
對SSD的初步認識
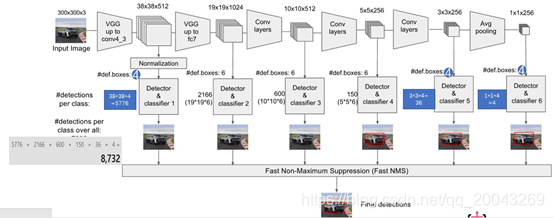
1、SSD網路結構

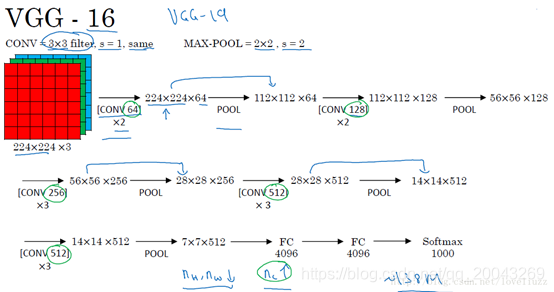
SSD採用VGG16的基礎網路結構,使用前面的前5層,然後利用astrous演算法將fc6和fc7層轉換成兩個卷積層,並且對conv4_3輸出做正則化處理。再額外增加3個卷積層,和一個average pool層。不同層次的feature map分別用於default box的偏移以及不同類別得分預測,最後通過NMS得到最終的檢測結果。不同卷積層的feature map大小變化比較大,能夠檢測出不同尺度下的物體,在不同的feature map進行卷積,可以達到多尺度的目的。
2.3、生成prior box
區別於default box,default box有4個引數,而prior box是從位置迴歸的feature map中生成的,它有8個引數,4個location維度+4個偏置(迴歸所需的引數)。從程式碼看,default box輸入重寫的Keras層生成prior box。
2.4、如何生成default box
按照不同的scale和ratio生成s個default box,s預設是6,對於conv4_3,s的值為4。
scale:假設使用m個不同層的feature map來做預測,論文中最低層的feature map的scale的值
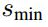
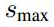 為0.9,其他層通過下面的公式計算得到
為0.9,其他層通過下面的公式計算得到
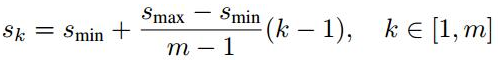 當前網路使用了6個feature map,即m=6。
ratio:使用ratio的值
當前網路使用了6個feature map,即m=6。
ratio:使用ratio的值 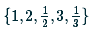 ,計算default box的寬度和高度,
,計算default box的寬度和高度, 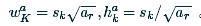 ,另外對ratio=1的情況,額外指定scale為
,另外對ratio=1的情況,額外指定scale為  ,即生成6個不同的default box。
default box中心:每個default box的中心位置設定成
,即生成6個不同的default box。
default box中心:每個default box的中心位置設定成 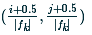 ,其中
,其中 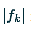 表示第k個特徵圖的大小,
表示第k個特徵圖的大小,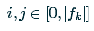 。
這些引數都是相對於原圖的引數,不是最終值。
。
這些引數都是相對於原圖的引數,不是最終值。
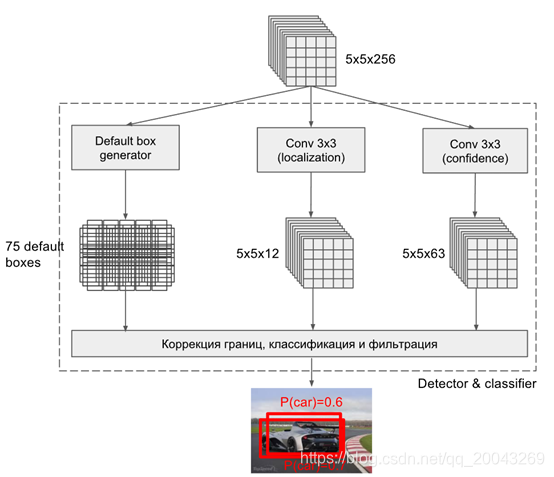
2.5、如何生成prior box 將原圖切割成feature_map_width*feature_map_height個小矩形格,比如原圖大小為300x300,feature map大小為5x5,那麼每個小格的尺寸為60x60。獲取每個小格的寬和高,獲取每個小格的起始座標。 首先,boxes_tensor=np.zeros((feature_map_height, feature_map_width, self.n_boxes, 4))建立一個四維矩陣,代表的是每個feature map的每個特徵點有n_boxes個prior box,而每個prior box有x,y,w,h四個引數來定義一個prior box。接下來是把prior box超出原圖邊界的修正下. 然後再建立一個variances_tensor,它和上面的boxes_tensor維度一樣,只不過它的值都為0加上variance.然後將variances_tensor和boxes_tensor做連線操作。所以生成的prior box 會變成 size= [feature_map_height,feature_map_width,n_boxes,8]。
2.6、轉換特徵矩陣 對【分類】步驟的結果reshape:[n_boxes_conv6_2n_classes,5,5]即[21x4,5,5])–>[-1,n_classes] 對【迴歸】步驟的結果reshape: [n_boxes_conv6_24,5,5] 即[4x4,5,5])–>[-1,4] 對【priorbox】步驟的結果reshape:[n_boxes_conv6_2*8,5,5]即[4x8,5,5])–>[-1,8]
2.7、連線
連線所有的分類,迴歸,prior box。從程式碼上來看,所有的分類走一條線,迴歸走一條線,生成prior box走一條線。迴歸和prior box所生成的結果是相互獨立的,而分類的結果之間是相互影響的,最後做一個softmax實現多分類。
3、非極大值抑制NMS
將所有框的得分排序,選中最高分及其對應的框
遍歷其餘的框,如果和當前最高分框的重疊面積(IOU)大於一定閾值,我們就將框刪除。
從未處理的框中繼續選一個得分最高的,重複上述過程。
4、損失函式
損失函式定義為位置誤差(locatization loss,loc)與置信度誤差(confidence loss, conf)的加權和:
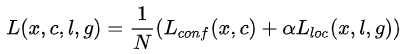
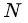
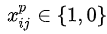
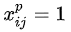
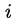
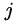
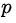
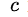
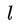
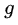
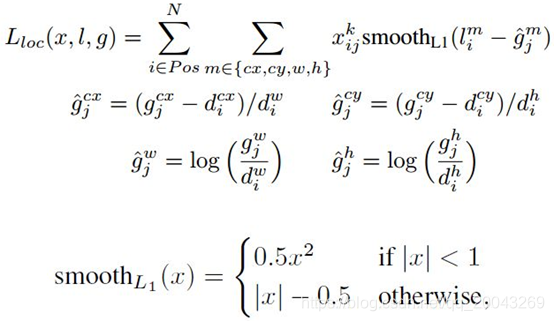
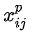
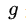
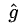
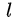
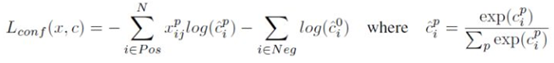
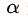
為什麼使用3x3的卷積核,設定步長=1:
