
爬取西刺網實現ip代理池
使用ip代理伺服器可以防止在爬蟲時被封本機ip。國內免費的高匿代理可以選擇西刺網
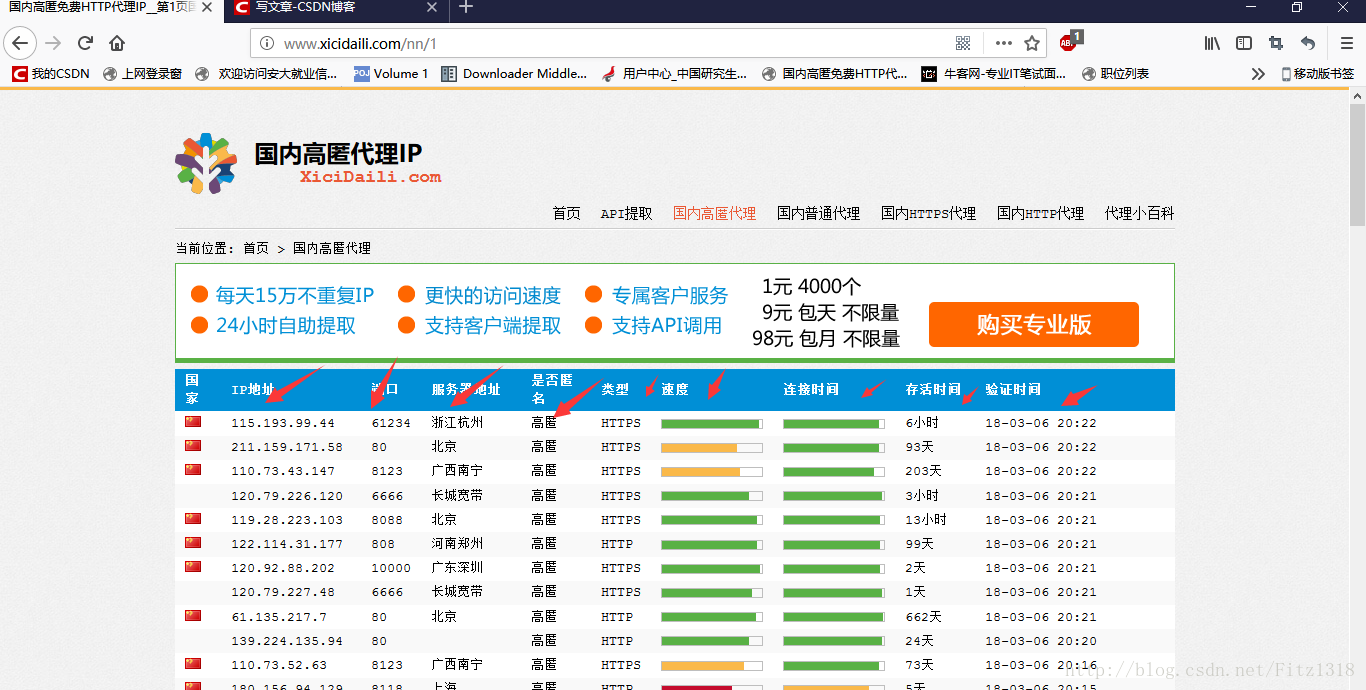
總體目標是寫一個爬蟲,將這些欄位儲存在資料庫中,然後篩選速度快的作為代理伺服器,實現ip代理池。
在這裡使用requests庫來實現。程式碼如下
import requests def crawl_ips(): #爬取西刺的免費高匿IP代理 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"} re = requests.get("http://www.xicidaili.com/nn", headers = headers) print(re.text) print(crawl_ips())
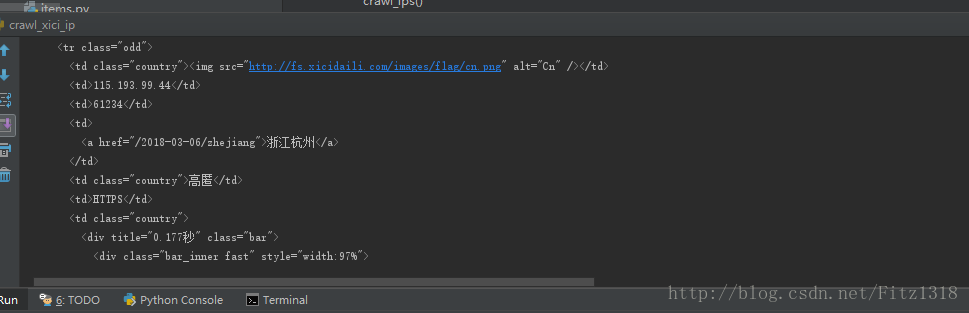
發現可以爬取到,接下來就是對爬到的資料進行解析入庫。
開啟web控制檯
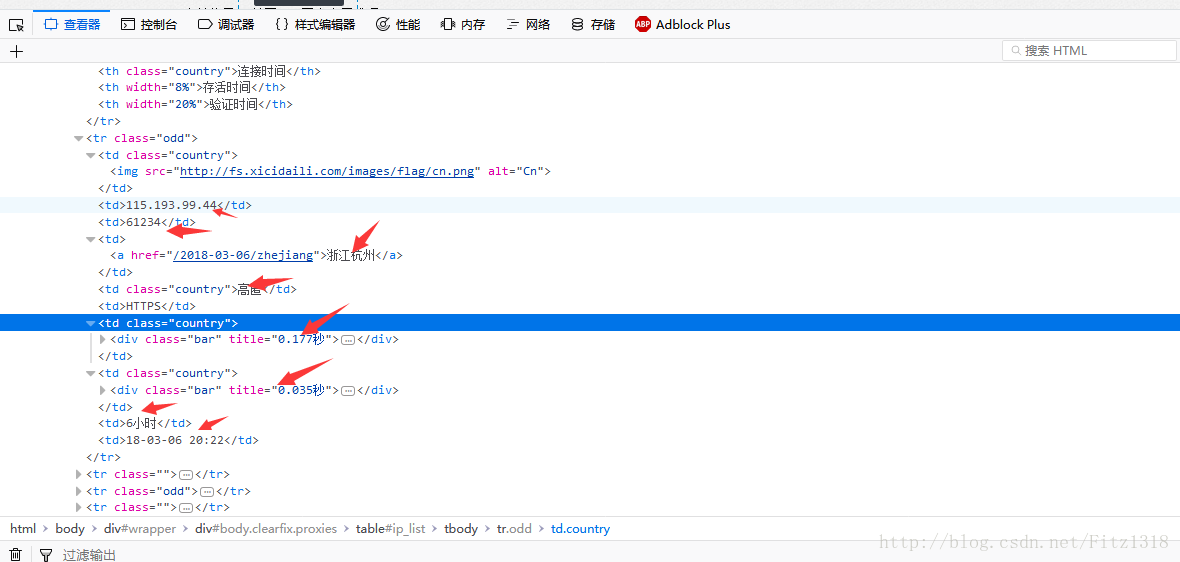
import requests from scrapy.selector import Selector def crawl_ips(): #爬取西刺的免費高匿IP代理 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"} re = requests.get("http://www.xicidaili.com/nn", headers = headers) selector = Selector(text=re.text) all_trs = selector.css("#ip_list tr") for tr in all_trs[1:]: speed_str = tr.css(".bar::attr(title)").extract()[0] if speed_str: speed = float(speed_str.split("秒")[0]) all_texts = tr.css("td::text").extract() print(all_texts) print(crawl_ips())
打斷點測試
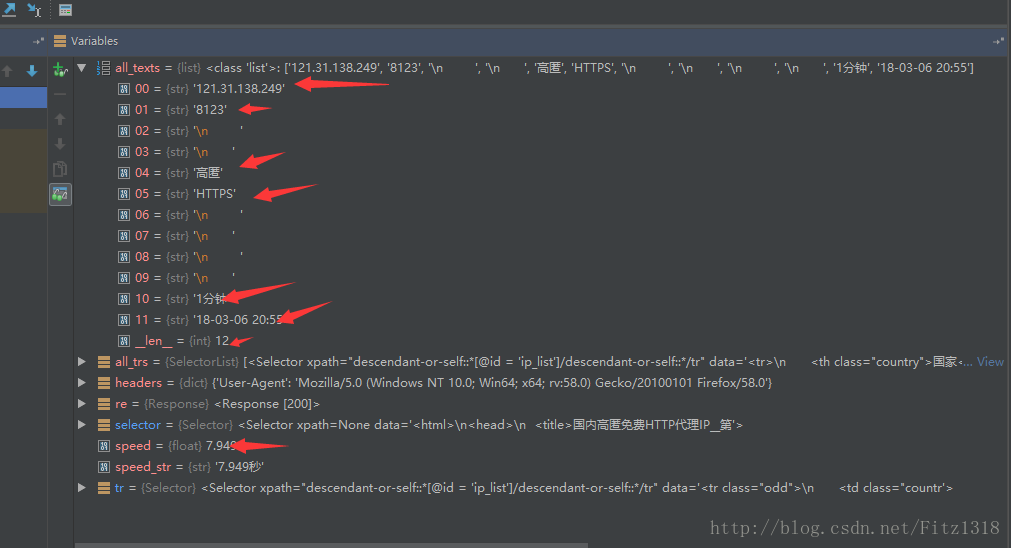
然後根據這個提取。
程式碼如下
提取到了想要的結果import requests import re from scrapy.selector import Selector def crawl_ips(): #爬取西刺的免費高匿IP代理 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"} for i in range(1568): res = requests.get( "http://www.xicidaili.com/nn/{0}".format(i), headers=headers) selector = Selector(text=res.text) all_trs = selector.css("#ip_list tr") ip_list = [] for tr in all_trs[1:]: speed_str = tr.css(".bar::attr(title)").extract()[0] if speed_str: speed = float(speed_str.split("秒")[0]) all_texts = tr.css("td::text").extract() match_obj1 = re.match(".*'HTTPS'.*", str(all_texts)) match_obj2 = re.match(".*'HTTP'.*", str(all_texts)) proxy_type = "" if match_obj1: proxy_type = "HTTPS" elif match_obj2: proxy_type = "HTTP" ip = all_texts[0] port = all_texts[1] ip_list.append((ip, port, proxy_type, speed)) print(ip_list) print(crawl_ips())
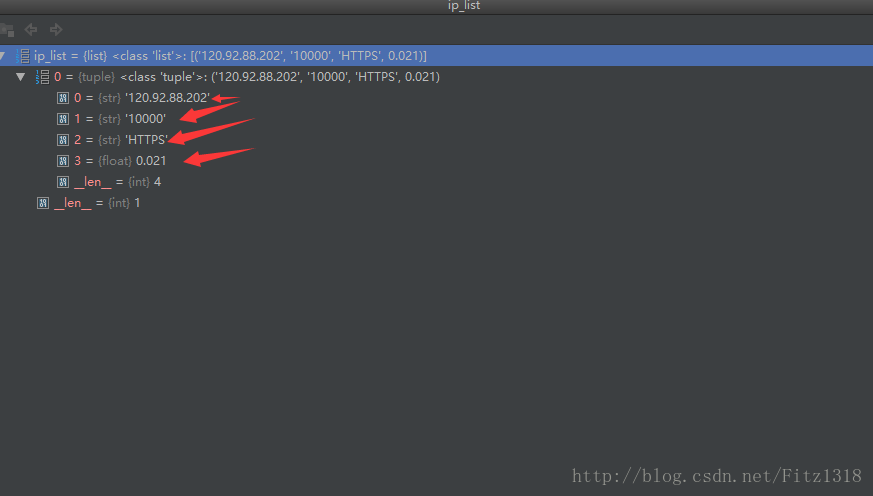
接下來就是將這些資料儲存到資料庫中。程式碼如下
import re
import requests
from scrapy.selector import Selector
import MySQLdb
conn = MySQLdb.connect(
host="localhost",
user="root",
passwd="1234",
db="jobbole",
charset="utf8")
cursor = conn.cursor()
def crawl_ips():
# 爬取西刺的免費ip代理
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"}
for i in range(1568):
res = requests.get(
"http://www.xicidaili.com/nn/{0}".format(i),
headers=headers)
selector = Selector(text=res.text)
all_trs = selector.css("#ip_list tr")
ip_list = []
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
match_obj1 = re.match(".*'HTTPS'.*", str(all_texts))
match_obj2 = re.match(".*'HTTP'.*", str(all_texts))
proxy_type = ""
if match_obj1:
proxy_type = "HTTPS"
elif match_obj2:
proxy_type = "HTTP"
ip = all_texts[0]
port = all_texts[1]
ip_list.append((ip, port, proxy_type, speed))
for ip_info in ip_list:
cursor.execute(
"insert xici(ip, port, speed, proxy_type) VALUES('{0}', '{1}', {2}, '{3}')".format(
ip_info[0], ip_info[1], ip_info[3], ip_info[2]))
conn.commit()可是問題來了,如下圖所示,資料庫連線成功了,可是卻進不去def crawl_ips()這個函式裡面。
相關推薦
爬取西刺網實現ip代理池
使用ip代理伺服器可以防止在爬蟲時被封本機ip。國內免費的高匿代理可以選擇西刺網總體目標是寫一個爬蟲,將這些欄位儲存在資料庫中,然後篩選速度快的作為代理伺服器,實現ip代理池。在這裡使用requests庫來實現。程式碼如下import requests def crawl_i
利用java-maven程式爬取西刺網頁的ip代理
主要程式碼: package com.itquwei.spider; import java.io.IOException; import java.nio.charset.Charset; import org.apache.http.HttpEntity; import org.a
爬資料時?IP老被封?這樣就不會被封了!爬取西刺代理IP並驗證
胡蘿蔔醬最近在爬取知乎使用者資料,然而爬取不了一會,IP就被封了,所以去爬取了西刺代理IP來使用。 這裡爬取的是西刺國內高匿IP。我們需要的就是這一串數字。 進群:548377875&nbs
建立自己的IP代理池[爬取西刺代理]
一:基本引數和匯入的包 import requests import re import random url = 'http://www.xicidaili.com/nn' headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)
python3 抓取西刺網免費代理IP並驗證是否可用
爬取西祠網免費高匿代理IP並驗證是否可用存到csv檔案 #匯入模組 import requests import chardet import random from scrapy.selector import Selecto
爬取西刺代理IP存入本地txt檔案作為代理IP池(未加入是否可用驗證)
執行環境:Python3.5.3、Windows 10 RS4、Pycharm 2017.2.4 前言 我們在爬取資料時,經常會因為請求太過頻繁導致反爬機制生效,不少伺服器的反爬機制
scrapy爬取西刺網站ip
close mon ins css pro bject esp res first # scrapy爬取西刺網站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem clas
爬取西刺代理
spider: # -*- coding: utf-8 -*-import scrapyfrom collectip.items import CollectipItemclass XiciSpider(scrapy.Spider): name = 'xici' allowed_domains
爬爬看:爬取西刺代理
關鍵字: 西刺代理 爬蟲 CSV檔案 前言 由於群裡一位水友的提問,我打算寫這份程式碼。 西刺網站的代理分為四種:高匿 、普通(透明) 、HTTPS 、HTTP 。 對應頁面的 URL 特徵是:nn
爬取西刺ip的插入資料庫相關問題
今晚解決了前幾天爬取西刺ip網不能插入資料庫的問題,成功爬取並插入資料庫的程式碼如下# encoding: utf-8 import re import requests from scrapy.selector import Selector import MySQLdb
python:使用requests,bs4爬取西刺代理並驗證
爬西刺代理的高匿免費代理,並通過http://www.baidu.com進行驗證代理是否可用,存入到excel檔案中 檢視原始碼發現: 所有的代理資訊都在tr標籤裡面(只有一個例外) 找到所有裡面有td標籤的tr標籤 trs = soup.find_
python:多執行緒抓取西刺和快站 高匿代理IP
一開始是打算去抓取一些資料,但是總是訪問次數多了之後被封IP,所以做了一個專門做了個工具用來抓取在西刺和快站的高匿IP。 執行環境的話是在python3.5下執行的,需要requests庫 在製作的過程中也參考的以下網上其他人的做法,但是發現很大一部分都不是多執行緒去抓取有點浪費時間了,又或者
python 爬蟲 獲取西刺網免費高匿代理ip
import chardet import requests from scrapy.selector import Selector import random from telnetlib import Telnet ip_list = [] def g
從西刺網獲取可用的代理IP
import requests import chardet import random from scrapy.selector import Selector from telnetlib import Telnet url = 'http://www.
Java網路爬蟲(七)--實現定時爬取與IP代理池
定點爬取 當我們需要對金融行業的股票資訊進行爬取的時候,由於股票的價格是一直在變化的,我們不可能手動的去每天定時定點的執行程式,這個時候我們就需要實現定點爬取了,我們引入第三方庫quartz的使用: package timeutils; imp
python網路爬蟲實戰——實時抓取西刺免費代理ip
參考網上高手示例程式,利用了多執行緒技術,Python版本為2.7 #-*-coding:utf8-*- import urllib2 import re import threading import time rawProxyList = [] checkedPr
Scrapy抓取西刺高匿代理ip
如題:因為想試試代理ip,所以就想著在西刺上爬一些ip用用 如上兩節所示,具體如何建立Scrapy工程的細節不在贅述。 scrapy startproject xici scrapy genspider xici http://www.xicidail
用Python多線程實現生產者消費者模式爬取鬥圖網的表情圖片
Python什麽是生產者消費者模式 某些模塊負責生產數據,這些數據由其他模塊來負責處理(此處的模塊可能是:函數、線程、進程等)。產生數據的模塊稱為生產者,而處理數據的模塊稱為消費者。在生產者與消費者之間的緩沖區稱之為倉庫。生產者負責往倉庫運輸商品,而消費者負責從倉庫裏取出商品,這就構成了生產者消費者模式。 生
用selenium以外的方法實現爬取海報時尚網熱門圖片
廢話不多說, 直接上程式碼! ! ! import json import os import time from urllib.request import urlretrieve import requests import datetime import urllib.parse
python爬取身份證資訊、爬取ip代理池
匹配的分類 按照匹配內容進行匹配 我們在匹配的過程當中,按照要匹配的內容的型別和數量進行匹配 &nb