
如何用Flask和Redis維護代理池
我們在爬蟲時可能會遇到封IP的問題,那麼利用代理就可以進行IP的偽裝,然後進行爬蟲的請求。我們有時會需要非常多的ip,那麼維護一個代理池(代理的佇列,可以存入或取出),需要對整個池進行定期的檢查和更新,以此來保證代理的高質量(也就是代理的檢測和篩選),以免對爬蟲產生影響。 Redis主要給代理池提供一個佇列儲存。 Flask用來實現代理池的介面。
為什麼要用代理池?
許多網站有專門的反爬蟲措施,可能遇到封IP等問題。 網際網路上公開了大量免費代理,利用好資源。 通過定時的檢測維護同樣可以得到許多的可用代理。
代理池的要求
- 多站抓取,非同步檢測(非同步是為了提高檢測效率)
- 定時篩選,持續更新
- 提供介面,易於提取
代理池架構

代理池實現
download原始碼
以github一位大神的原始碼作為參考:https://github.com/germey/proxypool
分析一下如何實現一個代理池。
 我們可以先將原始碼download到本地,在pycharm中開啟:
我們可以先將原始碼download到本地,在pycharm中開啟:
 這是整個專案的結構,examples目錄下是示例,proxypool下是這個專案的一些指令碼,run是主程式的入口,setup用來安裝代理池。
這是整個專案的結構,examples目錄下是示例,proxypool下是這個專案的一些指令碼,run是主程式的入口,setup用來安裝代理池。
執行程式
執行這個程式時如果出現報錯可能是一些庫還未安裝造成的,根據提示,逐一安裝就好了,例如:
pip3 install aiohttp (這是一個非同步請求庫)
pip install fake-useragent
所需要的庫都已經安裝完畢後,就可以在Terminal介面使用命令:
來啟動程式了。

 在Redis資料庫中,可以看到生成了一個proxies佇列來儲存上面通過測試的代理。程式通過不停地進行定時檢測來新增可用的代理,直到到達了預定的上限。
在api.py這個檔案中,通過Flask庫建立了一個介面,使得我們可以從web獲得儲存到資料庫中的代理。
在Redis資料庫中,可以看到生成了一個proxies佇列來儲存上面通過測試的代理。程式通過不停地進行定時檢測來新增可用的代理,直到到達了預定的上限。
在api.py這個檔案中,通過Flask庫建立了一個介面,使得我們可以從web獲得儲存到資料庫中的代理。
 在瀏覽器中輸入http://localhost:5000,可以看到歡迎頁面:
在瀏覽器中輸入http://localhost:5000,可以看到歡迎頁面:
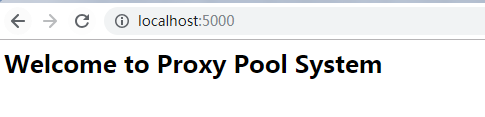 若在瀏覽器中輸入http://localhost:5000/get,就可以從資料庫中取得一個代理的地址了。點選重新整理的話,代理的地址會改變。
若在瀏覽器中輸入http://localhost:5000/get,就可以從資料庫中取得一個代理的地址了。點選重新整理的話,代理的地址會改變。
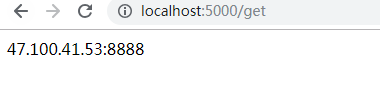 若在瀏覽器中輸入http://localhost:5000/count,就可以查詢資料庫中已經儲存的代理的數量。
若在瀏覽器中輸入http://localhost:5000/count,就可以查詢資料庫中已經儲存的代理的數量。

程式碼分析
那麼我們來看看程式碼是如何實現這個代理池的。
from proxypool.api import app
from proxypool.schedule import Schedule
def main():
s = Schedule()#呼叫了自己定義的一個排程器
s.run()#執行排程器
app.run()#執行介面
if __name__ == '__main__':
main()
排程器
程序1
valid_process = Process(target=Schedule.valid_proxy)
在Schedule這個類中,定義了valid_proxy這個方法。
conn = RedisClient()
方法中的這個語句,呼叫了RedisClient()方法,這個方法是在db.py中定義的,提供了佇列的一些API操作:
class RedisClient(object):#提供了佇列的一些API操作
def __init__(self, host=HOST, port=PORT):
if PASSWORD:
self._db = redis.Redis(host=host, port=port, password=PASSWORD)
else:
self._db = redis.Redis(host=host, port=port)
def get(self, count=1):
"""
get proxies from redis
"""
proxies = self._db.lrange("proxies", 0, count - 1)#從佇列左側拿出代理(舊的)
self._db.ltrim("proxies", count, -1)#從左側批量獲取
return proxies
def put(self, proxy):
"""
add proxy to right top
"""
self._db.rpush("proxies", proxy)#將代理插入到佇列右側(新的)
def pop(self):
"""
get proxy from right.
"""
try:
return self._db.rpop("proxies").decode('utf-8')#從右側取出新的代理
except:
raise PoolEmptyError
@property
def queue_len(self):#獲取佇列長度
"""
get length from queue.
"""
return self._db.llen("proxies")
def flush(self):#重新整理資料庫
"""
flush db
"""
self._db.flushall()
下面的一條語句
tester = ValidityTester()
ValidityTester是一個類,用來檢測代理是否可用。
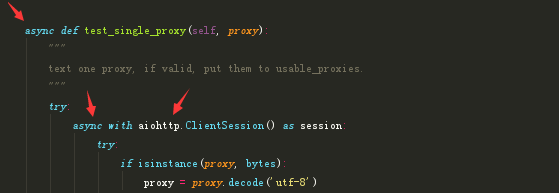 類中的這個方法通過呼叫了aiohttp這個庫來實現非同步檢測,具體邏輯如下注釋:
類中的這個方法通過呼叫了aiohttp這個庫來實現非同步檢測,具體邏輯如下注釋:
async def test_single_proxy(self, proxy):
"""
text one proxy, if valid, put them to usable_proxies.
"""
try:
async with aiohttp.ClientSession() as session:
try:
if isinstance(proxy, bytes):#判斷
proxy = proxy.decode('utf-8')#轉碼
real_proxy = 'http://' + proxy#設定代理
print('Testing', proxy)
async with session.get(self.test_api, proxy=real_proxy, timeout=get_proxy_timeout) as response:
if response.status == 200:#說明代理可以正常使用
self._conn.put(proxy)#將此代理加到佇列的右側
print('Valid proxy', proxy)
except (ProxyConnectionError, TimeoutError, ValueError):#否則不正常
print('Invalid proxy', proxy)
except (ServerDisconnectedError, ClientResponseError,ClientConnectorError) as s:
print(s)
pass
上面分析的兩條語句: conn = RedisClient() tester = ValidityTester() 都是在valid_proxy這個方法裡的,再看看這個方法接下來做了什麼事情:
while True:#不斷迴圈執行
print('Refreshing ip')
count = int(0.5 * conn.queue_len)#從佇列中取出一半長度的代理
if count == 0:
print('Waiting for adding')#如果佇列為空,等待新增新的代理
time.sleep(cycle)
continue
raw_proxies = conn.get(count)#從佇列左側取出conut數量的代理
tester.set_raw_proxies(raw_proxies)#設定引數
tester.test()#呼叫檢測方法
time.sleep(cycle)
以上就是第一個程序
valid_process = Process(target=Schedule.valid_proxy)
中所做的事情。
程序2
再看第二個程序:
check_process = Process(target=Schedule.check_pool)
這是從各大網站獲取代理,檢測,再將代理存入資料庫:
@staticmethod
def check_pool(lower_threshold=POOL_LOWER_THRESHOLD,
upper_threshold=POOL_UPPER_THRESHOLD,
cycle=POOL_LEN_CHECK_CYCLE):#限制代理池中代理的數量,以及檢查的週期
"""
If the number of proxies less than lower_threshold, add proxy
"""
conn = RedisClient()
adder = PoolAdder(upper_threshold)
while True:
if conn.queue_len < lower_threshold:
adder.add_to_queue()
time.sleep(cycle)
把代理新增到佇列中用到add_to_queue()方法:
def add_to_queue(self):
print('PoolAdder is working')
proxy_count = 0
while not self.is_over_threshold():
for callback_label in range(self._crawler.__CrawlFuncCount__):
callback = self._crawler.__CrawlFunc__[callback_label]
raw_proxies = self._crawler.get_raw_proxies(callback)
# test crawled proxies
self._tester.set_raw_proxies(raw_proxies)
self._tester.test()
proxy_count += len(raw_proxies)
if self.is_over_threshold():
print('IP is enough, waiting to be used')
break
if proxy_count == 0:
raise ResourceDepletionError
for callback_label in range(self._crawler.__CrawlFuncCount__):
callback = self._crawler.__CrawlFunc__[callback_label]
上面的兩個引數__CrawlFuncCount__、__CrawlFunc__是在getter.py的元類中定義的:
class ProxyMetaclass(type):
"""
元類,在FreeProxyGetter類中加入
__CrawlFunc__和__CrawlFuncCount__
兩個引數,分別表示爬蟲函式,和爬蟲函式的數量。
"""
def __new__(cls, name, bases, attrs):
count = 0
attrs['__CrawlFunc__'] = []#宣告屬性
for k, v in attrs.items():
if 'crawl_' in k:#如果方法是以'crawl_'開頭,那麼就新增到attrs中
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)
下面的class FreeProxyGetter(object, metaclass=ProxyMetaclass): 將元類指定為ProxyMetaclass,並且定義了許多crawl_開頭的方法,這些是根據獲取代理的目標網站不同而制定的不同的方法,如果有別的目標網站,也可以通過類似的格式定義好方法新增進去,這樣就保證了良好的擴充套件性。 關於元類的用法,可以查詢python的相關文件。
總結
上面簡單對程式碼進行了分析,作為對實現代理池的一些參考。
如果覺得這個程式寫得還不錯,詳細的使用方法可以參考專案的README.md:
 如果覺得程式還有許多可以改進的地方,那麼也可以自己修改。
如果覺得還有別的更好的實現思路,歡迎交流:)
如果覺得程式還有許多可以改進的地方,那麼也可以自己修改。
如果覺得還有別的更好的實現思路,歡迎交流:)