
併發程式設計——IO模型詳解
阿新 • • 發佈:2020-08-10
我是一個Python技術小白,對於我而言,多工處理一般就藉助於多程序以及多執行緒的方式,在多工處理中如果涉及到IO操作,則會接觸到**同步、非同步、阻塞、非阻塞等相關概念**,當然也是併發程式設計的基礎。
而當我接觸到網路程式設計時,是使用listen()、send()、recv() 等介面,藉助於Python提供的Socket網路套接字模組,基於UDP\TCP協議進行邏輯編寫,會發現一個問題,**socket介面都是阻塞型的**。所謂阻塞型介面是指系統呼叫(一般是IO介面)不返回呼叫結果並讓當前執行緒一直阻塞,只有當該系統呼叫獲得結果或者超時出錯時才返回。
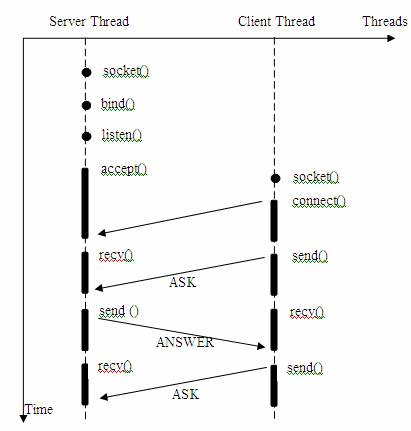
所以首先分析分析**第一種IO模型——阻塞式IO**。
# 阻塞式IO模型(blocking IO)
在linux中,預設情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:
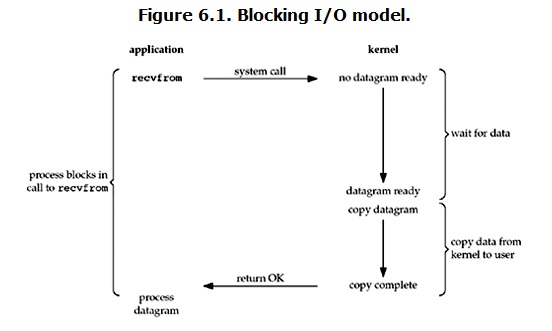
如圖所示:
客戶端向服務端請求資料時,客戶端的recvfrom介面用於接收服務端的響應資料;
服務端在接收到客戶端的請求後,kernel就開始了IO的第一個階段:**準備資料**。對於network IO來說,很多時候資料在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的資料到來。
而客戶端收發資料的程序會一直被阻塞。當kernel等到資料準備好以後,就會將資料從kernel拷貝到使用者記憶體中,然後返回響應資料,客戶端程序才能解除block狀態,重新執行起來。
就好比於:用杯子裝水,開啟水龍頭裝滿水然後離開。這一過程就可以看成是使用了阻塞IO模型,因為如果水龍頭沒有水,也要等到有水並裝滿杯子才能離開去做別的事情。**很顯然,這種IO模型是同步的!**
**所以,blocking IO的特點就是在IO執行的兩個階段(等待資料和拷貝資料兩個階段)都在block狀態。**
實際上,除非特別指定,幾乎所有的IO介面 ( 包括socket介面 ) 都是阻塞型的。這給網路程式設計帶來了一個很大的問題,如在呼叫recv(1024)的同時,執行緒將被阻塞,在此期間,執行緒將無法執行任何運算或響應任何的網路請求。
此時則會想到併發程式設計與網路程式設計相結合,即:
**在伺服器端使用多執行緒(或多程序)。多執行緒(或多程序)的目的是讓每個連線都擁有獨立的執行緒(或程序),這樣任何一個連線的阻塞都不會影響其他的連線。**
但是這樣處理存在很大的問題:
**開啟多程序或多執行緒的方式,在遇到要同時響應成百上千路的連線請求時,無論多執行緒還是多程序都會嚴重佔據系統資源,降低系統對外界的響應效率,而且執行緒與程序本身也更容易進入假死狀態。**
當然,可以藉助於**執行緒池或者連線池**。
> “執行緒池”旨在減少建立和銷燬執行緒的頻率,其維持一定合理數量的執行緒,並讓空閒的執行緒重新承擔新的執行任務。
> “連線池”維持連線的快取池,儘量重用已有的連線、減少建立和關閉連線的頻率。這兩種技術都可以很好的降低系統開銷,都被廣泛應用很多大型系統,如websphere、tomcat和各種資料庫等。
但是呢,這樣做的侷限性也是顯而易見的:
> 使用“執行緒池”和“連線池”也只是在**一定程度上緩解了頻繁呼叫IO介面帶來的資源佔用**。
>
> 而且,所謂“池”始終有其上限,當請求大大超過上限時,“池”構成的系統對外界的響應並不比沒有池的時候效果好多少。所以**使用“池”必須考慮其面臨的響應規模,並根據響應規模調整“池”的大小。**
對於所面臨的可能同時出現的上千甚至上萬次的客戶端請求,“執行緒池”或“連線池”或許可以緩解部分壓力,但是不能解決所有問題。總之,多執行緒模型可以方便高效的解決小規模的服務請求,但面對大規模的服務請求,多執行緒模型的弊端也會顯露出來,**所以可以用非阻塞介面來嘗試解決這個問題。**
# 非阻塞式IO模型(non-blocking IO)
使用Socket套接字進行網路程式設計時,可以**通過設定socket使其變為non-blocking**, `s.setblocking(False)` 。設定之後客戶端與服務端之間的資料收發以及請求響應的流程如圖所示:
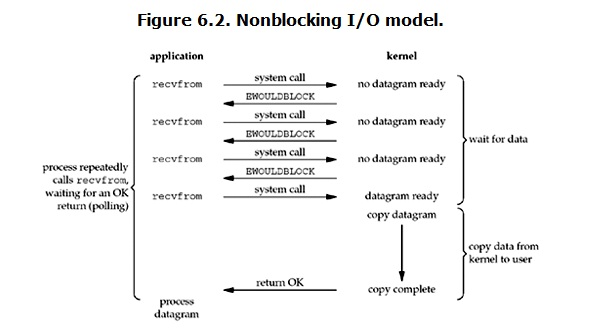
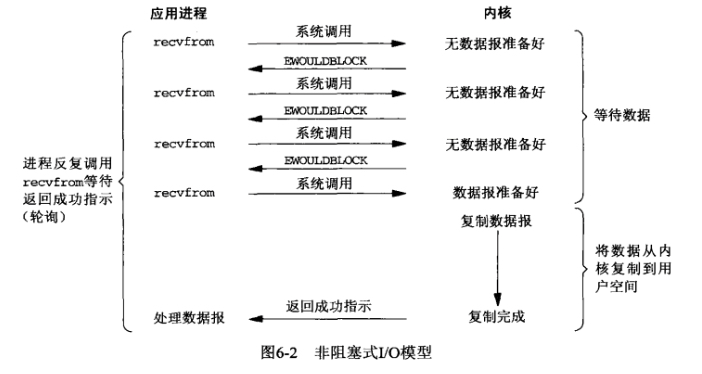
由圖可知:當客戶端向服務端請求資料時,如果服務端kernel中的資料還沒有準備好,則會立刻返回給客戶端一個error。
從而客戶端並不需要等待,而是馬上就得到了一個結果。客戶端判斷結果是一個error時,便就知道資料還沒有準備好,於是使用者就可以在本次到下次再發起請求的時間間隔內做其他事情,或者直接再次傳送請求。
一旦服務端kernel中的資料準備好以後,並且又再次收到了客戶端的system call,則將資料拷貝到使用者記憶體中(這一階段仍然是阻塞的),然後返回響應資料。
也就是說客戶端在recvfrom的過程中,其業務邏輯並沒有被阻塞,因為服務端會馬上返回響應,如果資料還沒準備好,會返回一個error。此時客戶端可以做其他的業務邏輯,然後再發起請求。重複上面的過程,這個過程通常被稱之為**輪詢**。輪詢檢查核心資料,直到資料準備好,再拷貝資料到使用者空間,進行資料處理。**需要注意的是,拷貝資料整個過程,程序仍然是屬於阻塞的狀態。**
**所以,在非阻塞式IO中,使用者程序其實是需要不斷的主動詢問kernel資料準備好了沒有。**
就好比於:某人用杯子裝水,開啟水龍頭後發現沒有水,則離開,過一會又拿著杯子來看看……在中間離開的這些時間裡,此人離開了裝水現場(回到使用者程序空間),可以做他自己的事情。這就是**非阻塞IO模型**。但是此模型只有在檢查資料是否準備好時,**是非阻塞的**,在資料到達的時候**依然要等待複製資料到使用者空間**(等待水杯中的水裝滿),**因此非阻塞式IO模型還是同步IO!**。
**Python實現非阻塞IO例項**
```python
#服務端
from socket import *
import time
s=socket(AF_INET,SOCK_STREAM)
s.bind(('127.0.0.1',8080))
s.listen(5)
s.setblocking(False) #設定socket的介面為非阻塞
conn_l=[]
del_l=[]
while True:
try:
conn,addr=s.accept()
conn_l.append(conn)
except BlockingIOError:
print(conn_l)
for conn in conn_l:
try:
data=conn.recv(1024)
if not data:
del_l.append(conn)
continue
conn.send(data.upper())
except BlockingIOError:
pass
except ConnectionResetError:
del_l.append(conn)
for conn in del_l:
conn_l.remove(conn)
conn.close()
del_l=[]
```
```python
#客戶端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
```
**注意:非阻塞IO模型絕不被推薦。**
我們不能否則其優點:能夠在等待任務完成的時間裡幹其他活了(包括提交其他任務,也就是 “後臺” 可以有多個任務在“”同時“”執行)。
但是也難掩其缺點:
> 1. 迴圈呼叫recv()將大幅度推高CPU佔用率;這也是我們在程式碼中留一句time.sleep(2)的原因,否則在低配主機下極容易出現卡機情況
> 2. 任務完成的響應延遲增大了,因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。這會導致整體資料吞吐量的降低。
**此外,在這個方案中recv()更多的是起到檢測“操作是否完成”的作用,實際作業系統提供了更為高效的檢測“操作是否完成“作用的介面,例如select()多路複用模式,可以一次檢測多個連線是否活躍。**
# 多路複用式IO模型(IO multiplexing)
IO multiplexing這個詞可能有點陌生,但是如果我說select/epoll,大概就都能明白了。有些地方也稱這種IO方式為**事件驅動IO**(event driven IO)。我們都知道,select/epoll的好處就在於單個process就可以同時處理多個網路連線的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有資料到達了,就通知使用者程序。它的流程如圖:
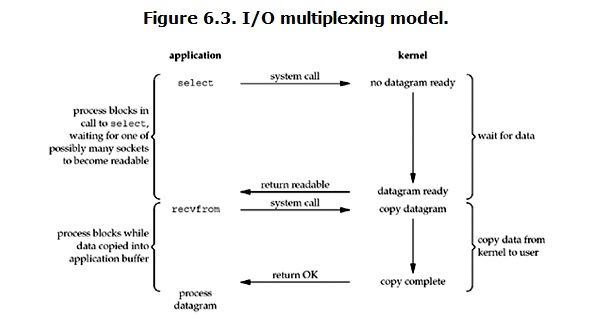
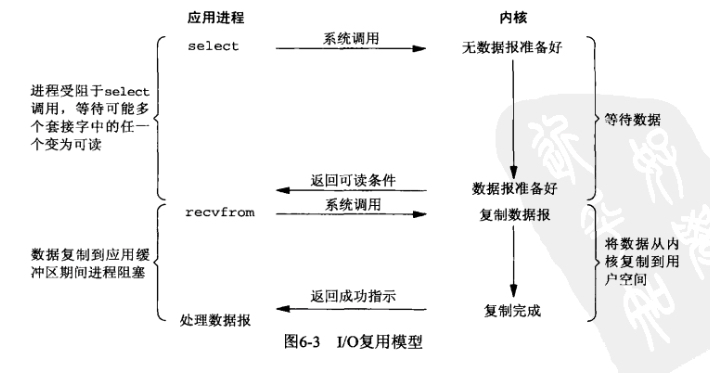
此模型**在呼叫recv前先呼叫select或者poll**,這**二者的系統呼叫都可以使服務端在核心準備好資料(網路資料到達核心)時告知使用者程序**,此時客戶端再呼叫recv接收資料,服務端可以直接講載入到客戶端空間的網路資料返回。因此,**此模型中客戶端在呼叫select或poll時,處於阻塞狀態,而在recv時則沒有阻塞!**
有人將**非阻塞IO定義成在讀寫操作時沒有阻塞於系統呼叫的IO操作(不包括資料從核心複製到使用者空間時的阻塞,因為這相對於網路IO來說確實很短暫),**如果按這樣理解,這種IO模型也能稱之為非阻塞IO模型,但是按POSIX來看,**此模型也屬於同步IO,可以稱之為同步非阻塞IO**。
這種IO模型比較特別,分個段。因為它能同時監聽多個檔案描述符(fd)。
就好比於:某人用水杯去盛水,發現有一排水龍頭,管水的大爺告訴他這些水龍頭都還沒有水,等有水了告訴他。於是便等待(select呼叫中),過了一會大爺告訴他有水了,但不知道是哪個水龍頭有水,自己看吧。於是他將水龍頭一個個開啟,往杯子裡裝水(recv)。
這裡再順便說說鼎鼎大名的epoll(高效能的代名詞啊),epoll也屬於IO複用模型,主要區別在於大爺會告訴他哪幾個水龍頭有水了,則他就不需要一個個開啟看(當然還有其它區別)。
這個圖和blocking IO的圖其實並沒有太大的不同,事實上還更差一些。因為這裡需要使用兩個系統呼叫(select和recvfrom),而blocking IO只調用了一個系統呼叫(recvfrom)。但是,用select的優勢在於它可以同時處理多個connection。
**強調:**
**1. 如果處理的連線數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server效能更好,可能延遲還更大。select/epoll的優勢並不是對於單個連線能處理得更快,而是在於能處理更多的連線。**
**2. 在多路複用模型中,對於每一個socket,一般都設定成為non-blocking,但是,如上圖所示,整個使用者的process其實是一直被block的。只不過process是被select這個函式block,而不是被socket IO給block。**
**結論: select的優勢在於可以處理多個連線,不適用於單個連線**
### 補充:POSIX
```
POSIX(可移植作業系統介面)把同步IO操作定義為導致程序阻塞直到IO完成的操作,反之則是非同步IO
```
> 按POSIX的描述似乎把同步和阻塞劃等號,非同步和非阻塞劃等號,但是也有觀點稱:**同步IO不等於阻塞IO**
**Python實現多路複用式IO模型**
```python
#服務端
from socket import *
import select
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind(('127.0.0.1',8081))
s.listen(5)
s.setblocking(False) #設定socket的介面為非阻塞
read_l=[s,]
while True:
r_l,w_l,x_l=select.select(read_l,[],[])
print(r_l)
for ready_obj in r_l:
if ready_obj == s:
conn,addr=ready_obj.accept() #此時的ready_obj等於s
read_l.append(conn)
else:
try:
data=ready_obj.recv(1024) #此時的ready_obj等於conn
if not data:
ready_obj.close()
read_l.remove(ready_obj)
continue
ready_obj.send(data.upper())
except ConnectionResetError:
ready_obj.close()
read_l.remove(ready_obj)
```
```python
#客戶端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8081))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
```
## 模型分析詳解
**select監聽fd變化的過程分析:**
```
#使用者程序建立socket物件,拷貝監聽的fd到核心空間,每一個fd會對應一張系統檔案表,核心空間的fd響應到資料後,就會發送訊號給使用者程序資料已到;
#使用者程序再發送系統呼叫,比如(accept)將核心空間的資料copy到使用者空間,同時作為接受資料端核心空間的資料清除,這樣重新監聽時fd再有新的資料又可以響應到了(傳送端因為基於TCP協議所以需要收到應答後才會清除)。
```
**該模型的優點:**
```
#相比其他模型,使用select() 的事件驅動模型只用單執行緒(程序)執行,佔用資源少,不消耗太多 CPU,同時能夠為多客戶端提供服務。如果試圖建立一個簡單的事件驅動的伺服器程式,這個模型有一定的參考價值。
```
**該模型的缺點:**
```
#首先select()介面並不是實現“事件驅動”的最好選擇。因為當需要探測的控制代碼值較大時,select()介面本身需要消耗大量時間去輪詢各個控制代碼。#很多作業系統提供了更為高效的介面,如linux提供了epoll,BSD提供了kqueue,Solaris提供了/dev/poll,…。#如果需要實現更高效的伺服器程式,類似epoll這樣的介面更被推薦。遺憾的是不同的作業系統特供的epoll介面有很大差異,#所以使用類似於epoll的介面實現具有較好跨平臺能力的伺服器會比較困難。
#其次,該模型將事件探測和事件響應夾雜在一起,一旦事件響應的執行體龐大,則對整個模型是災難性的。
```
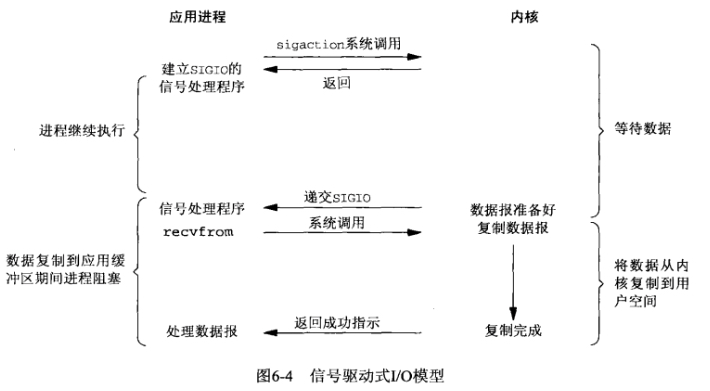
# 訊號驅動IO模型
通過呼叫sigaction註冊訊號函式,等核心資料準備好的時候系統中斷當前程式,執行訊號函式(在這裡面呼叫recv)。某人讓管水的大爺等有水的時候通知他(註冊訊號函式),沒多久他得知有水了,跑去裝水。**是不是很像非同步IO?很遺憾,它還是同步IO(省不了裝水的時間啊)**。
# 非同步IO(Asynchronous I/O)
如圖所示:客戶端程序呼叫aio_read,讓核心等資料準備好,並且複製到使用者程序空間後執行事先指定好的函式。某人讓管水的大爺將杯子裝滿水後通知他。整個過程中他都可以做別的事情(沒有recv),**這才是真正的非同步IO**。
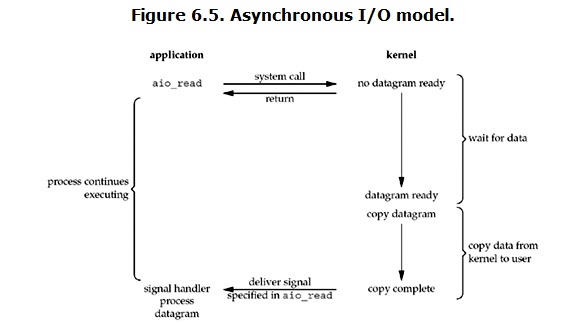
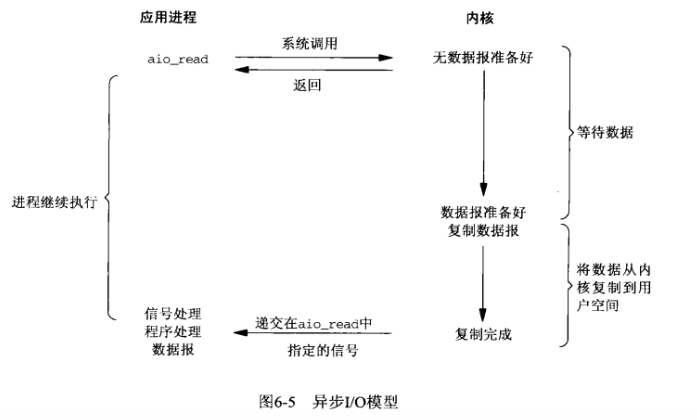
使用者程序發起請求之後,立刻就可以開始處理其他的業務邏輯。而另一方面,從kernel的角度,當它收到一個asynchronous read之後,首先它會立刻返回,所以不會對使用者程序產生任何block。然後,kernel會等待資料準備完成,然後將資料拷貝到使用者記憶體,當這一切都完成之後,kernel會給使用者程序傳送一個signal,告訴客戶端請求的資料已經複製到其空間中了。
# IO模型比較分析

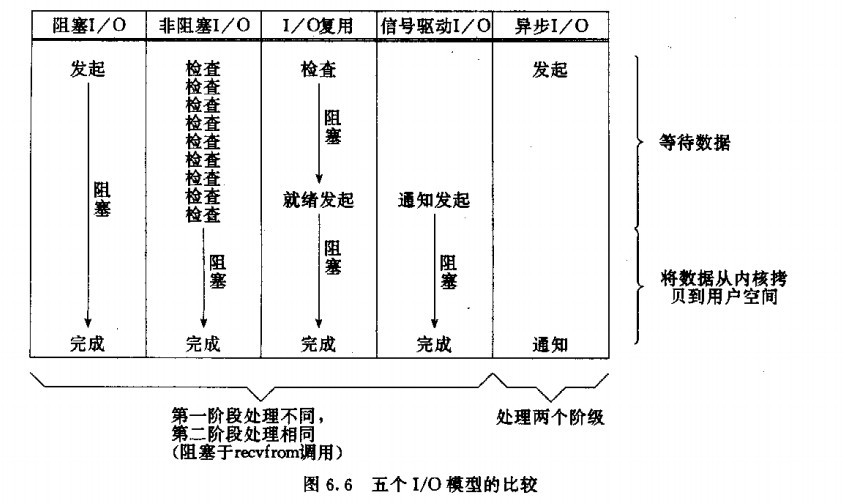
經過上面的介紹,會發現非阻塞 IO和非同步 IO的區別還是很明顯的。在非阻塞 IO中,雖然程序大部分時間都不會被block,但是它仍然要求程序去主動的check,並且當資料準備完成以後,也需要程序主動的再次呼叫recvfrom來將資料拷貝到使用者記憶體。而非同步 IO則完全不同。它就像是使用者程序將整個IO操作交給了他人(kernel)完成,然後他人做完後發訊號通知。在此期間,使用者程序不需要去檢查IO操作的狀態,也不需要主動的去拷貝資料,可以理解為**非同步非阻塞**。
IO分兩階段:
```
1.等待資料準備 (Waiting for the data to be ready)
2.將資料從核心拷貝到程序中(Copying the data from the kernel to the process)
```
一般來講:阻塞IO模型、非阻塞IO模型、IO複用模型(select/poll/epoll)、訊號驅動IO模型都屬於同步IO,因為階段2是阻塞的(儘管時間很短)。只有非同步IO模型是符合POSIX非同步IO操作含義的,不管在階段1還是階段2都可以幹別