爬爬看:爬取西刺代理
阿新 • • 發佈:2018-12-19
關鍵字: 西刺代理 爬蟲 CSV檔案
前言
由於群裡一位水友的提問,我打算寫這份程式碼。
西刺網站的代理分為四種:高匿 、普通(透明) 、HTTPS 、HTTP 。
對應頁面的 URL 特徵是:nn 、nt 、wn 、wt 。
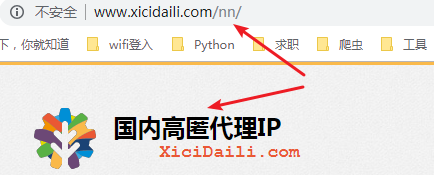
這裡,我們以 高匿代理 為爬取目標。
目標站點分析
檢視網頁 元素:
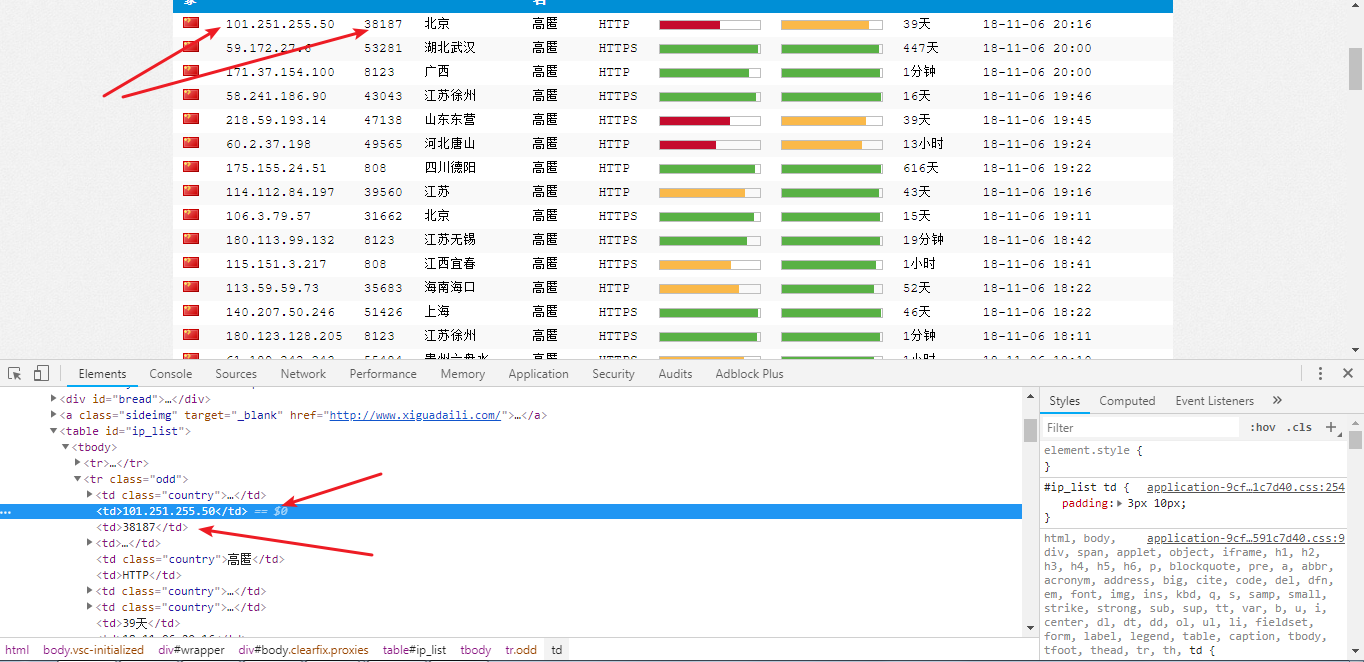
在標籤 <tr> 中我們發現了代理的 IP 地址和 埠 。
HTML下載器
def getHTML(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' HTML解析器
def parseHTML(html, pxyList):
pattern = re.compile('<tr class=".*?">.*?<td.*?</td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>' 解析 html 我會優先選擇正則表示式,因為正則解析真的很快。解析的代理引數用格式化輸出:

測試代理
def testPxy(pxyList):
pxy = [] #用於存放真正可用的代理
url = 'https://www.baidu.com/'
headers = { - 測試代理可不可用,我採用的方式是呼叫代理去訪問
baidu.com,如果返回的狀態碼是200,則代理是可用的。 - 最後呼叫
CSV庫把檔案儲存為CSV檔案。
全碼
import requests
import csv
import re
def getHTML(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
try:
r = requests.get(url, headers=headers)
if r.status_code == 200:
return (r.text)
except:
return ""
def parseHTML(html, pxyList):
pattern = re.compile('<tr class=".*?">.*?<td.*?</td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S)
data = re.findall(pattern, html)
for item in data:
pxyURL = "http://{0}:{1}".format(item[0], item[1])
pxyList.append(pxyURL)
def testPxy(pxyList):
pxy = [] #用於存放真正可用的代理
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
for item in pxyList:
try:
print("正在測試",item)
proxies = {
"https": item, # "https"的代理速度較慢
'http': item
}
r = requests.get(url, headers=headers, proxies=proxies, timeout=30)
if r.status_code == 200:
pxy.append(item)
except:
print( "代理無效", item)
with open('xichiProxies.csv', 'a', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(pxy)
def main():
pxyList = []
offset = 10 #爬取西刺高匿代理前十頁
for i in range(offset):
xcURL = 'http://www.xicidaili.com/nn/' + str(i+1)
html = getHTML(xcURL)
parseHTML(html, pxyList)
print(pxyList)
testPxy(pxyList)
main()
總結
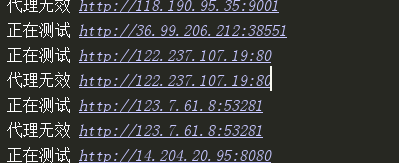
程式跑起來: