
大資料之hive基礎理論
關於大資料 Hadoop是什麼 海量資料分散式的儲存和計算框架 資料儲存:HDFS: Hadoop Distributed File System 資料計算:YARN/MapReduce
1 hive 產生背景
hive定義:
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
官方網址:
2 分散式儲存
分散式儲存:HDFS、S3、OSS Hive定義了SQL語言:HQL (類SQL) 通常用於離線處理 SQL =Hive=MapReduce/Spark/Tez===>YARN Hive on MapReduce Hive on Spark Hive on Tez
3為什麼要使用Hive
1) SQL 傳統資料庫都使用的SQL語句,而Hive使用的是HQL語句。容易上手。 2) Hadoop MapReduce是基於HDFS系統的,通常而言Hive處理資料都是度多寫少。Hive的表更新是採用覆蓋的方式,而這種情況下處理資料絕大部分都會訪問整個表。這對在大規模資料集上執行的資料倉庫非常見效。 3) MetaStore: Pig/Impala/Presto/SparkSQL(共享元資料資訊)
Hive與RDBMS的關係
SQL: Hive QL和SQL的關係
實時性
事務
分散式
資料量
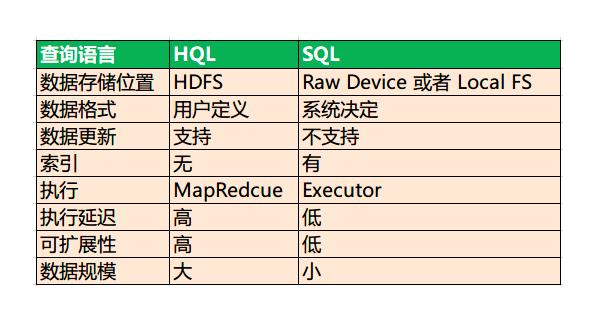
用過資料庫的都知道,資料庫需要在建立時制定好資料格式,也就是俗稱的建表。傳統資料庫和Hive在使用前都需要建表,但是不知道小夥伴們有沒有遇到這種情況。傳統資料庫在建表之後往裡面導資料時,通常會因為很多問題導致SQL異常,從而加載出錯,而常見的情況就是資料格式不對。 傳統資料庫在載入資料的時候會嚴格檢查資料格式,如果不符合規範就會拒絕載入。而這種驗證過程將耗費大量時間,這對於大資料而言,時間上是無法滿足需求的。而Hive在插入資料的時候並不會驗證資料,它只會在查詢的時候驗證。這種載入時驗證的方式稱之為讀時模式,而查詢時驗證的方式則稱之為寫時模式
metastore是hive元資料的集中存放地 metastore預設使用內嵌的derby資料庫作為儲存引擎 Derby引擎的缺點:一次只能開啟一個會話 使用Mysql作為外接儲存引擎,多使用者同時訪問
4 Hive安裝
解壓:tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/
配置環境變數: ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
生效: source ~/.bash_profile
Hive配置:$HIVE_HOME/conf
hive-env.sh
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
hive-site.xml配置的就是MySQL的相關資訊
拷貝mysql驅動到$HIVE_HOME/lib
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/ruoze_d5?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
Hive安裝
內嵌模式:元資料保持在內嵌的Derby模式,只允許一個會話連線
本地獨立模式:在本地安裝Mysql,把元資料放到Mysql內
遠端模式:元資料放置在遠端的Mysql資料庫。 想說的是,hive只是個工具,包括它的資料分析,依賴於mapreduce,它的資料管理,依賴於外部系統
這一步其實不是必須的,因為Hive預設的metadata(元資料)是儲存在Derby裡面的,但是有一個弊端就是同一時間只能有一個Hive例項訪問,這適合做開發程式時做本地測試。
Hive提供了增強配置,可將資料庫替換成mysql等關係型資料庫,將儲存資料獨立出來在多個服務示例之間共享。
5 安裝問題
1 mysql賦權 2 賬戶密碼問題 3 hostname 問題
<value>jdbc:mysql://localhost:3306/ruoze_d5?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
檢視log hive 配置檔案
[[email protected] conf]$ pwd
/home/hadoop/app/hive-1.1.0-cdh5.7.0/conf
[[email protected] conf]$ ll
total 24
-rw-r--r--. 1 hadoop hadoop 1196 Mar 24 2016 beeline-log4j.properties.template
-rw-r--r--. 1 hadoop hadoop 2429 Oct 22 17:03 hive-env.sh
-rw-r--r--. 1 hadoop hadoop 2378 Mar 24 2016 hive-env.sh.template
-rw-r--r--. 1 hadoop hadoop 2662 Mar 24 2016 hive-exec-log4j.properties.template
-rw-r--r--. 1 hadoop hadoop 3505 Mar 24 2016 hive-log4j.properties.template
-rw-r--r--. 1 hadoop hadoop 732 Oct 23 13:35 hive-site.xml
檢視log存放路徑
[[email protected] conf]$ cat hive-log4j.properties.template
# Define some default values that can be overridden by system properties
hive.log.threshold=ALL
hive.root.logger=WARN,DRFA
hive.log.dir=${java.io.tmpdir}/${user.name}
hive.log.file=hive.log
6 啟動 hive
#./hive
[[email protected] ~]$
[[email protected] ~]$ hive
which: no hbase in (/home/hadoop/app/hive-1.1.0-cdh5.7.0/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin:/usr/java/jdk1.7.0_80/bin:/usr/java/jdk1.7.0_80/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin:/usr/java/jdk1.7.0_80/bin:/bin:/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/hadoop/bin)
Logging initialized using configuration in jar:file:/home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/hive-common-1.1.0-cdh5.7.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive (default)>
快速入門 建立表。插入資料。
create table ruoze_helloworld(id int,name string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/home/hadoop/data/helloworld.txt' overwrite into table ruoze_helloworld;
alter database ruoze_d5 character set latin1;