
用於說話人驗證的非線性i-vectors的研究
An Investigation of Non-linear i-vectors for speaker verification
陳南新,Jesu的Villalba,Najim Dehak
語言和語音處理中心約翰霍普金斯大學,馬里蘭州巴爾的摩
{bobchennan,jvillal7,ndehak3} @ jhu.edu
摘要
由於語音助理和智慧家居的普及,說話者驗證變得越來越重要。 i-vector廣泛用於該主題,其使用因子分析來模擬高斯混合模型中的平均引數的偏移。最近深度學習的進展,高水平的非線性改善了許多領域的成果。在本文中,我們提出了一個新的i-vector框架,它使用隨機梯度下降來解決i-vector問題。根據我們的初步結果,隨機梯度下降可以獲得與期望最大化演算法相同的效能。然而,通過反向傳播,假設可以更靈活,因此在我們的框架中可以進行線性和非線性假設。根據我們的結果,最大後驗估計和最大似然導致比傳統i-vector略好的結果,並且線性和非線性系統具有相似的效能。
索引術語:說話人驗證,生成模型,隨機梯度下降
1.簡介
隨著智慧手機和家庭使用者的日益普及,語音相關技術越來越受到學術界和業界的關注。 雖然語音識別效能不斷提高,但現在人們開始更多地關注隱私問題。 鑑於個人資訊通常與這些硬體共享,一個自然的問題是我們如何使其安全。 說話者驗證成為一種自然選擇,並在許多家庭助理中變得普遍。 揚聲器驗證系統根據其生理特徵區分不同的揚聲器,並回復相應的使用者。
演講者驗證研究歷史悠久。從20世紀開始,高斯混合模型通用背景模型(GMM-UBM)在[1]中被提出,實現了很好的效能。 UBM模型在大型語料庫上進行訓練,以模擬說話者獨立的語音特徵分佈。然後,使用Maximum a posteriori使GMM引數適應任何特定的說話者。後來,聯合因子分析(JFA)[2,3]提高了GMM-UBM系統的效能。 JFA假設說話者變異空間之間和之內的排名較低。雖然JFA假設頻道和發言人的因素不同,但以下研究表明,即使是頻道因素也有與發言人相關的資訊,可以提高整體表現。 2011年,Dehak等人。 [4]提出了一個簡化的框架,廣義上稱為i-vector,使用由總變差矩陣定義的單因子。總變異係數(i-vector)的點估計被用作其他分類器的新特徵,例如,概率線性判別分析(PLDA)[5]用於做出相同/不同的說話者決策[6,7] ]
最近,隨著深度學習技術的出現,更多的研究[8,9,10,11,12,13,14,15,16]轉而使用神經網路來模擬說話者的變異性。在[8,9]中,神經網路用於取代GMM-UBM模型中的GMM,以提供對齊和統計。在[11]中,從神經網路中提取瓶頸特徵,使GMM得到更好的無監督聚類特徵空間改善結果。後來,提出了不同的工作來直接使用神經網路進行說話人驗證[10,12,13,14,15,16]。這些網路需要接受大量資料的培訓,通常使用監督學習,並且在文字相關[10,12,13,14,15]和文字無關[16]說話者驗證方面表現出很好的表現。
在本文中,我們提出了一個將傳統i-vector與神經網路相結合的新框架。更具體地,提出了推廣i-vector的生成模型,並且我們證明了i-vector是我們新框架的特例。基於反向傳播的隨機梯度下降用於訓練模型引數並推斷潛在因子。在這個新框架中表示i-vector時,我們可以為i-vector新增非線性。我們對SRE16的初步結果表明
•最小分歧估計有助於推理
•線性和非線性系統的效能類似
•最大後驗和最大似然都可以略微改善常規i-vector的結果
本文的結構如下。第2節介紹了傳統的i-vector系統和提出的新的i-vector框架。第3節報告了i-vector基線系統的結果,並探討了不同的因素:最小偏差估計,非線性,最大似然估計和最大後驗估計。第4節總結了論文併為未來的研究提供了指導。
2.i-vector和非線性i-vector
2.1.i-vectors
i-vector框架將話語特徵建模為高斯混合模型(GMM)。 話語依賴GMM超向量的轉換意味著w.r.t. 假設通用背景模型是
m = M + Tw(1)
其中M是原始UBM平均值,T是低維矩陣對映到高維超向量空間的低維i-vector。 超向量是所有平均引數的串聯。 T通常稱為總可變性矩陣。
期望最大化用於訓練UBM和i-vector模型引數。 在將i-vector提取為固定維度嵌入之後,可以使用餘弦相似性和概率線性判別分析[5]。
2.2.非線性i-vector
2.2.1.Model定義
在這個工作中,就像在i-vector框架中一樣,我們假設話語特徵是由GMM生成的,
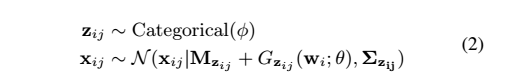
其中xij是來自話語i的幀j,zij是高斯職業的單熱向量,並且φ是混合權重。 tt是將潛在因子w對映到話語依賴的超向量均值和UBM均值之間的偏移的一般函式。
常規的i-vector可以被認為是
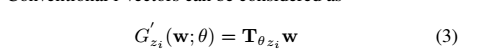
這是等式(2)的特例。 但是,在這項工作中,我們嘗試向函式tt新增非線性。 一個自然的想法是直接將啟用函式新增到Tθ和w的乘積:
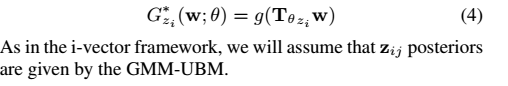
2.2.2.Theory
提出的框架背後的理論可以更一般。 我們想要模擬觀察到的變數之間的連線X-給定話語的特徵幀和潛在變數w。 在生成環境中,我們希望在給定模型引數θ,log p(Xθ)的情況下最大化觀測資料X的邊際可能性。 然而在實踐中,這在大多數情況下是難以處理的。 因此,我們最大化了下限(ELBO),而不是



在我們的例子中,我們關心如何找到最佳μ。由於X包含可變數量的幀,所以我們需要設計某種複雜的機制來將所有幀的資訊累積到唯一的潛在因子w中,因此模擬潛在的後p(w X)是困難的。然而,類似於稀疏編碼,我們將其視為優化問題,這簡化了問題。我們提出假設μ是我們通過反向傳播獲得的可訓練引數,而不是使用閉合形式函式來獲得μ,如在變分自動編碼器框架[18]中提出的那樣。以這種方式,不需要編碼器功能,只需要解碼器分配p(X w)。採用GMM-UBM作為解碼器以與i-vector進行比較。相同的UBM在相同的資料集上進行訓練,並用於i-vector和我們的方法。
整個過程的圖表如圖1所示。在每個小批量中,我們根據UBM模型計算每個高斯分佈的響應。然後根據小批量中的資料X收集所有嵌入,並通過函式tt更新UBM的超級向量。損失值由資料X和更新的UBM計算。在向後,從損失值開始,通過遞迴計算θ和w的梯度。在每個小批量中,我們在這個小批量中更新了θ和相應的w。在推理(i-vector提取)中,僅更新μ而θ固定。
雖然我們的方法是基於小批量的訓練,但我們想強調EM演算法和SGD之間的相似之處。 SGD一般可以看作是EM的一個特例。在每個小批量中,我們優化w在前一批中給定θ,並且我們優化θ給出最後w。即使每個小批量也無法提供準確的梯度資訊,並且步長相對較小,如果有足夠的更新,系統應該收斂到類似的點。
2.2.3.損失功能
在這項工作中,我們根據公式(8)考慮兩個損失函式:

總共有41859個話語。 表1列出了更多資料細節。
所有框架均在NIST SRE 2016評估(SRE16)的粵語部分進行測試。 入學話語包含大約60秒的會話電話講話,而測試話語在10-60秒之間變化。 我們從NIST SRE16開發集“主要”資料中估計了i-vector的平均值,並使用它來集中所有i-vector以用於登記和測試資料。
3.2Experiments setup
在整個訓練集上訓練UBM模型,並且在所有實驗中使用對角協方差。 使用Kaldi訓練UBM模型和i-載體基線[21]。
使用MAP估計的不同對角高斯數的400維i-向量基線的結果在表2中給出。從表中可以看出,更高斯的人得到更好的結果,但差異並不大。 由於GPU記憶體限制,我們使用256高斯UBM來測試我們的方法。
在下文中,我們將介紹用於建立我們在隨機反向傳播演算法中使用的小批量的方法。由於獨立性假設,我們可以在不改變模型的情況下改變每個話語中的幀。通過改組框架,我們增加了用於訓練模型的特徵塊的可變性。眾所周知,增加隨機性有利於使深度模型很好地推廣。之後,我們將每個話語分成小塊,其中每個塊包括128幀。在將它們喂入我們的模型之前,所有這些塊都在每個時代進行了洗牌。每個小批量包含200個塊。根據我們的觀察,每個小批量的塊大小和塊數都對最終效能非常重要。第一個決定w的精確梯度,第二個決定小批量的會話間可變性。在訓練中,學習率設定為0.001,並使用Adam [22]。對於推理,學習率設定為0.005,並且使用10次迭代來找到最優w。為了公平比較,我們還將w設定為400維嵌入。對於i-vector和非線性i-vector,採用概率線性判別分析(PLDA)作為後端。
3.3.結果
3.3.1.最小分歧估計的影響
如2.2.3節所述,最小偏差估計用於減少Tθ尺度與w方差之間不平衡的影響。 結果列於表3中。
顯然,從表中最小分歧估計是有幫助的,甚至學習率可以手動設定為非常小的數字(如表中的0.0005),最小分歧估計仍然可以改善結果。 這與我們從標準i-vector實踐中所知道的一致。
3.3.2.線性與非線性的比較
對於非線性,引數整流線性單元[23]被採用為等式(4)中的函式g:


3.3.3.最大似然估計估計(MLE)和最大後驗(MAP)估計之間的比較
MLE和MAP估計之間的唯一區別是等式(8)中的先驗的權重。 表5報告了MLE和MAP的結果。 從表中可以明顯看出,MAP估計具有與ML估計相似的效能。 然而,隨著先前項p(w =μ)的引入,w更接近標準正態分佈,這減少了最小偏差估計的相對改進。 我們進一步繪製了MLE和MAP訓練中隨機選擇維度的分佈圖,如圖2所示。與MLE相比,圖中w往往與MAP中的標準法線具有相似的分佈。 總而言之,最大似然估計提供了更好的決策成本函式(DCF),而最大後驗估計導致更好的相等錯誤率(ERR)。
4.結論
在本文中,我們提出了一種新的基於隨機的非線性i-vector系統。所提出的模型遵循UBM方法,與i-vector相同。然而,它推廣了i-vector,允許使用非線性函式將潛在因子(i-向量)對映到依賴於話語的GMM超向量均值。在這種模型中,估計潛在因子或模型引數是難以處理的。然而,我們可以採用在變分自動編碼器中使用的類似方法[18],其中模型引數通過隨機反向傳播獲得,潛在因子由深度神經網路計算。在我們的框架中,我們建議使用隨機反向傳播來計算潛在因子和模型引數。在訓練階段,模型引數和潛在因素進行了估計。同時在評估階段 - 當獲得註冊和測試i-vector時 - 模型引數是固定的。
我們使用線性和非線性解碼器對此框架進行了實驗,以計算GMM平均值。我們在SRE16上的實驗表明,我們的MLE和MAP訓練框架比傳統的i-vector導致略好的結果。然而,非線性假設並沒有真正改善結果。進一步的工作包括通過允許每個維度的不同非線性來擴充套件非線性,以及同時調整不同的引數。
