
併發程式設計模型詳解
現在的處理器使用寫緩衝區臨時儲存向記憶體寫入資料。寫緩衝區可以保證指令流水線持續執行,他可以避免與處理器停頓下來等待向記憶體寫入資料而產生的延遲。同時,通過一批處理的方式重新整理寫緩衝區,以及合併寫緩衝區中對同一個記憶體地址的多次寫,減少對記憶體匯流排的佔用。雖然寫緩衝區有這麼多好處,但是每個處理器上的寫緩衝區,僅僅對它所在的處理器可見。這個特性會對記憶體操作的執行順序產生重要的影響:處理器對記憶體的讀寫操作的執行順序,不一定與記憶體實際發生的讀寫順序一致!
為了詳細說明,請看下錶:

假設處理器A和處理器B按照程式的順序並行執行記憶體訪問,最終可能得到x=y=0的結果,具體原因如下所示:
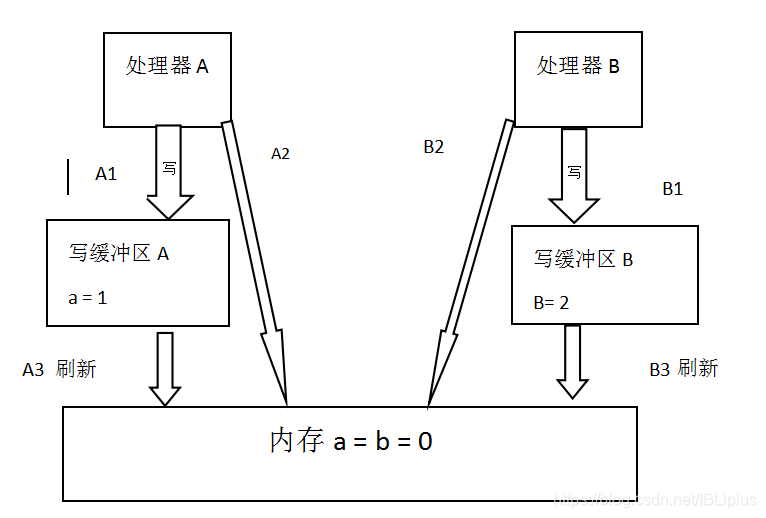
這裡的處理器A 和處理器B可以同時把共享變數寫入到自己的寫緩衝區(A1,B1),然後從記憶體中讀取另一個共享變數(A2 B2),最後才把自己寫緩衝區中儲存的髒資料重新整理到記憶體中(A3 B3)。當以這種時序執行時,程式就出現了x=y=0的結果。
從記憶體操作實際發生的順序看,直到處理器A執行A3來重新整理自己的寫快取區,寫操作A1才算真正的執行了。雖然處理器A執行記憶體操作順序被重排序為A1->A2,但記憶體操作實際發生的順序確是A2->A1,。此時,處理器A的記憶體操作資料被重排序了。(處理器B同理)
這裡的關鍵是,由於寫緩衝區僅對自己的處理器可見,他會導致處理器執行記憶體操作的順序可能會與記憶體實際的操作執行順序不一致。由於現代的處理器都會使用寫緩衝區,因此現代的處理器都會允許對寫-讀操作進行重排序。
下面是常見處理器允許的重排序的列表:

N:表示處理器不允許操作重排序 Y:表示允許重排序
從上面的表中我們可以看到,常見的處理器都允許Store-Load重排序;常見的處理器都允許對存在資料依賴的操作做重排序。space-TSO和X86擁有相對比較強的處理器記憶體模型,它們僅允許對寫-讀操作做重排序(因為他們都使用了寫緩衝區)
為了保證記憶體可見性,Java編譯器在生成指令序列的適當位置會插入記憶體屏障指令來禁止特定型別的處理器重排序,JVM把記憶體屏障指令分成4類,如下所示:
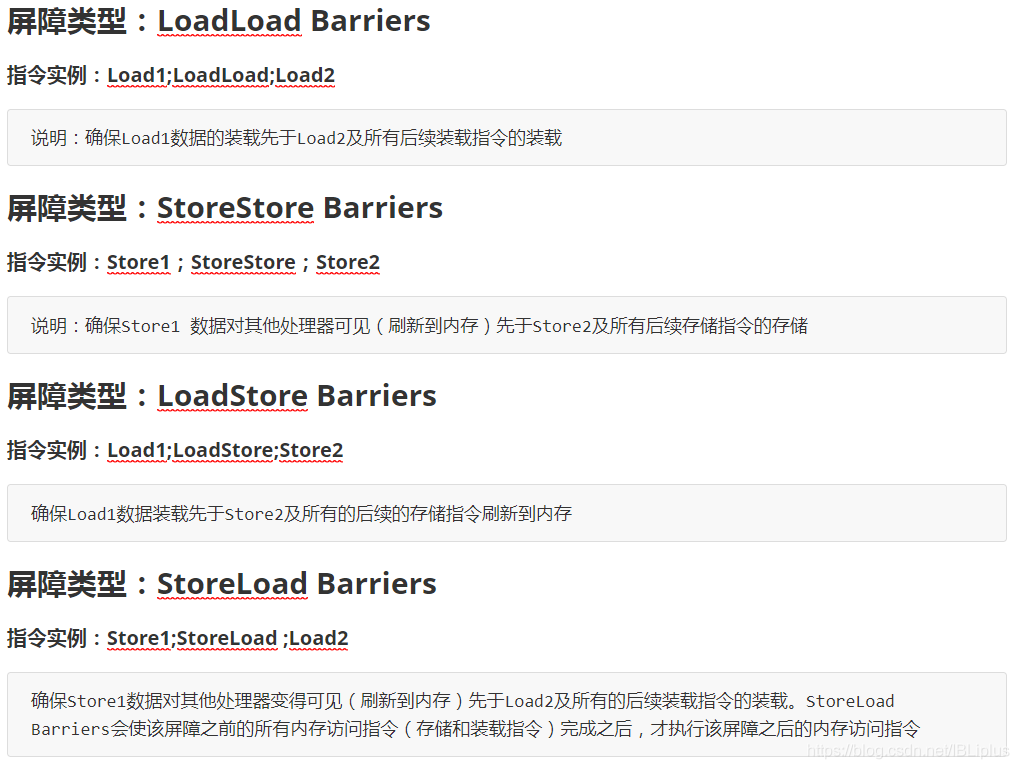
StoreLoad Barriers 是一個 “全能型” 的屏障。它同時具有其他的3個屏障的效果。現在的多處理器大多支援該屏障(其他型別的屏障不一定被所有的處理器支援)。執行該屏障的開銷會很昂貴,因為當前處理器通常把寫緩衝區中的資料全部重新整理到記憶體中(Buffer Fully Flush).