
關於聯合喚醒詞檢測和文字相關說話人驗證的卷積LSTM建模
On Convolutional LSTM Modeling for Joint Wake-Word Detection and Text Dependent Speaker Verification




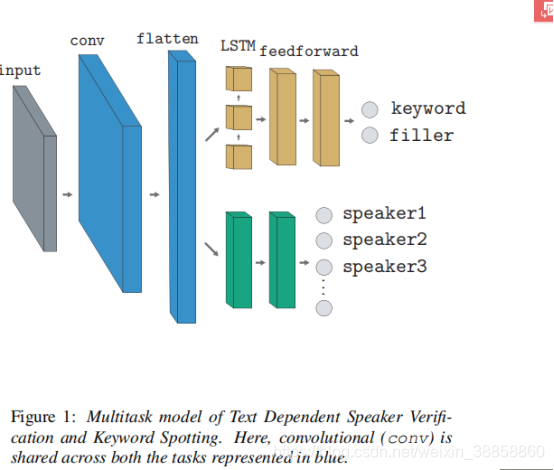

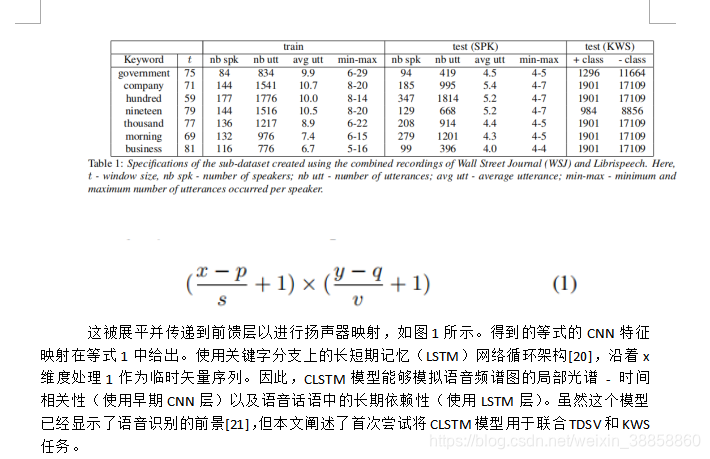

業務,公司,政府,百萬,早晨,十九和一千個被選中,並且形成了包含所考慮的每個關鍵詞的記錄的子資料集。每個子資料集的規格列於表中。這裡,提到的說話人驗證任務的測試資料是註冊和測試話語的組合,是一個保持不變的集合。從這個保留的測試資料集中隨機選擇每個發言者的註冊話語。對於關鍵字定位喚醒任務,在評估期間也會將沒有關鍵字的句子新增到測試資料中(以準確地測量誤報率)。但是,表1中列出的列車資料在所有實驗中都保持不變。對於TDSV,僅從列車資料中挑選關鍵字的語音段,而考慮整個資料集用於KWS。
4.2.Training
我們使用固定批量大小128和隨機梯度下降與動量演算法進行優化任務。 具有指數衰減[23]的粗體駕駛員學習速率引數的方法按以下方式進行調整 - 如果驗證集上的精度在一個紀元後減小,則恢復上一紀元的權重和學習速率 減半。 即使在降低學習率三次之後,如果準確度沒有提高,訓練過程也會停止。 所有實驗的初始學習率保持在0.02。 使用交叉熵作為損失函式。
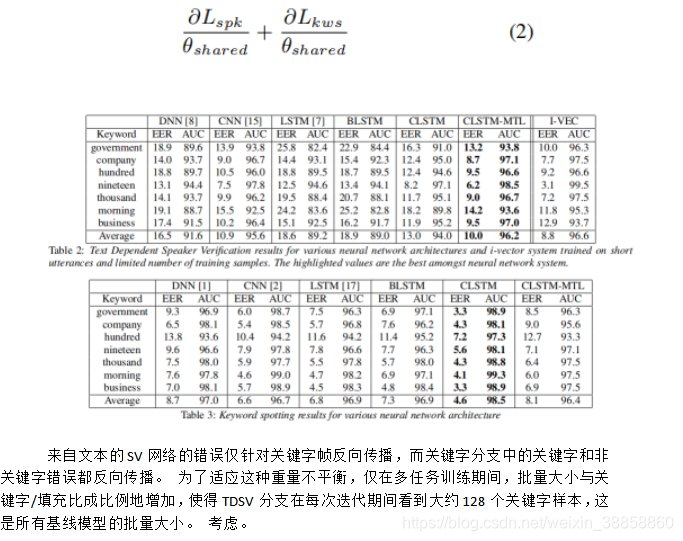
在多工網路中,共享層中的梯度如下所示,
5.Results
為了完整起見,本文還實現了基於i向量的TDSV。使用512混合組件GMM-UBM匯出i向量特徵。接下來是維數減少到256維的總變數矩陣模型。
請注意,為了進行公平比較,所有模型都設計有大致相似的引數。在多個分支中,每個分支具有與其各自基線相同的引數。表2中報告了TDSV的各種NN架構的結果。在用於說話者驗證的神經網路架構中,前饋和重複架構表現最差。卷積神經網路模型[15]在捕獲說話人特定功能方面最為有效。雖然獨立的CLSTM模型表現不佳,但共享較低級別的語音功能已證明是有益的,並且效能優於CNN模型。表格最後一欄中顯示的i-vector模型進一步改進了神經網路架構。這也驗證了先前使用相同的線條進行的觀察,將神經網路架構與用於少量訓練資料的i向量模型進行比較[9]。
在KWS喚醒字檢測的情況下,迴圈架構顯示出對前饋模型的顯著改進。 CLSTM模型在所考慮的各種NN模型中提供最佳的KWS精度。與基於LSTM框架的先前模型相比,所提出的CLSTM模型實現了30%的平均相對改進[17]。與說話人驗證模型的結果相反,MTL框架並未改進CLSTM架構。這可能歸因於這樣的事實:保留說話者資訊可能正在稀釋KWS任務的目標,該目標試圖匯出關鍵字而不管目標說話者。
綜上所述,
•迴圈LSTM架構最適合語音和字分類,而卷積架構適用於揚聲器和語音功能。
•卷積前端功能圖與逆流架構相結合,適合學習共享功能(揚聲器和語音)。
•MTL框架與CLSTM模型相結合,為語音資訊的知識提供了顯著的益處,其中語音資訊的知識有助於說話者聚類。但是,MTL中的發言者資訊對KWS任務沒有好處。
•使用少量揚聲器訓練資料的神經網路方法的效能不如TDSV任務中的i-向量特徵。
六,結論
最後,我們研究了各種用於文字相關的說話者驗證和關鍵詞識別的神經網路架構,並提出了一個具有卷積前端的多工架構。 我們還演示了為說話人驗證任務學習語音和說話人特徵的共享特徵表示的有效性。