列,最後來的當然排在隊伍最後。

5.1 佇列的實現
同棧一樣,佇列也可以用順序表或者連結串列實現。
5.1.1 操作
- Queue() 建立一個空的佇列
- enqueue(item) 往佇列中新增一個item元素
- dequeue() 從佇列頭部刪除一個元素
- is_empty() 判斷一個佇列是否為空
- size() 返回佇列的大小
class Queue(object):
"""佇列"""
def __init__(self):
self.items = []
def is_empty(self):
return self.items == []
def enqueue(self, item):
"""進佇列"""
self.items.insert(0,item)
def dequeue(self):
"""出佇列"""
return self.items.pop()
def size(self):
"""返回大小"""
return len(self.items)
if __name__ == "__main__":
q = Queue()
q.enqueue("hello")
q.enqueue("world")
q.enqueue("itcast")
print q.size()
print q.dequeue()
print q.dequeue()
print q.dequeue()5.3 雙端佇列
雙端佇列(deque,全名double-ended queue),是一種具有佇列和棧的性質的資料結構。
雙端佇列中的元素可以從兩端彈出,其限定插入和刪除操作在表的兩端進行。雙端佇列可以在佇列任意一端入隊和出隊。

5.3.1 操作
- Deque() 建立一個空的雙端佇列
- add_front(item) 從隊頭加入一個item元素
- add_rear(item) 從隊尾加入一個item元素
- remove_front() 從隊頭刪除一個item元素
- remove_rear() 從隊尾刪除一個item元素
- is_empty() 判斷雙端佇列是否為空
- size() 返回佇列的大小
5.3.2 實現
class Deque(object):
"""雙端佇列"""
def __init__(self):
self.items = []
def is_empty(self):
"""判斷佇列是否為空"""
return self.items == []
def add_front(self, item):
"""在隊頭新增元素"""
self.items.insert(0,item)
def add_rear(self, item):
"""在隊尾新增元素"""
self.items.append(item)
def remove_front(self):
"""從隊頭刪除元素"""
return self.items.pop(0)
def remove_rear(self):
"""從隊尾刪除元素"""
return self.items.pop()
def size(self):
"""返回佇列大小"""
return len(self.items)
if __name__ == "__main__":
deque = Deque()
deque.add_front(1)
deque.add_front(2)
deque.add_rear(3)
deque.add_rear(4)
print deque.size()
print deque.remove_front()
print deque.remove_front()
print deque.remove_rear()
print deque.remove_rear()6 樹與樹演算法
6.1 樹的概念
樹(英語:tree)是一種抽象資料型別(ADT)或是實作這種抽象資料型別的資料結構,用來模擬具有樹狀結構性質的資料集合。它是由n(n>=1)個有限節點組成一個具有層次關係的集合。把它叫做“樹”是因為它看起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的。它具有以下的特點:
- 每個節點有零個或多個子節點;
- 沒有父節點的節點稱為根節點;
- 每一個非根節點有且只有一個父節點;
- 除了根節點外,每個子節點可以分為多個不相交的子樹;
比如說:
6.2 樹的術語
- 節點的度:一個節點含有的子樹的個數稱為該節點的度;
- 樹的度:一棵樹中,最大的節點的度稱為樹的度;
- 葉節點或終端節點:度為零的節點;
- 父親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點;
- 孩子節點或子節點:一個節點含有的子樹的根節點稱為該節點的子節點;
- 兄弟節點:具有相同父節點的節點互稱為兄弟節點;
- 節點的層次:從根開始定義起,根為第1層,根的子節點為第2層,以此類推;
- 樹的高度或深度:樹中節點的最大層次;
- 堂兄弟節點:父節點在同一層的節點互為堂兄弟;
- 節點的祖先:從根到該節點所經分支上的所有節點;
- 子孫:以某節點為根的子樹中任一節點都稱為該節點的子孫。
- 森林:由m(m>=0)棵互不相交的樹的集合稱為森林;
6.3 樹的種類
- 無序樹:樹中任意節點的子節點之間沒有順序關係,這種樹稱為無序樹,也稱為自由樹;
- 有序樹:樹中任意節點的子節點之間有順序關係,這種樹稱為有序樹;
- 二叉樹:每個節點最多含有兩個子樹的樹稱為二叉樹;
- 完全二叉樹:對於一顆二叉樹,假設其深度為d(d>1)。除了第d層外,其它各層的節點數目均已達最大值,且第d層所有節點從左向右連續地緊密排列,這樣的二叉樹被稱為完全二叉樹,其中滿二叉樹的定義是所有葉節點都在最底層的完全二叉樹;
- 平衡二叉樹(AVL樹):當且僅當任何節點的兩棵子樹的高度差不大於1的二叉樹;
- 排序二叉樹(二叉查詢樹(英語:Binary Search Tree),也稱二叉搜尋樹、有序二叉樹);
- 霍夫曼樹(用於資訊編碼):帶權路徑最短的二叉樹稱為哈夫曼樹或最優二叉樹;
- B樹:一種對讀寫操作進行優化的自平衡的二叉查詢樹,能夠保持資料有序,擁有多餘兩個子樹。
- 二叉樹:每個節點最多含有兩個子樹的樹稱為二叉樹;
樹的儲存與表示
順序儲存:將資料結構儲存在固定的陣列中,然在遍歷速度上有一定的優勢,但因所佔空間比較大,是非主流二叉樹。二叉樹通常以鏈式儲存。

鏈式儲存:

由於對節點的個數無法掌握,常見樹的儲存表示都轉換成二叉樹進行處理,子節點個數最多為2
常見的一些樹的應用場景
1.xml,html等,那麼編寫這些東西的解析器的時候,不可避免用到樹 2.路由協議就是使用了樹的演算法 3.mysql資料庫索引 4.檔案系統的目錄結構 5.所以很多經典的AI演算法其實都是樹搜尋,此外機器學習中的decision tree也是樹結構

二叉樹
二叉樹的基本概念
二叉樹是每個節點最多有兩個子樹的樹結構。通常子樹被稱作“左子樹”(left subtree)和“右子樹”(right subtree)
二叉樹的性質(特性)
性質1: 在二叉樹的第i層上至多有2^(i-1)個結點(i>0)性質2: 深度為k的二叉樹至多有2^k - 1個結點(k>0)性質3: 對於任意一棵二叉樹,如果其葉結點數為N0,而度數為2的結點總數為N2,則N0=N2+1;性質4:具有n個結點的完全二叉樹的深度必為 log2(n+1)性質5:對完全二叉樹,若從上至下、從左至右編號,則編號為i 的結點,其左孩子編號必為2i,其右孩子編號必為2i+1;其雙親的編號必為i/2(i=1 時為根,除外)
(1)完全二叉樹——若設二叉樹的高度為h,除第 h 層外,其它各層 (1~h-1) 的結點數都達到最大個數,第h層有葉子結點,並且葉子結點都是從左到右依次排布,這就是完全二叉樹。

(2)滿二叉樹——除了葉結點外每一個結點都有左右子葉且葉子結點都處在最底層的二叉樹。
二叉樹的節點表示以及樹的建立
通過使用Node類中定義三個屬性,分別為elem本身的值,還有lchild左孩子和rchild右孩子
class Node(object):
"""節點類"""
def __init__(self, elem=-1, lchild=None, rchild=None):
self.elem = elem
self.lchild = lchild
self.rchild = rchild
樹的建立,建立一個樹的類,並給一個root根節點,一開始為空,隨後新增節點
class Tree(object):
"""樹類"""
def __init__(self, root=None):
self.root = root
def add(self, elem):
"""為樹新增節點"""
node = Node(elem)
#如果樹是空的,則對根節點賦值
if self.root == None:
self.root = node
else:
queue = []
queue.append(self.root)
#對已有的節點進行層次遍歷
while queue:
#彈出佇列的第一個元素
cur = queue.pop(0)
if cur.lchild == None:
cur.lchild = node
return
elif cur.rchild == None:
cur.rchild = node
return
else:
#如果左右子樹都不為空,加入佇列繼續判斷
queue.append(cur.lchild)
queue.append(cur.rchild)二叉樹的遍歷
樹的遍歷是樹的一種重要的運算。所謂遍歷是指對樹中所有結點的資訊的訪問,即依次對樹中每個結點訪問一次且僅訪問一次,我們把這種對所有節點的訪問稱為遍歷(traversal)。那麼樹的兩種重要的遍歷模式是深度優先遍歷和廣度優先遍歷,深度優先一般用遞迴,廣度優先一般用佇列。一般情況下能用遞迴實現的演算法大部分也能用堆疊來實現。
深度優先遍歷
對於一顆二叉樹,深度優先搜尋(Depth First Search)是沿著樹的深度遍歷樹的節點,儘可能深的搜尋樹的分支。 那麼深度遍歷有重要的三種方法。這三種方式常被用於訪問樹的節點,它們之間的不同在於訪問每個節點的次序不同。這三種遍歷分別叫做先序遍歷(preorder),中序遍歷(inorder)和後序遍歷(postorder)。我們來給出它們的詳細定義,然後舉例看看它們的應用。
- 先序遍歷 在先序遍歷中,我們先訪問根節點,然後遞迴使用先序遍歷訪問左子樹,再遞迴使用先序遍歷訪問右子樹
根節點->左子樹->右子樹
def preorder(self, root): """遞迴實現先序遍歷""" if root == None: return print root.elem self.preorder(root.lchild) self.preorder(root.rchild)
- 中序遍歷 在中序遍歷中,我們遞迴使用中序遍歷訪問左子樹,然後訪問根節點,最後再遞迴使用中序遍歷訪問右子樹
左子樹->根節點->右子樹
def inorder(self, root): """遞迴實現中序遍歷""" if root == None: return self.inorder(root.lchild) print root.elem self.inorder(root.rchild)
- 後序遍歷 在後序遍歷中,我們先遞迴使用後序遍歷訪問左子樹和右子樹,最後訪問根節點
左子樹->右子樹->根節點
def postorder(self, root): """遞迴實現後續遍歷""" if root == None: return self.postorder(root.lchild) self.postorder(root.rchild) print root.elem
課堂練習: 按照如圖樹的結構寫出三種遍歷的順序:
結果: 先序:a b c d e f g h 中序:b d c e a f h g 後序:d e c b h g f a思考:哪兩種遍歷方式能夠唯一的確定一顆樹???
廣度優先遍歷(層次遍歷)
從樹的root開始,從上到下從從左到右遍歷整個樹的節點
def breadth_travel(self, root):
"""利用佇列實現樹的層次遍歷"""
if root == None:
return
queue = []
queue.append(root)
while queue:
node = queue.pop(0)
print node.elem,
if node.lchild != None:
queue.append(node.lchild)
if node.rchild != None:
queue.append(node.rchild)