
Low-shot Visual Recognition by Shrinking and Hallucinating Features
3個組成
It employs a learner, two training phases, and one testing phase.
1. learner
The learner is assumed to be composed of a feature extractor and a multi-class classifier.
2. traing phased one (representation learning)
During representation learning (training phase one), the learner receives a fixed set of base categories , and a dataset D containing a large number of examples for each category in Cbase. The learner uses D to set the parameters of its feature extractor.
產生新的類別
Any two examples z1 and z2 belonging to the same category represent a plausible transformation. Then, given a novel category example x, we want to apply to x the transformation that sent z1 to z2. That is, we want to complete the transformation “analogy” z1 : z2 :: x : ?.
We do this by training a function G that takes as input the concatenated feature vectors of the three examples [φ(x), φ(z1), φ(z2)].G是MLP
3. second phase (low-shot learning)
the learner is given a set of categories that it must learn to distinguish. = is a mix of base categories Cbase, and unseen novel categories Cnovel. 對於,僅僅有k-shot
4.testing phase
the learnt model predicts labels from the combined label space = on a set of previously unseen test images.
模型(Learning to generate new examples)
核心: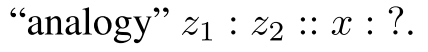 ,通過z1:z2,類比x:?.
,通過z1:z2,類比x:?.
利用D訓練G, 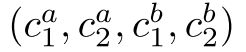 為用於類比的2組雙胞胎。預測結果為:
為用於類比的2組雙胞胎。預測結果為: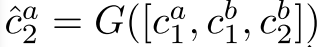 。損失函式
。損失函式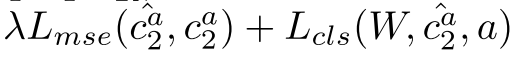 。與上文中的特徵表達誤差與分類誤差對應。
。與上文中的特徵表達誤差與分類誤差對應。