
大資料之Hive概況與部署
Hive產生背景
(1)MapReduce程式設計不方便:開發、測試都不方便,需求變更 (2)傳統關係型資料庫人員的需要,資料庫存不下了,同時避開資料儲存在hdfs時上不得不用MapReduce來進行計算的麻煩,產生既能儲存資料又能處理分析資料的工具,就像使用sql一樣的方式來處理分析大資料,而不需要再寫MapReduce程式碼就能分析大資料。==> 基於這些場景開發出了Hive,是時代發展的產物。
檔案在大資料場景下是存放在HDFS之上的,那麼如果你想使用SQL去處理它,需要一個什麼前提?
答:結構化、檔案對映成表格 ==> Schema(可以理解為表名,庫名,表裡面有幾個欄位,欄位名,欄位型別,表的資料存放在哪裡,即元資料資訊(metastore)):建立一張表,表中的欄位與hdfs上的欄位對應上才可以查詢。 有了hive以後就可以使用SQL來處理大資料。
Hive是什麼?
官網:hive.apache.org Hive官方定義:The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive. Hive資料倉庫軟體可以使用SQL讀取,編寫和管理駐留在分散式儲存中的大型資料集。 可以將結構投影到已儲存的資料中。 提供了命令列工具和JDBC驅動程式以將使用者連線到Hive。 由此衍生出一下幾種說法: (1)這是由Facebook開源:最開始是用來解決海量結構化日誌的統計資料如:pv、yu。 (2)它是構建在Hadoop之上的資料倉庫,由此衍生了一下幾個點:Hive也是Yarn,資料可以存放在HDFS,也可以存放在S3,我們寫完一個SQL提交給Hive之後,Hive相當於把SQL翻譯成MapReduce作業,提交到YARN上面去執行,這就是所謂的構建在Hadoop之上的資料倉庫。 (3)Hive定義了一種SQL語言:HQL(類SQL) hadoop適合離線資料處理,所以hive通常也是用於離線處理 流程:SQL—>Hive—>MapReduce—>YARN 寫SQL,把SQL傳給Hive,Hive把SQL翻譯成MapReduce作業,提交到YARN執行。
同樣,有人會問:
MapReduce為什麼執行效能低?
MapReduce的執行效率很低是由它的執行模式決定的,所有的Map Task、Reduce Task全部是以程序的方式執行的,要啟動程序、銷燬程序,即使可以開啟JVM重用,但是也是用的時候開啟,結束之後關閉,而且JVM成本很高。 隨著時代的發展,人們開發出計算處理能力更強大的資料處理工具,如Spark、Tez等,因此有: Hive on MapReduce Hive on Spark Hive on Tez 所以Hive底層所支援的執行引擎有MapReduce、spark、tez。
Hive發展歷程
07年8月 由Facebook開源 13年5月 0.11版本 Stinger Phase 1 ORC HiveServer2 (里程碑式的Stinger Phase計劃第一階段) 13年10月 0.12版本 Stinger Phase 2 ORC improvement(里程碑式的Stinger Phase計劃第二階段,效能改進) 14年4月 0.13版本 Stinger Phase 3 Tez and Vectorized query engine(里程碑式的Stinger Phase計劃第三階段:向量化的查詢引擎) 14年11月 0.14版本 Stinger.next Phase 1: Cost-based optimizer (CBO)(里程碑式的Stinger Phase第二計劃:優化器)
為什麼要使用Hlve?
- SQL角度:使用簡單容易上手,方便寫SQL,操作資料方便
- Hadoop角度:能操作大規模資料集,可作為大資料處理引擎來使用,記憶體不夠還可以擴充套件
- MetaStore: Pig/Impala/Presto/SparkSQL與Hive一樣共享元資料資訊,資料遷移平滑,底層共享MetaStore,資料能互通訪問,很方便。
Hive部署架構
Hadoop是分散式的,有叢集的概念,但是Hive僅僅是一個客戶端而已,沒有叢集的概念,因為它是執行在YARN上面的,假設有10個Hadoop節點,你完全可以在任意一個Hadoop節點上部署Hive,但是多個Hive之間並部署叢集的概念,它只是將SQL提交到ResourceManager的資料倉庫,不會掛!
MetaStore儲存元資料資訊,是一個數據庫,如果要使用MySQL作為MetaStore,需要搭建一個MySQL環境,如果要使用Hive裡面的derby內建作為MetaStore,可以不用使用MySQL。
derby內建bulid-in的致命問題:只能連一個,單使用者的,而且不能支援遠端連線。所以生產上一定是使用RDBMS作為MetaStore:這種架構可能會存在MySQL掛掉/單點故障的問題,元資料資訊沒有,MySQL中的表無法與HDFS中的檔案關聯起來,所以在生產上一定要部署兩個MySQL(一主一備)。
Hive與RDBMS的關係 Hive與RDBMS的關係2 支援SQL,基於表操作 實時性: 事務:非常積累,同時成功或失敗 分散式:支援 資料量:hive處理的資料量較大 Hive QL和SQL的關係:沒有半毛錢關係,語法類似而已,方便資料平滑遷移。
Hive部署
2、解壓:[[email protected] app]$ tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/
3、配置環境變數: ~/.bash_profile [[email protected] ~]$ vi ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$ HIVE_HOME/bin:$ PATH
4、生效: [[email protected] ~]$ source ~/.bash_profile [[email protected] ~]$ echo $HIVE_HOME /home/hadoop/app/hive-1.1.0-cdh5.7.0
Hive元資料存放在哪個ip地址port埠的資料庫,使用者名稱是什麼,密碼是什麼,到現在還沒有配置,所以需要配置。
5、Hive配置:$HIVE_HOME/conf
(1)配置hive-env.sh
解壓之後hive-env.sh檔案並不存在,只有hive-env.sh.template模板檔案,所以需要複製重新命名一份。

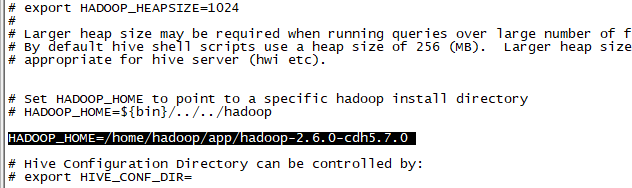
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
 (2)配置hive-site.xml檔案
解壓之後是沒有hive-site.xml檔案的,需要上傳一個
hive-site.xml配置的就是MySQL的相關資訊(url、user、passwd)
< property>
< name>javax.jdo.option.ConnectionURL< /name>
< value>jdbc:mysql://localhost:3306/sylvia_hive?createDatabaseIfNotExist=true& ;characterEncoding=UTF-8< /value>
< /property>
(2)配置hive-site.xml檔案
解壓之後是沒有hive-site.xml檔案的,需要上傳一個
hive-site.xml配置的就是MySQL的相關資訊(url、user、passwd)
< property>
< name>javax.jdo.option.ConnectionURL< /name>
< value>jdbc:mysql://localhost:3306/sylvia_hive?createDatabaseIfNotExist=true& ;characterEncoding=UTF-8< /value>
< /property>
< property> < name>javax.jdo.option.ConnectionDriverName< /name> < value>com.mysql.jdbc.Driver< /value> < /property>
< property> < name>javax.jdo.option.ConnectionUserName< /name> < value>root< /value> < /property>
< property>
< name>javax.jdo.option.ConnectionPassword< /name>
< value>123456< /value>
< /property>
 (3)拷貝mysql驅動到$ HIVE_HOME/lib
首先先上傳驅動包
[[email protected] software]$ rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring mysql-connector-java-5.1.27.jar…
100% 851 KB 851 KB/sec 00:00:01 0 Errors
[[email protected] software]$ ll
total 852
-rw-r–r-- 1 hadoop hadoop 872300 Nov 4 18:45 mysql-connector-java-5.1.27.jar
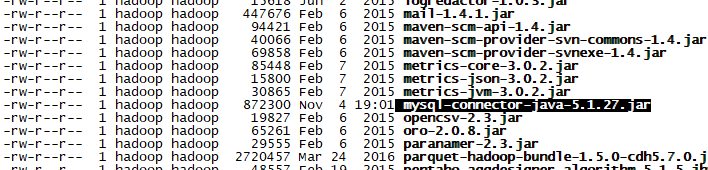
[[email protected] software]$ cp mysql-connector-java-5.1.27.jar /home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/(拷貝)
[[email protected] ~]$ cd app/hive-1.1.0-cdh5.7.0
[[email protected] hive-1.1.0-cdh5.7.0]$ cd lib
[[email protected] lib]$ ll
(3)拷貝mysql驅動到$ HIVE_HOME/lib
首先先上傳驅動包
[[email protected] software]$ rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring mysql-connector-java-5.1.27.jar…
100% 851 KB 851 KB/sec 00:00:01 0 Errors
[[email protected] software]$ ll
total 852
-rw-r–r-- 1 hadoop hadoop 872300 Nov 4 18:45 mysql-connector-java-5.1.27.jar
[[email protected] software]$ cp mysql-connector-java-5.1.27.jar /home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/(拷貝)
[[email protected] ~]$ cd app/hive-1.1.0-cdh5.7.0
[[email protected] hive-1.1.0-cdh5.7.0]$ cd lib
[[email protected] lib]$ ll
可能遇到的問題:mysql賦權
(4)看看Hive是否能正常啟動 [[email protected] bin]$ ./hive which: no hbase in (/home/hadoop/app/hive-1.1.0-cdh5.7.0/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin:/usr/java/jdk1.7.0_80/bin:/home/hadoop/app/hive-1.1.0-cdh5.7.0/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin:/usr/java/jdk1.7.0_80/bin:/usr/java/jdk1.7.0_80/bin:/root/sylviadata/bin:/usr/java/jdk1.8.0_45/bin:/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin)
Logging initialized using configuration in jar:file:/home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/hive-common-1.1.0-cdh5.7.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive (default)>

切換到mysql,可以看到之前在hive-site.xml檔案中預設建立的資料庫已經建立,並且能正常使用:
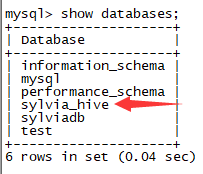
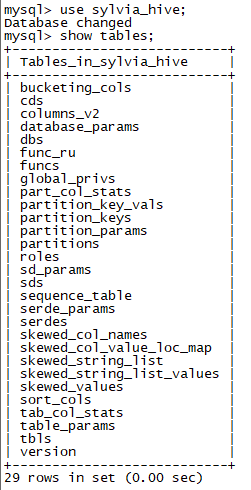 以上這些表就是所謂的Meta資訊。
hive環境部署完畢!
以上這些表就是所謂的Meta資訊。
hive環境部署完畢!
hive快速入門
在關係型資料庫裡面有資料庫和表的概念,同樣在Hive裡面也有,如Hive裡面就有一個預設的資料庫default。 hive (default)> show databases; OK default Time taken: 0.625 seconds, Fetched: 1 row(s) 建立表: hive (default)> create table sylvia_helloworld(id int,name string) > ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’; hive (default)> show tables; OK sylvia_helloworld Time taken: 0.055 seconds, Fetched: 1 row(s)
Hive日誌位置

Hive.log日誌檔案預設放在當前使用者的tmp目錄下
