
執行Spark官方提供的例子
去spark官網把spark下載下來:
https://spark.apache.org/downloads.html
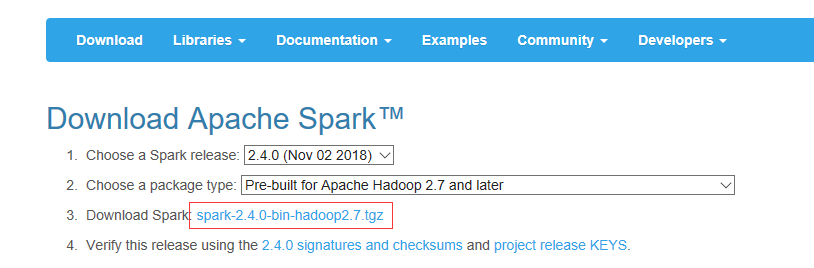
解壓,可以看下目錄:
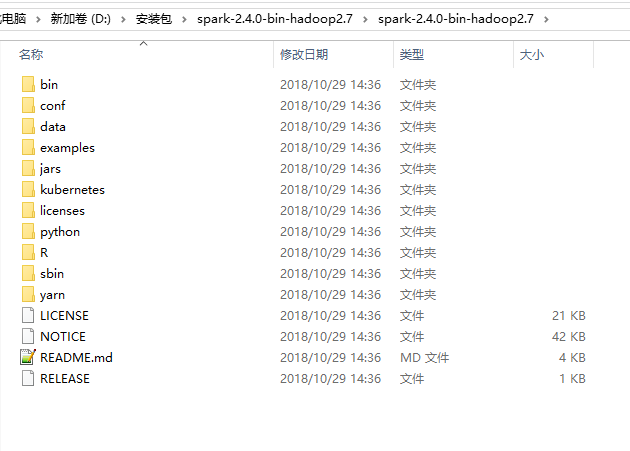
其中examples目錄下提供了java,scala,python,R語言的各種例子。點進src目錄可以看到原始碼,如:
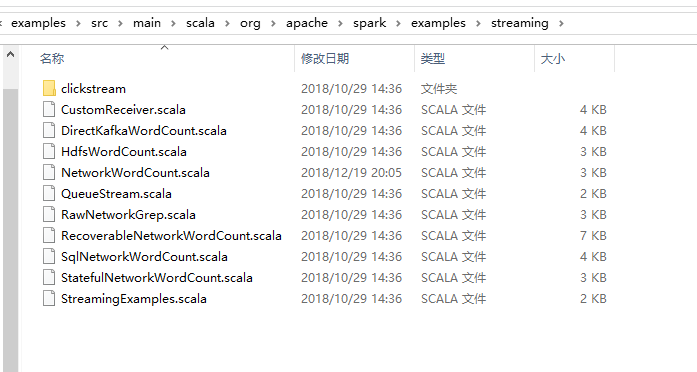
放在linux放一份,解壓,就可以直接使用了。
一.執行sparkstreaming的wordCount
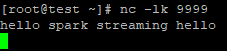
1.開一個視窗,開啟netcat,輸入:
nc -lk 9999
2.另開一個視窗,進入spark安裝目錄下,執行NetworkWordCount例子:
./bin/run-example streaming.NetworkWordCount localhost 9999
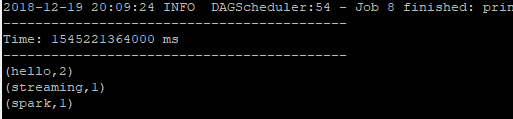
執行結果:
相關推薦
執行Spark官方提供的例子
去spark官網把spark下載下來: https://spark.apache.org/downloads.html 解壓,可以看下目錄: 其中examples目錄下提供了java,scala,python,R語言的各種例子。點進src目錄可以看到原始碼,如:
spark學習-執行spark on yarn 例子和檢視日誌.
要通過web頁面檢視執行日誌,需要啟動兩個東西 hadoop啟動jobhistoryserver和spark的history-server. 相關配置檔案: etc/hadoop/mapred-site.xml <!--配置jobh
[Spark][Python][DataFrame][SQL]Spark對DataFrame直接執行SQL處理的例子
hdfs temp div python people data name where afr [Spark][Python][DataFrame][SQL]Spark對DataFrame直接執行SQL處理的例子 $cat people.json {"name":"
《Spark官方文件》在YARN上執行Spark
原文連結 Spark在 0.6.0版本後支援在YARN(hadoop NextGen)上執行,並且在後續版本中不斷改進。 在YARN上啟動Spark 首先,確認 HADOOP_CONF_DIR或YARN_CONF_DIR指向的包含了Hadoop叢集的配置檔案。這些配置用於操作HDFS和連線Y
《Spark 官方文件》在Amazon EC2上執行Spark
在Amazon EC2上執行Spark Spark的ec2目錄下有一個spark-ec2指令碼,可以幫助你在Amazon EC2上啟動、管理、關閉Spark叢集。該指令碼能在EC2叢集上自動設定好Spark和HDFS。本文將會詳細描述如何利用spark-ec2指令碼來啟動和關閉叢集,以及如何在叢集提交作業。
《Spark 官方文件》在YARN上執行Spark
在YARN上執行Spark 對 YARN (Hadoop NextGen) 的支援是從Spark-0.6.0開始的,後續的版本也一直持續在改進。 在YARN上啟動 首先確保 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 變數指向一個包含Hadoop叢集客戶端配置檔案的目錄。這些配置用於
《Spark 官方文件》在Mesos上執行Spark
spark-1.6.0 [原文地址] 在Mesos上執行Spark Spark可以在由Apache Mesos 管理的硬體叢集中執行。 在Mesos叢集中使用Spark的主要優勢有: 可以在Spark以及其他框架(frameworks)之間動態劃分資源。 可以同時部署多個Spark例項,且各
Intellij IDE+ Spark 2.4 例子執行(原始碼斷點跟蹤)
上一篇文章寫了如何通過Maven編譯原始碼,該篇說明如何在IDE中引入專案,並執行其中一個例子。 要求:IDE中安裝了Scala外掛 一、開啟IDE,並加入專案,按如下操作 Menu -> File -> Open -> {spa
Spark官方文檔: Spark Configuration(Spark配置)
spark官方文檔: spark configuration(spark配置)Spark官方文檔: Spark Configuration(Spark配置)Spark主要提供三種位置配置系統:環境變量:用來啟動Spark workers,可以設置在你的驅動程序或者conf/spark-env.sh 腳本中;j
[Spark][Python]Spark Join 小例子
ont nta text read null json corrupt led park [[email protected] ~]$ hdfs dfs -cat people.json {"name":"Alice","pcode":"94304"}{"nam
Spark官方調優文檔翻譯(轉載)
區域 ng- 完整 好的 java類型 int 單個 rdd 常見 Spark調優 由於大部分Spark計算都是在內存中完成的,所以Spark程序的瓶頸可能由集群中任意一種資源導致,如:CPU、網絡帶寬、或者內存等。最常見的情況是,數據能裝進內存,而瓶頸是網絡帶寬;當
iview國際化問題(iview官方提供的兼容[email protected]+使用組件報錯)
IE 報錯 9.png IV mage 現在 兼容 配置 參考 問題描述: 按照iview官方的說法配置i18n發現在使用組件的時候會報錯。 兼容 [email protected]+的配置如下圖 報錯如下圖 解決方法: 經過參考element-ui的國際化配
Spark官方文檔翻譯(一)~Overview
安裝 pre mac os home 翻譯 size ber uri ems Spark官方文檔翻譯,有問題請及時指正,謝謝。 Overview頁 http://spark.apache.org/docs/latest/index.html Spark概述 Apac
windows系統上執行spark、hadoop報錯Could not locate executable null\bin\winutils.exe in the Hadoop binaries
1.下載 winutils.exe:https://download.csdn.net/download/u010020897/10745623 2.將此檔案放置在某個目錄下,比如C:\winutils\bin\中。 3.在程式的一開始宣告:System.s
java執行緒、定時例子
-- java的執行緒: package com.test; import java.util.Date; import java.util.Timer; import java.util.TimerTask; import java.util.concurrent.Executors; im
eclipse執行spark的scala程式console配置日誌log4j輸出級別
預設輸出info級別,結果都淹沒在info海洋裡 先看看自己的eclipse輸出的第一行 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 然後再找找spark的import
Hadoop執行mapre官方程式例項
1、執行grep案例,grep是官方提供的搜尋檔案中的單詞的出現次數 根據正則表示式來進行搜尋 1.1進入share目錄下的hadoop/mapreduce目錄環境,可以看到可以執行
以yarn client和分散式叢集方式執行spark-2.3.2-bin-hadoop2.6
一以分散式叢集執行 修改配置檔案/hadoop_opt/spark-2.3.2-bin-hadoop2.6/conf/spark-env.sh export HADOOP_CONF_DIR=/hadoop_opt/hadoop-2.6.1/etc/hadoop expo
對同一個物件繫結多個響應事件並都執行,和此例子的相容程式碼
要點: 1.因為 onclick=" " 新增的元素響應事件,先新增的事件,會被後來新增的事件層疊掉,只能執行最後一個響應的事件 所以要用到事件監聽addElementLitener()來繫結多個處理函式,而因為相容性的問題需要相容程式碼。 2.在IE8中,addE
在Yarn上執行spark-shell和spark-sql命令列
spark-shell On Yarn 如果你已經有一個正常執行的Hadoop Yarn環境,那麼只需要下載相應版本的Spark,解壓之後做為Spark客戶端即可。 需要配置Yarn的配置檔案目錄,export HADOOP_CONF_DIR=/etc/hadoop/conf &n