
ML/DL補充(有圖版)

目錄 ML相關:偏差方差、先驗後驗、生成判別、流程、資訊理論、SVM、決策樹 DL相關:啟用函式、正則化、範數、optimizer、CNN、RNN、TCN、seq2seq about:mobilenet、CRNN、無人駕駛、cuda scatter:散件
ML相關
偏差Bias和方差Variance
偏差與方差分別是用於衡量一個模型泛化誤差的兩個方面,在監督學習中,模型的 泛化誤差可分解為偏差、方差與噪聲(Bias方)之和。 模型的偏差,指的是模型預測的期望值與真實值之間的差,用於描述模型的擬合能力 模型的方差,指的是模型預測的期望值與預測值之間的差平方和,用於描述模型的穩定性
導致原因: 偏差:錯誤假設、模型複雜度不夠,欠擬合 方差:模型的複雜度相對於訓練集過高,過擬合
神經網路的擬合能力非常強,因此它的訓練誤差(偏差)通常較小,但容易過擬合.較大方差,所以一般用正則化防止過擬合
先驗概率和後驗概率
條件概率(似然概率):P(x|y),表示y發生的條件下x發生的概率 先驗概率:P(A)、P(B),事件發生前的預判概率,一般是單獨事件 後驗概率:基於先驗概率求得的反向條件概率,形式上與條件概率相同(若 P(X|Y) 為正向,則 P(Y|X) 為反向) 貝葉斯公式:P(Y|X)=P(X|Y)P(Y)/P(X)
生成模型和判別模型
監督學習的任務是學習一個模型,對給定的輸入預測相應的輸出 這個模型的一般形式為一個決策函式或一個條件概率分佈(後驗概率):Y=f(X) or P(Y|X) 決策函式:輸入 X 返回 Y;其中 Y 與一個閾值比較,然後根據比較結果判定 X 的類別 條件概率分佈:輸入 X 返回 X 屬於每個類別的概率;將其中概率最大的作為 X 所屬的類別
監督學習模型可分為生成模型與判別模型 生成模型學習的是聯合概率分佈P(X,Y),然後根據條件概率公式計算 P(Y|X),P(Y|X)=P(X,Y)/P(X) 判別模型直接學習決策函式或者條件概率分佈,判別模型學習的是類別之間的最優分隔面,反映的是不同類資料之間的差異
由生成模型可以得到判別模型,但由判別模型得不到生成模型,當存在“隱變數”時,只能使用生成模型
優缺點 生成:學習收斂速度快,但學習計算過程複雜 判別:直接面對預測,學習準確率高,抽象使用特徵.簡化學習過程,但不能反應資料本身的特性
常見 生成:樸素貝葉斯NBM、隱馬爾可夫模型HMM、混合高斯模型GMM、貝葉斯網路、馬爾可夫隨機場MRF 判別:knn、感知機(神經網路)、決策樹、邏輯斯蒂迴歸、最大熵模型、SVM、提升方法boosting、條件隨機場CRF
模型度量指標
True Positive(TP):將正類預測為正類的數量. True Negative(TN):將負類預測為負類的數量. False Positive(FP):將負類預測為正類數 False Negative(FN):將正類預測為負類數 準確率(accuracy):預測正確/總 精確率(precision):正類預測正確/預測正類總 召回率(recall):正類預測正確/本來正類總 F1值(精確率和召回率的調和均值):各分之一和分之2
處理缺失值
可以去掉或填充 當缺失值多時,直接捨棄該特徵,否則會帶來較大噪聲 當缺失值少時,可以用0或均值、相鄰資料等方式填充
一個完整的機器學習專案流程
數學抽象-資料獲取-預處理和特徵選擇-模型訓練與調優-模型診斷-模型融合.整合-上線執行
數學抽象:得先明確問題,ML訓練是耗時的事情,所以需要明確任務目標,是分類、迴歸還是聚類…
資料獲取:資料決定了機器學習結果的上限,而演算法只是儘可能逼近這個上限。 資料需要有代表性,對於分類問題,資料偏斜不能過於嚴重(平衡),不同類別的資料數量不要有數個數量級的差距。
預處理與特徵選擇:良好的資料要能夠提取出良好的特徵才能真正發揮效力。 預處理/資料清洗是很關鍵的步驟,歸一化、降維、缺失值處理等,資料探勘過程中很多時間就花在它們上面。 需要反覆理解業務,篩選出顯著特徵、摒棄非顯著特徵,這對很多結果有決定性的影響。 特徵選擇好了,演算法實現事半功倍,簡單的演算法也能得到好的效果。 這需要運用特徵有效性分析的相關技術,如相關係數、卡方檢驗、平均互資訊、條件熵、後驗概率、邏輯迴歸權重等方法。

模型訓練與調優:調參.超引數,這需要我們對演算法的原理有深入的理解,理解優缺點、和業務關聯調優。
模型診斷:交叉驗證,繪製學習曲線等,檢測過擬合欠擬合的問題,還有誤差分析 過擬合就增加資料量、降低模型複雜度,欠擬合就提高特徵數量和質量、增加模型複雜度。 通過觀察誤差樣本,全面分析誤差產生誤差的原因:是引數的問題還是演算法選擇的問題,是特徵的問題還是資料本身的問題… 診斷後的模型需要進行調優,調優後的新模型需要重新進行診斷,這是一個反覆迭代不斷逼近的過程,需要不斷地嘗試,進而達到最優狀態。
模型融合.整合:一般來說,模型融合後都能使得效果有一定提升,而且效果很好。
上線執行:產品化,以結果導向的工程,模型在線上執行的效果直接決定模型的成敗。 不單純包括其準確程度、誤差等情況,還包括其執行的速度(時間複雜度)、資源消耗程度(空間複雜度)、穩定性是否可接受。
資訊理論
資訊理論的基本想法是:一件不太可能的事發生,要比一件非常可能的事發生,提供更多的資訊。 非常可能發生的事件資訊量要比較少,並且極端情況下,一定能夠發生的事件應該沒有資訊量。 獨立事件應具有增量的資訊。例如,投擲的硬幣兩次正面朝上傳遞的資訊量,應該是投擲一次硬幣正面朝上的資訊量的兩倍。
一條資訊的資訊量和他的不確定性有直接的關係,我們要清楚一個非常不確定的事就需要了解大量資訊,如果我們對一個事已經瞭解很多,那就不需要太多的資訊就能把他搞懂——資訊量就等於不確定性的多少
資訊熵H(X)=E(I(x))=sum(P(x)logP(x)) 交叉熵Hp(Q)=ElogQ(x)=sum(P(x)logQ(x))
SVM
支援向量機是一種二分類模型,求其在特徵空間上間隔最大的線性分類器,使用核方法也可以變成了非線性分類器 SVM 的學習策略就是間隔最大化,可形式化為一個求解凸二次規劃的問題 SVM 的最優化演算法是求解凸二次規劃的最優化演算法。
訓練資料集中與分離超平面距離最近的樣本點的例項稱為支援向量
當訓練資料線性可分時,通過硬間隔最大化,學習一個線性分類器,即線性可分支援向量機,又稱硬間隔支援向量機。 當訓練資料接近線性可分時,通過軟間隔最大化,學習一個線性分類器,即線性支援向量機,又稱軟間隔支援向量機。 當訓練資料線性不可分時,通過使用核技巧及軟間隔最大化,學習非線性支援向量機。
核函式表示將輸入從輸入空間對映到特徵空間後得到的特徵向量之間的內積
線性 SVM 的推導分為兩部分 如何根據間隔最大化的目標匯出 SVM 的標準問題,拉格朗日乘子法對偶問題的求解過程
最大化幾何間隔得到問題:min ||w||^2/2 s.t. yi(wTxi+b)>=1 i=1,n 凸二次優化問題,然後通過拉格朗日函式和對偶性一步步求解二次規劃問題
整合學習
分為bagging(並行)和boosting(序列) 一般都使用決策樹作為基學習器,因為決策樹是不穩定(資料的變動會對結果造成較大影響)學習器 基學習器為不穩定的好處就是他容易受到樣本分佈的影響(方差大),具有隨機性,這有助於整合學習中提升模型的泛化能力 為了更好的引入隨機性,有時會隨機選擇一個屬性子集中的最優分裂屬性,而不是全域性最優(隨機森林RF)
決策樹
決策樹(Decision Tree)是在已知各種情況發生概率的基礎上,通過構成決策樹來求取淨現值的期望值大於等於零的概率,評價專案風險,判斷其可行性的決策分析方法,是直觀運用概率分析的一種圖解法。(通過資訊熵.資訊增益來選擇拆分)
CART 決策樹 CART 演算法是在給定輸入隨機變數 X 條件下輸出隨機變數 Y 的條件概率分佈的學習方法。 CART 演算法假設決策樹是二叉樹,內部節點特徵的取值為“是”和“否”。 這樣的決策樹等價於遞迴地二分每個特徵,將輸入空間/特徵空間劃分為有限個單元,然後在這些單元上確定在輸入給定的條件下輸出的條件概率分佈。 CART 決策樹既可以用於分類,也可以用於迴歸; 對迴歸樹 CART 演算法用平方誤差最小化準則來選擇特徵,對分類樹用基尼指數最小化準則選擇特徵
GBDT 梯度提升決策樹 梯度提升是梯度下降的近似方法,其關鍵是利用損失函式的負梯度作為殘差的近似值,來擬合下一個決策樹。
DL相關
過擬合與欠擬合
欠擬合指模型不能在訓練集上獲得足夠低的訓練誤差; 過擬合指模型的訓練誤差與測試誤差(泛化誤差)之間差距過大; 反映在評價指標上,就是模型在訓練集上表現良好,但是在測試集和新資料上表現一般(泛化能力差)
降低過擬合方法 資料擴充(影象變換.Gan生成.MT生成等) 降低模型複雜度(神經網路減少層數.神經元個數.決策樹剪枝等) 權值約束(L1L2等) 整合學習(dropout、RF、GBDT等) 提前終止
降低欠擬合方法 加入新特徵(因子分解機FM、Deep-Crossing、自編碼器) 增加模型複雜度(神經網路增加層數.神經元個數) 減少或去掉正則化(新增正則化項是為了限制模型的學習能力,減小正則化項的係數則可以放寬這個限制;模型通常更傾向於更大的權重,更大的權重可以使模型更好的擬合數據)
反向傳播
梯度下降法中需要利用損失函式對所有引數的梯度來尋找區域性最小值點; 而反向傳播演算法就是用於計算該梯度的具體方法,其本質是利用鏈式法則對每個引數求偏導。 z=wx+b,a=sigm(z) ,最後算出dz=A-Y ,z為上一層啟用值
啟用函式
為什麼邏輯迴歸要套一層比如sigm的非線性啟用函式,用線性迴歸不好麼? 使用啟用函式的目的是為了向網路中加入非線性因素 加強網路的表示能力,解決線性模型無法解決的問題
神經網路的萬能近似定理認為主要神經網路具有至少一個非線性隱藏層,那麼只要給予網路足夠數量的隱藏單元,它就可以以任意的精度來近似任何從一個有限維空間到另一個有限維空間的函式
使得神經網路具有的擬合非線性函式的能力,使得其具有強大的表達能力(只用線性約束分類空間太蠢了,即便加多少層還是線性組合,就永遠畫不成一個圓)
不過部分層純線性是可以接受的,這可以減少網路中的引數
啟用函式: 整流線性單元ReLU、滲漏整流線性單元Leaky ReLU(x為負梯度為0.01)、maxout 單元(ReLU擴充套件,可學習的k段函式)、sigmoid、tanh 線性:softmax(多分類輸出層,概率分佈z/sum(z))、徑向基函式RBF(很老.也存在問題:不易優化,基本不用,式子也難寫)、softplus(ReLU平滑版本log(1+exp(z)))、硬雙曲正切函式(hard tanh,max(-1,min(1,a)))
其中 sigm函式在x過大過小容易發生梯度消失,所以基本不在訓練層用 ReLU在負半區輸出為0,造成了網路的稀疏性.稀疏啟用,可以緩解過擬合問題 ReLU的求導不涉及浮點運算,所以模型計算速度更快 雖然從數學的角度看ReLU在0點不可導,因為它的左導數和右導數不相等,但在實現時通常會返回左導數或右導數的其中一個,而不是報告一個導數不存在的錯誤,從而避免了這個問題
正則化
批標準化Batch Normalization 訓練的本質是學習資料分佈。如果訓練資料與測試資料的分佈不同會降低模型的泛化能力。因此,應該在開始訓練前對所有輸入資料做歸一化處理。 而在神經網路中,因為每個隱層的引數不同,會使下一層的輸入發生變化,從而導致每一批資料的分佈也發生改變;致使網路在每次迭代中都需要擬合不同的資料分佈,增大了網路的訓練難度與過擬合的風險。
BN方法會針對每一批資料,在網路的每一層輸入之前增加歸一化處理,使輸入的均值為0,標準差為1,目的是將資料限制在統一的分佈下,然後作為該神經元的啟用值
BN可以看作在各層之間加入了一個新的計算層,對資料分佈進行額外的約束,從而增強模型的泛化能力,也同時降低了模型的擬合能力.破壞了之前的特徵分佈(防止過擬合)
L1L2 他們都可以限制模型的學習能力——通過限制引數的規模,使模型偏好於權值較小的目標函式,防止過擬合。 他們會使模型偏好於更小的權值,限制了引數的分佈,從而降低了模型的複雜度。
L1 正則化可以產生稀疏權值,而 L2 不會 因為L1範數約束會得到稀疏解,但L2俗稱嶺迴歸,是權重衰減,並沒有稀疏的作用
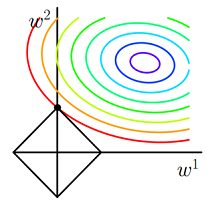
L1
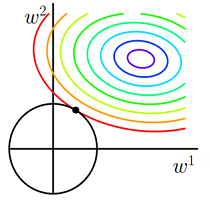
L2
範數
L0:非零元素的個數 L1:sum(|x|) L2:所有元素平方和開方 Lp:所有元素p方和開p方 L無窮:最大元素的絕對值,也稱最大範數 Frobenius 範數:矩陣化的 L2 範數
範數的作用:正則化——權重衰減/引數範數懲罰 權重衰減的目的:限制模型的學習能力,通過限制引數θ的規模(主要是權重w的規模,偏置b不參與懲罰),使模型偏好於權值較小的目標函式,防止過擬合。
dropout
Dropout策略相當於集成了包括所有從基礎網路除去部分單元后形成的子網路。 一般來說隱藏層的取樣為0.5,輸入取樣0.8
在整合學習Bagging下,所有模型都是獨立的;而在Dropout下,所有模型共享引數,其中每個模型繼承父神經網路引數的不同子集

指數加權平均(指數衰減平均)
Vt=βVt-1+(1-β)θt 遞迴式子裡越久前的記錄其權重呈指數衰減,因此指數加權平均也稱指數衰減平均
指數加權平均在前期會存在較大的誤差,當t較小時,與希望的加權平均結果差距較大 可以引入一個偏差修正,Vt/1-β^t 偏差修正只對前期的有修正效果,後期當t逐漸增大時1-β^t -> 1,將不再影響 Vt,與期望相符
優化演算法
梯度下降:通過迭代的方式尋找模型的最優引數 當目標函式是凸函式時,梯度下降的解是全域性最優解;但在一般情況下,梯度下降無法保證全域性最優。
隨機梯度下降(SGD):每次使用單個樣本的損失來近似平均損失
放棄了梯度的準確性,僅採用一部分樣本來估計當前的梯度;因此 SGD 對梯度的估計常常出現偏差,造成目標函式收斂不穩定,甚至不收斂的情況

小批量隨機梯度下降(MSGD):可以降低隨機梯度的方差,使模型迭代更加穩定 還有一個目的就是可以進行矩陣化運算和平行計算 較大的批能得到更精確的梯度估計,較小的批能帶來更好的泛化誤差
無論是經典的梯度下降還是隨機梯度下降,都可能陷入區域性極值點;除此之外,SGD 還可能遇到“峽谷”和“鞍點”兩種情況 峽谷類似一個帶有坡度的狹長小道,左右兩側是“峭壁”;在峽谷中,準確的梯度方向應該沿著坡的方向向下,但粗糙的梯度估計使其稍有偏離就撞向兩側的峭壁,然後在兩個峭壁間來回震盪。 鞍點的形狀類似一個馬鞍,一個方向兩頭翹,一個方向兩頭垂,而中間區域近似平地;一旦優化的過程中不慎落入鞍點,優化很可能就會停滯下來。
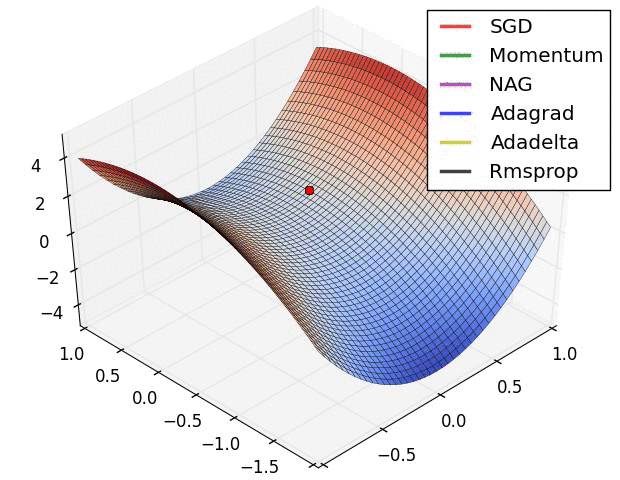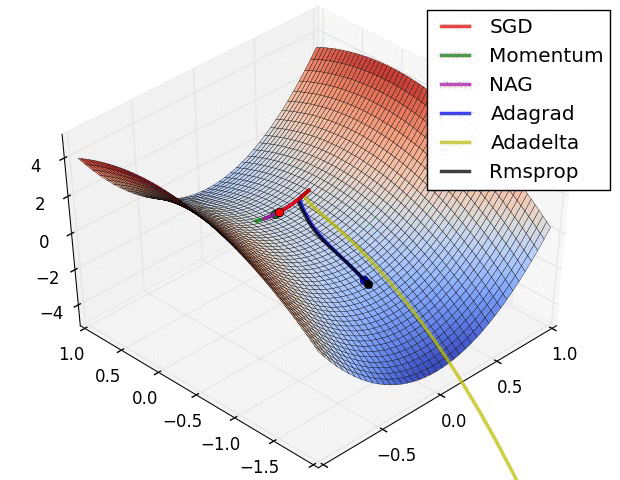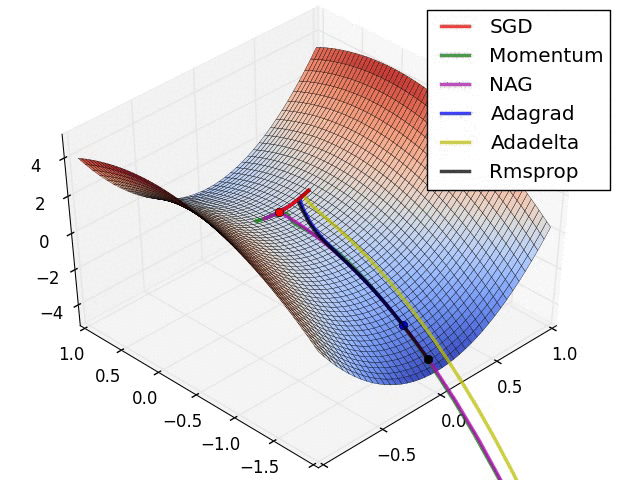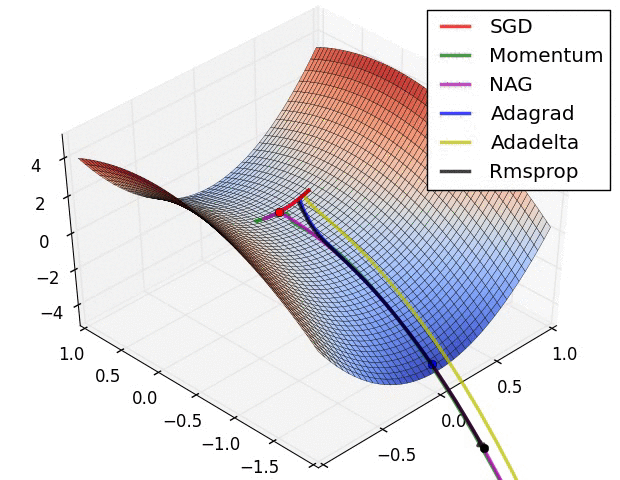
動量(Momentum)演算法:帶動量的 SGD
引入動量(Momentum)方法一方面是為了解決“峽谷”和“鞍點”問題;一方面也可以用於SGD 加速,特別是針對高曲率、小幅但是方向一致的梯度。
動量方法以一種廉價的方式模擬了二階梯度(牛頓法)

NAG 演算法(Nesterov 動量)
NAG 把梯度計算放在對引數施加當前速度之後

自適應學習率的優化演算法:
AdaGrad:獨立地適應模型的每個引數:具有較大偏導的引數相應有一個較大的學習率,而具有小偏導的引數則對應一個較小的學習率(每個引數的學習率會縮放各引數反比於其歷史梯度平方值總和的平方根)

RMSProp:是為了解決 AdaGrad 方法中學習率過度衰減的問題,使用指數衰減平均(遞迴定義)以丟棄遙遠的歷史,還加入了一個超引數β來控制衰減速率

AdaDelta:和RMSProp差不多,只是他已經不需要設定全域性學習率了
Adam:除了加入歷史梯度平方的指數衰減平均(r)外,還保留了歷史梯度的指數衰減平均(s),相當於動量。

AdaMax:Adam 的一個變種,對梯度平方的處理由指數衰減平均改為指數衰減求最大值
Nadam:Nesterov 動量版本的 Adam

優化演算法在損失面上的表現
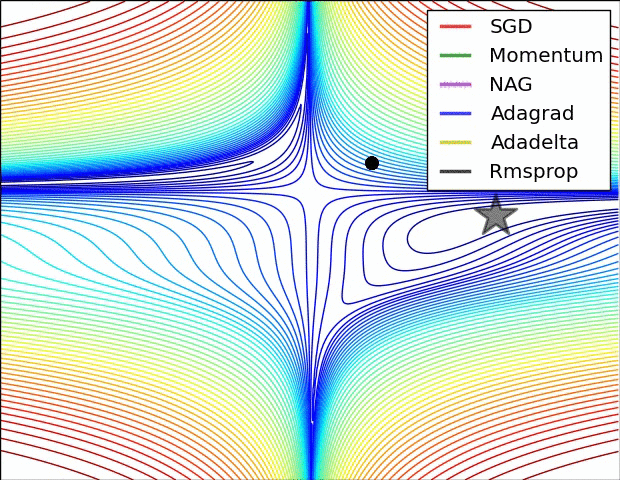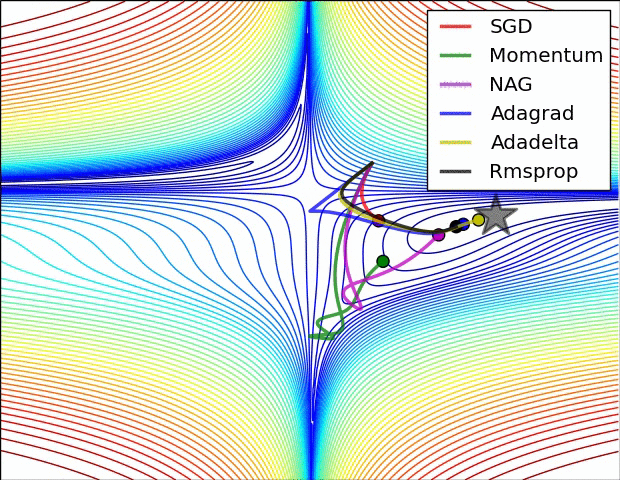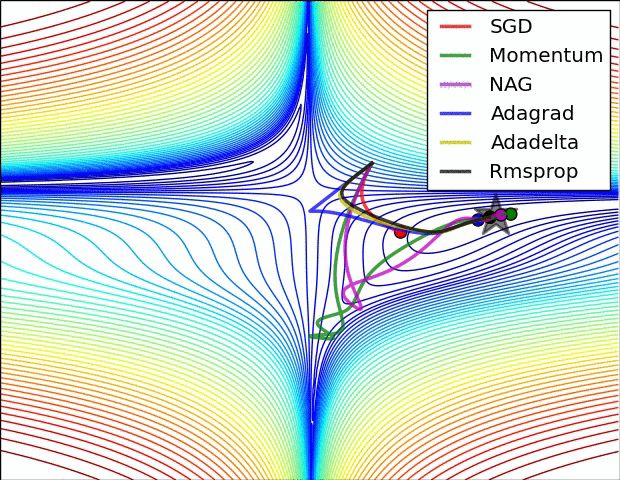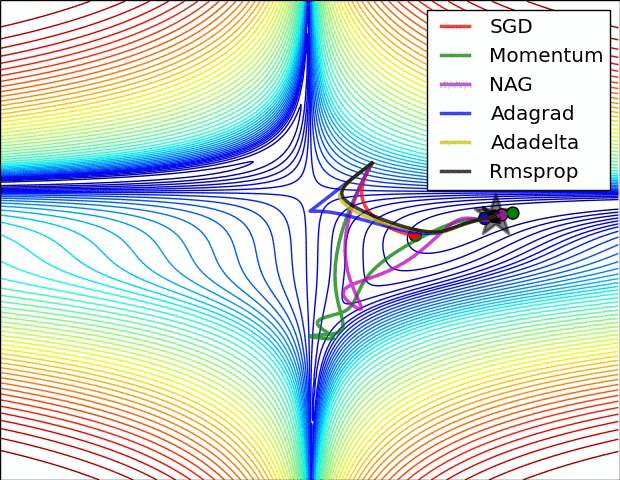
優化演算法在鞍點的表現
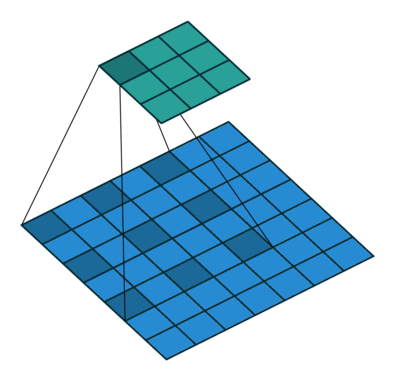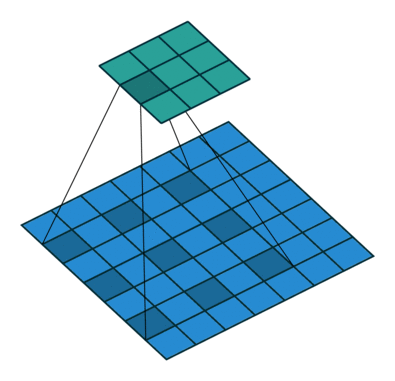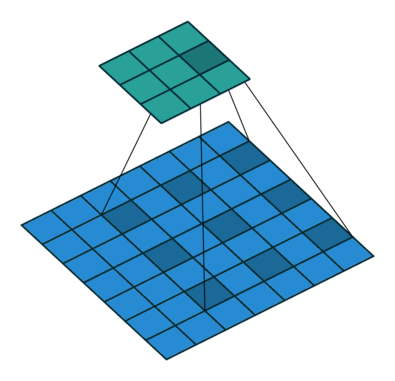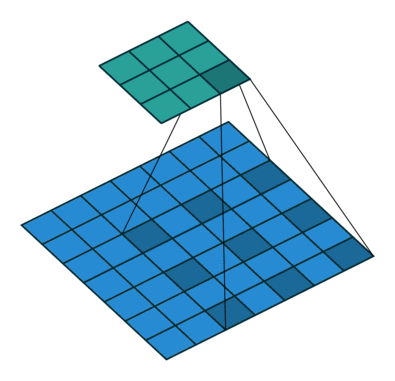
CNN
特點:稀疏連線、引數共享、平移等變性(怎麼平移都會檢測出相同的特徵)
好處:通過相對小的卷積核檢測特徵,用卷積核來代替BP全連線,減少引數數量、加速計算、減少記憶體需求、提高效率

卷積的正向傳播實際就是矩陣相乘,所以反向傳播和一般的全連線網路是類似的
轉置卷積又稱反捲積,是為了重建先前的空間解析度的卷積,但其內部實際上執行的是常規的卷積操作 雖然轉置卷積並不能還原數值,但是用於編碼器-解碼器結構中,效果仍然很好 這樣,轉置卷積可以同時實現影象的粗粒化和卷積操作,而不是通過兩個單獨過程來完成
空洞卷積又稱擴張卷積.膨脹卷積,他能夠捕捉更遠的資訊,獲得更大的感受野,同時不增加引數的數量,也不影響訓練的速度
RNN
RNN本質上是一個遞推函式 一般的前饋網路,通常就是固定的輸入輸出,一次性接收輸入,忽略了序列中的順序資訊;CNN在處理變長序列時,可以用華東視窗學習,但也難學習到序列間的長距離依賴
RNN優勢: 適合處理序列資料,特別是帶有時序關係的序列,比如文字資料 把每一個時間步中的資訊編碼到狀態變數中,使網路具有一定的記憶能力,從而更好的理解序列資訊 具有對序列中時序資訊的刻畫能力,因此在處理序列資料時往往能得到更準確的結果
普通的前饋網路就像火車的一節車廂,只有一個入口,一個出口;而RNN相當於一列火車,有多節車廂接收當前時間步的輸入資訊並輸出編碼後的狀態資訊(包括當前的狀態和之前的所有狀態)。
RNN常用啟用函式為tanh而不是ReLU、sigm等,因為tanh值域為[-1,1],這與多數場景下特徵分佈以0為中心相吻合,也可以防止數值上溢問題

LSTM 在傳統 RNN 的基礎上加入了門控機制來限制資訊的流動 主要通過遺忘門和輸入門來實現長短期記憶:如果當前時間點沒有重要資訊,遺忘門接近為1,輸入門0,此時過去的記憶將會被儲存,從而實現長期記憶,反之亦然.短期記憶,如果當前和以前的記憶都重要,則遺忘門f->1,輸入門i->1
在 LSTM 中,所有控制門都使用 sigmoid 作為啟用函式
sigmoid 的值域為 (0,1),符合門控的定義
在計算候選記憶或隱藏狀態時,使用tanh 作為啟用函式

GRU和LSTM的不同: GRU把遺忘門和輸入門合併為更新門z,並使用重置門r代替輸出門; 合併了記憶狀態C和隱藏狀態 h 更新門 z用於控制前一時刻的狀態資訊被融合到當前狀態中的程度 重置門 r用於控制忽略前一時刻的狀態資訊的程度
為什麼一般使用CNN代替RNN
訓練RNN和LSTM非常困難,因為計算能力受到記憶體和頻寬等的約束 每個LSTM單元需要四個仿射變換,且每一個時間步都需要執行一次,這樣的仿射變換會要求非常多的記憶體頻寬 新增更多的計算單元很容易,但新增更多的記憶體頻寬卻很難,這與目前的硬體加速技術不匹配
並且RNN容易發生梯度消失,雖然LSTM的門控,或者加入注意力機制模組,在一定程度上解決了這個問題,但實際上使模型更復雜了

從任務角度考慮,差不多也是CNN更有利,LSTM因為能記憶比較長的資訊,所以在推斷方面有不錯的表現 但是在事實類問答中,並不需要複雜的推斷,答案往往藏在一個n-gram短語中,而CNN能很好的對n-gram建模
TCN時間卷積網路
使用CNN,只是最後一層一個加了attention,一個一個預測出來,而CNN是全部一起預測出來的
有人說時間卷積網路(TCN)將取代RNN成為NLP或者時序預測領域的王者。 RNN耗時太長,由於網路一次只讀取、解析輸入文字中的一個單詞(或字元),深度神經網路必須等前一個單詞處理完,才能進行下一個單詞的處理。這意味著 RNN 不能像 CNN 那樣進行大規模並行處理。
TCN是用來解決時間序列預測的演算法,涉及到了一維卷積、擴張卷積、因果卷積、殘差卷積的跳層連線等演算法
擴張卷積的好處是不做pooling損失資訊的情況下,加大了感受野,讓每個卷積輸出都包含較大範圍的資訊
因果卷積的理解可以認為是:不管是自然語言處理領域中的預測還是時序預測,都要求對時刻t 的預測yt只能通過t時刻之前的輸入x1到xt-1來判別。這種思想有點類似於馬爾科夫鏈。
殘差卷積的跳層連線,防止梯度消失
CNN序列建模
一般認為 CNN 擅長處理網格結構的資料,比如影象(二維畫素網路)
卷積層試圖將神經網路中的每一小塊進行更加深入的分析,從而得出抽象程度更高的特徵。 一般來說通過卷積層處理的神經元結點矩陣會變得更深,即神經元的組織在第三個維度上會增加。
時序資料同樣可以認為是在時間軸上有規律地取樣而形成的一維網格
seq2seq
大部分自然語言問題都可以使用 Seq2Seq 模型解決,萬物皆 Seq2Seq
seq2seq的核心思想是把一個輸出序列,通過編碼(Encode)和解碼(Decode)兩個過程對映到一個新的輸出序列,一般都使用 RNN 進行建模
Seq2Seq 之所以流行,是因為它為不同的問題提供了一套端到端(End to End)的解決方案,免去了繁瑣的中間步驟,從輸入直接得到結果 比如機器翻譯、機器問答、文字摘要、語音識別、影象描述等
有3種解碼方法:貪心、Beam Search、維特比演算法 貪心每到達一個節點,只選擇當前狀態的最優結果,其他都忽略,直到最後一個節點,貪心法只能得到某個區域性最優解 Beam Search 會在每個節點儲存當前最優的 k 個結果(排序後),其他結果將被“剪枝”,因為每次都有 k 個分支進入下一個狀態。Beam Search 也不能保證全域性最優,但能以較大的概率得到全域性最優解。 維特比演算法利用動態規劃的方法可以保證得到全域性最優解,但是當候選狀態極大時,需要消耗大量的時間和空間搜尋和儲存狀態,因此維特比演算法只適合狀態集比較小的情況
Beam Search集束搜尋 該方法會儲存前 beam_size 個最佳狀態,每次解碼時會根據所有儲存的狀態進行下一步擴充套件和排序,依然只保留前 beam_size 個最佳狀態;迴圈迭代至最後一步,儲存最佳選擇。 當 beam_size = 1 時,Beam Search 即為貪心搜尋
維特比(Viterbi)演算法核心思想:利用動態規劃可以求解任何圖中的最短路徑問題
其他最短路徑演算法: Dijkstra 演算法(迪傑斯特拉演算法):基於貪心,用於求解某個頂點到其他所有頂點之間的最短路徑,時間複雜度n2,適用範圍廣,可用於求解大部分圖結構中的最短路徑。 Floyd 演算法(弗洛伊德演算法):求解的是每一對頂點之間的最短路徑,時間複雜度n3。
加速訓練方法
CNN比RNN更適合並行架構 可以用optimizer:動量、自適應學習率 減少引數(比如用GRU代替LSTM) 引數初始化(BN) 外部方法:GPU加速.叢集、CPU叢集、資料並行.模型並行以及混合並行
about
MobileNet
近些年來,CNN由於其出色的表現,漸漸成為了影象領域中主流的演算法框架。
CNN的表現如此突出主要是因為CNN模型有大量的可學習引數,使得CNN模型具備很強的學習能力和表達能力,然而,也正因為這些大量的引數使得在硬體平臺上部署CNN模型時有較大困難,尤其是在一些計算資源非常受限的平臺上,如移動裝置、嵌入式裝置等。
基於對CNN模型進行加速的要求,可以從快速網路結構設計的角度出發設計設計一些小而精的模型,比如mobile net等 他致力於打造一個輕量化的深度神經網路,以便應用於手機或者tesla電動汽車進行多物件識別
DDM 的卷積分成了 DD1 和 11M,前者叫深度空間分離卷積層(depthwise separable convolutions我就瞎翻譯了),後者叫點空間卷積層(pointwise convolution)。 MobileNet大大減少了計算量(少了90%),但精度只下降了1%
cuda
NVIDIA的cpu平行計算架構 配置cuDNN可以進行神經網路的加速 相比標準的cuda,它在一些常用的神經網路操作上進行了效能的優化,比如卷積、pooling、歸一化、啟用層等等
使用 在編譯caffe(或者其他深度學習庫)時,只需要在make的配置檔案Makefile.config中將USE_CUDNN取消註釋即可
無人駕駛、影象處理
無人駕駛的等級:l0非自動化、l1輔助駕駛、l2部分自動化、l3有條件的自動駕駛、l4高度自動化、l5全自動
無人駕駛包括三個單元:感知(主要是感測器和智慧感知演算法)、決策(控制電路,軟硬體)、控制單元(控制介面)

在自動駕駛領域中,許多工同樣可被抽象為影象分類、影象分割、目標檢測三個基礎問題
無人駕駛感知視覺演算法:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD演算法
R-CNN是候選區域region的CNN目標檢測

fast RCNN

faster RCNN

學習資源: cv視覺網:http://www.cvvision.cn/ 有一些影象處理、無人駕駛的教程 公眾號:Apollo開發者社群 無人車相關資訊、Udacity的學習視訊 opencv的官方文件
CRNN
卷積迴圈神經網路CRNN=DCNN+RNN CRNN的網路架構由三部分組成,包括卷積層,迴圈層和轉錄層
通過採用標準CNN模型(去除全連線層)中的卷積層和最大池化層來構造卷積層的元件做特徵序列提取 一個深度雙向迴圈神經網路是建立在卷積層的頂部,作為迴圈層做序列標註 轉錄是將RNN所做的每幀預測轉換成標籤序列的過程。數學上,轉錄是根據每幀預測找到具有最高概率的標籤序列。在實踐中,存在兩種轉錄模式,即無詞典轉錄和基於詞典的轉錄。詞典是一組標籤序列,預測受拼寫檢查字典約束。在無詞典模式中,預測時沒有任何詞典。在基於詞典的模式中,通過選擇具有最高概率的標籤序列進行預測
CRNN與傳統神經網路模型相比具有一些獨特的優點: 1)可以直接從序列標籤(例如單詞)學習,不需要詳細的標註(例如字元); 2)直接從影象資料學習資訊表示時具有與DCNN相同的性質,既不需要手工特徵也不需要預處理步驟,包括二值化/分割,元件定位等; 3)具有與RNN相同的性質,能夠產生一系列標籤; 4)對類序列物件的長度無約束,只需要在訓練階段和測試階段對高度進行歸一化 5)與現有技術相比,它在場景文字(字識別)上獲得更好或更具競爭力的表現 6)它比標準DCNN模型包含的引數要少得多,佔用更少的儲存空間
線性迴歸和邏輯迴歸
在統計學中,線性迴歸是利用稱為線性迴歸方程的最小平方函式對一個或多個自變數和因變數之間關係進行建模的一種迴歸分析 他求最優解的方法有最小二乘法和梯度下降法
線性迴歸主要用來解決連續值預測的問題,邏輯迴歸用來解決分類的問題,輸出的屬於某個類別的概率 在SVM、GBDT、AdaBoost演算法中都有涉及邏輯迴歸 線性迴歸使用擬合函式、最小二乘,邏輯迴歸使用預測函式、最大似然估計 線性迴歸的值域為無窮,邏輯迴歸值域為(0,1),構建分類問題
線性迴歸的問題:擬合程度不好,最好用一條平滑的曲線來擬合 線上性迴歸的預測函式外套一層sigmod函式,做二元分類
線性迴歸:y=wx+b,一般的最小二乘,多個未知數(特徵)是y=a1x1+a2x2+b=AX+b(b叫做偏移量或誤差項) 誤差項是真實值和誤差值之間的一個差距。那麼肯定我們希望誤差項越小越好 損失函式L=half(sumM((y^ -y)2))),(M是樣本數),通過梯度下降法求損失函式最小值
scatter
pooling的好處有:減少特徵計算量,防止過擬合,縮小影象規模,提升計算速度
opencv的灰度圖就是R=G=B=原來的RGB相加/3,二值化就是讓影象的畫素點矩陣中的每個畫素點的灰度值為0(黑色)或者255(白色)
常用的圖片濾波器有均值濾波、高斯濾波、中值濾波、雙邊濾波、Sobel運算元、Laplacian運算元等
BP和CNN的區別:BP每層單元都是全連線的,而CNN他是連線到卷積核 卷積網路其實就是在全連線網路的基礎上,把全連線改為部分連線,然後再利用權值共享的技巧大量減少網路需要修改的權值數量
RNN的梯度爆炸可以通過LSTM門控解決
False Positive:把合法的判斷成非法的,誤報,假陽性 False Negative:把非法的判斷成合法的,漏報,假陰性
tensor張量、flow流圖 tensorboard 神經網路計算圖視覺化
Keras是基於Theano和TensorFlow的深度學習庫,由純python編寫 keras具有高度模組化,極簡,和可擴充特性 他支援CNN和RNN,或二者的結合,無縫CPU和GPU切換
為什麼要用softmax交叉熵做損失函式,平方誤差函式也能做梯度下降啊? 熵考察的是單個的資訊(分佈)的期望,交叉熵考察的是兩個的資訊(分佈)的期望 為了解決引數更新效率下降這一問題,我們使用交叉熵代價函式替換傳統的平方誤差函式
數學建模中關於資料分佈的一個最基礎的假設是什麼? 資料分訓練測試集.來自同一分佈
DL和一般的影象識別的區別:一個是精確計算,一個是模糊計算(預測)
把一個str倒置,str[::-1]
協同過濾不是ML演算法,而是推薦演算法
二叉樹遍歷:層次.先序.中序.後序,先中後的區別就是return的三個值:根左右、左根右、左右根,遞迴的取左右子樹得到遍歷結果 我們只能夠通過已知先序中序求後序或已知中序後序求先序,而不能夠已知先序和後序求中序
Augmentor 資料擴充 argparse 程式命令列 OpenSSL 安全通訊,SSL密碼庫工具
