
【轉載】【機器學習】EM演算法詳細推導和講解
今天不太想學習,炒個冷飯,講講機器學習十大演算法裡有名的EM演算法,文章裡面有些個人理解,如有錯漏,還請讀者不吝賜教。
眾所周知,極大似然估計是一種應用很廣泛的引數估計方法。例如我手頭有一些東北人的身高的資料,又知道身高的概率模型是高斯分佈,那麼利用極大化似然函式的方法可以估計出高斯分佈的兩個引數,均值和方差。這個方法基本上所有概率課本上都會講,我這就不多說了,不清楚的請百度。
然而現在我面臨的是這種情況,我手上的資料是四川人和東北人的身高合集,然而對於其中具體的每一個數據,並沒有標定出它來自“東北人”還是“四川人”,我想如果把這個資料集的概率密度畫出來,大約是這個樣子:

好了不要吐槽了,能畫成這個樣子我已經很用心了= =
其實這個雙峰的概率密度函式是有模型的,稱作高斯混合模型(GMM),寫作:
![]()
話說往部落格上加公式真是費勁= =這模型很好理解,就是k個高斯模型加權組成,α是各高斯分佈的權重,Θ是引數。對GMM模型的引數估計,就要用EM演算法。更一般的講,EM演算法適用於帶有隱變數的概率模型的估計,什麼是隱變數呢?就是觀測不到的變數,對於上面四川人和東北人的例子,對每一個身高而言,它來自四川還是東北,就是一個隱變數。
為什麼要用EM,我們來具體考慮一下上面這個問題。如果使用極大似然估計——這是我們最開始最單純的想法,那麼我們需要極大化的似然函式應該是這個:

然而我們並不知道p(x;θ)的表示式,有同學說我知道啊,不就是上面那個混個高斯模型?不就是引數多一點麼。
仔細想想,GMM裡的θ可是由四川人和東北人兩部分組成喲,假如你要估計四川人的身高均值,直接用GMM做似然函式,會把四川人和東北人全考慮進去,顯然不合適。
另一個想法是考慮隱變數,如果我們已經知道哪些樣本來自四川,哪些樣本來自東北,那就好了。用Z=0或Z=1標記樣本來自哪個總體,則Z就是隱變數,需要最大化的似然函式就變為:
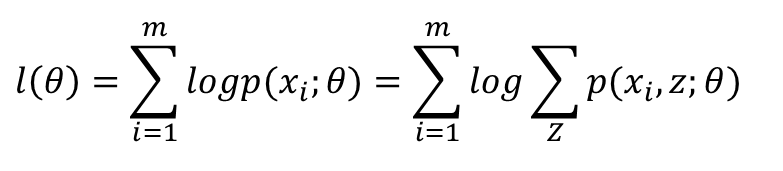
然而並沒有卵用,因為隱變數確實不知道。要估計一個樣本是來自四川還是東北,我們就要有模型引數,要估計模型引數,我們首先要知道一個樣本是來自四川或東北的可能性...
到底是雞生蛋,還是蛋生雞?
不鬧了,我們的方法是假設。首先假設一個模型引數θ,然後每個樣本來自四川/東北的概率p(zi)就能算出來了,p(xi,zi)=p(xi|zi)p(zi),而x|z=0服從四川人分佈,x|z=1服從東北人分佈,所以似然函式可以寫成含有θ的函式,極大化它我們可以得到一個新的θ。新的θ因為考慮了樣本來自哪個分佈,會比原來的更能反應資料規律。有了這個更好的θ我們再對每個樣本重新計算它來自四川和東北的概率,用更好的θ算出來的概率會更準確,有了更準確的資訊,我們可以繼續像上面一樣估計θ,自然而然這次得到的θ會比上一次更棒,如此蒸蒸日上,直到收斂(引數變動不明顯了),理論上,EM演算法就說完了。
然而事情並沒有這麼簡單,上面的思想理論上可行,實踐起來不成。主要是因為似然函式有“和的log”這一項,log裡面是一個和的形式,一求導這畫面不要太美,直接強來你要面對 “兩個正態分佈的概率密度函式相加”做分母,“兩個正態分佈分別求導再相加”做分子的分數形式。m個這玩意加起來令它等於0,要求出關於θ的解析解,你對自己的數學水平想的不要太高。
怎麼辦?先介紹一個不等式,叫Jensen不等式,是這樣說的:
X是一個隨機變數,f(X)是一個凸函式(二階導數大或等於0),那麼有:
![]()
當且僅當X是常數的時候等號成立
如果f(X)是凹函式,不等號反向
關於這個不等式,我既不打算證明,也不打算說明,希望你承認它正確就好。
半路殺出一個Jensen不等式,要用它解決上面的困境也是應有之義,不然說它做什麼。直接最大化似然函式做不到,那麼如果我們能找到似然函式的一個緊的下界一直優化它,並保證每次迭代能夠使總的似然函式一直增大,其實也是一樣的。怎麼說?畫個圖你就明白了:
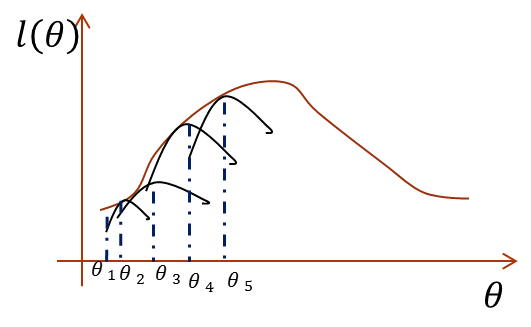
圖畫的不好,多見諒。橫座標是引數,縱座標是似然函式,首先我們初始化一個θ1,根據它求似然函式一個緊的下界,也就是圖中第一條黑短線,黑短線上的值雖然都小於似然函式的值,但至少有一點可以滿足等號(所以稱為緊下界),最大化小黑短線我們就hit到至少與似然函式剛好相等的位置,對應的橫座標就是我們的新的θ2,如此進行,只要保證隨著θ的更新,每次最大化的小黑短線值都比上次的更大,那麼演算法收斂,最後就能最大化到似然函式的極大值處。
構造這個小黑短線,就要靠Jensen不等式。注意我們這裡的log函式是個凹函式,所以我們使用的Jensen不等式的凹函式版本。根據Jensen函式,需要把log裡面的東西寫成一個數學期望的形式,注意到log裡的和是關於隱變數Z的和,於是自然而然,這個數學期望一定是和Z有關,如果設Q(z)是Z的分佈函式,那麼可以這樣構造:
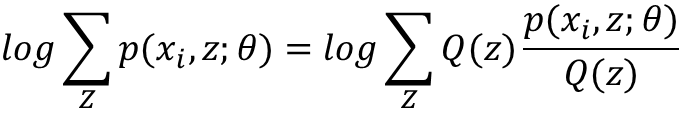
這幾句公式比較多,我不一一敲了,直接把我PPT裡的內容截圖過來:
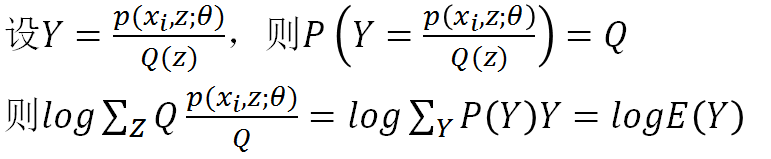
所以log裡其實構造了一個隨機變數Y,Y是Z的函式,Y取p/Q的值的概率是Q,這點說的很清楚了。
構造好數學期望,下一步根據Jensen不等式進行放縮:

有了這一步,我們看一下整個式子:

也就是說我們找到了似然函式的一個下界,那麼優化它是否就可以呢?不是的,上面說了必須保證這個下界是緊的,也就是至少有點能使等號成立。由Jensen不等式,等式成立的條件是隨機變數是常數,具體到這裡,就是:

又因為Q(z)是z的分佈函式,所以:
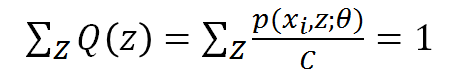
把C乘過去,可得C就是p(xi,z)對z求和,所以我們終於知道了:
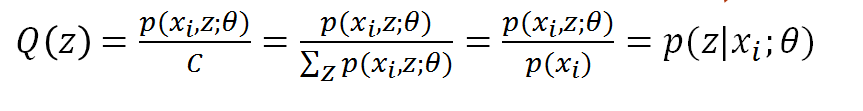
得到Q(z),大功告成,Q(z)就是p(zi|xi),或者寫成p(zi),都是一回事,代表第i個數據是來自zi的概率。
於是EM演算法出爐,它是這樣做的:
首先,初始化引數θ
(1)E-Step:根據引數θ計算每個樣本屬於zi的概率,即這個身高來自四川或東北的概率,這個概率就是Q
(2)M-Step:根據計算得到的Q,求出含有θ的似然函式的下界並最大化它,得到新的引數θ
重複(1)和(2)直到收斂,可以看到,從思想上來說,和最開始沒什麼兩樣,只不過直接最大化似然函式不好做,曲線救國而已。
至於為什麼這樣的迭代會保證似然函式單調不減,即EM演算法的收斂性證明,我就先不寫了,以後有時間再考慮補。需要額外說明的是,EM演算法在一般情況是收斂的,但是不保證收斂到全域性最優,即有可能進入區域性的最優。EM演算法在混合高斯模型,隱馬爾科夫模型中都有應用,是著名的資料探勘十大演算法之一。
就醬~有什麼錯漏和不同見解歡迎留言評論,我的推導和思路整理和網上的其他並不是完全相同,見仁見智吧~