
Spark專案之環境搭建(單機)三 scala-2.12.7+ spark-2.3.2-bin-hadoop2.7安裝
阿新 • • 發佈:2018-12-20
上傳scala和spark架包


解壓然後重新命名
tar -zxf scala-2.12.7.tgz
mv scala-2.12.7 scalatar -zxf spark-2.3.2-bin-hadoop2.7.tgz
mv spark-2.3.2-bin-hadoop2.7 spark然後配置scala 和spark的環境變數:
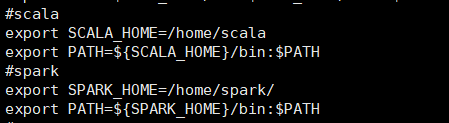
vi /etc/profile#scala export SCALA_HOME=/home/scala export PATH=${SCALA_HOME}/bin:$PATH #spark export SPARK_HOME=/home/spark/ export PATH=${SPARK_HOME}/bin:$PATH
然後載入環境變數
source /etc/profile然後輸入scala
scala成功結構如下

進入spark 的conf裡面拷貝一個,現在我只配置單機可執行的即可。
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves加入以下配置:
vi spark-env.sh#java export JAVA_HOME=/home/jdk #scala export SCALA_HOME=/home/scala #Spark主節點的IP export SPARK_MASTER_IP=hadoop #Spark主節點的埠號 export SPARK_MASTER_PORT=7077
HADOOP_CONF_DIR這個hadoop的配置讀取檔案,我並沒有配置,所以在寫程式碼讀取hadoop的資料就需要加入地址。
然後進入spark/sbin目錄啟動spark:cd /home/spark/sbin
./start-all.shjps

然後再瀏覽器上輸入: 你spark安裝的IP:8080,我的IP是192.168.131.155,所以輸入 192.168.131.155:8080
