
An Industrial-Strength Audio Search Algorithm
轉載自:https://blog.csdn.net/yutianzuijin/article/details/49787551
隨著微信搖一搖逐漸被大眾所廣泛使用,聽歌識曲功能也開始被關注。目前來看,像音樂雷達和微信搖一搖都採用了經典的shazam演算法,為了使大家對shazam演算法更加了解,我將其經典論文進行了翻譯,希望對大家學習shazam演算法有所幫助。
一個企業級的音訊搜尋演算法
摘要
我們設計實現並實際部署了一套靈活性很高的音訊搜尋引擎。核心演算法抗噪聲和擾動能力強,計算複雜度低,同時具有很高的可擴充套件性。即使外界噪音很強,它也可以迅速地通過手機錄製的一小段壓縮音訊從百萬級的曲庫中辨識出正確的歌曲。演算法分析音訊頻域上的星狀圖來組合時間-頻率資訊構造雜湊。這種方式具有不尋常的優勢,例如它能將混合在一起的幾首歌都辨識出來。針對不同的應用,即使曲庫非常非常大,檢索速度也可以達到毫秒級。
1. 簡介
Shazam公司創立於2000年,最初的目的是方便使用者通過自己的手機檢索正在播放的歌曲。(為了達到很高的可用性,演算法必須具有下面幾個特性。)演算法必須能利用很短的音訊片段辨識出正確的歌曲。特別地,即使該音訊片段包含很強的噪音和擾動,並且經過各種損害性處理,例如壓縮和網路丟包等,演算法也需要準確地返回結果。此外,當曲庫規模達到200萬時演算法也需要很快地返回結果。返回的結果在保證高識別率的同時必須具有很低的假陽性(false positive)概率。
這是一個很難的問題,到目前為止還沒出現可以滿足上述要求的演算法,但是我們設計的演算法可以滿足上述要求[1]。
我們實際部署了一套曲庫規模達180萬的商用音樂識別服務。目前給德國、芬蘭和英國的50w使用者提供服務,很快就會覆蓋歐洲、亞洲的多個國家以及美國。使用方法很簡單:使用者聽到一首正在播放的歌曲,然後用手機錄製15秒的片段上傳到我們的伺服器,伺服器將歌手和歌名以簡訊的形式返回給使用者。使用者也可以通過網站訪問我們的服務,並可以根據返回的歌名購買相應的CD或者自行下載對應歌曲。
目前有不少類似的應用: Musicwave公司採用philips演算法[2-4]在西班牙部署了一套類似的系統。Neuros在他們的MP3播放器中內建了一個屬性,允許使用者擷取30s正在播放的音訊進行識別[5,6]。Audible Magic公司則採用Muscle Fish演算法識別網路廣播電臺中的音訊流[7-9]。
shazam演算法除了辨識歌曲之外還有很多其他應用。由於演算法抗噪能力強,例如,即使在廣告中有很大的說話聲,演算法也能正確識別出其中的背景音樂。另一方面,由於演算法非常快,還可以用來進行版權保護檢測,速度可以達到1000倍實時。這樣部署一臺中型伺服器就可以同時對多路音訊流進行檢測。shazam演算法也適用於基於內容的跟蹤和索引。
2. 演算法的基本原理
資料庫和錄製的音訊檔案都需要提取可復現的雜湊“令牌”,也即指紋。從未知音訊中提取的指紋需要和音樂庫中提取的海量指紋進行匹配。匹配上的指紋會用來衡量匹配的正確性。提取的指紋需要滿足幾個指導性原則:時間區域性性(temporally localized),轉換不變性(translation-invariant),魯棒性(robust)和指紋資訊量大(sufficiently entropic)。時間區域性性表示指紋是由時間上接近的音訊資料構造的,這樣較遠時刻的事件不會對該指紋產生影響(如果指紋是由時刻相距較遠的音訊資料構造的,則指紋會很不穩定,易受到外界噪音干擾)。轉換不變性表示提取的指紋必須和位置無關,並且是可復現的。這是因為使用者錄音可以從任意位置開始。魯棒性表示從“乾淨”音樂中提取的指紋也必須可以從含有各種噪音的音訊中復現。此外,指紋也必須要包含足夠的資訊以便減少錯誤位置的無用匹配。指紋包含的資訊量過少通常會導致冗餘繁瑣的匹配,從而浪費大量計算資源。但是,如果指紋包含的資訊量過多又會導致指紋的脆弱性,使指紋在噪音和失真環境下不能復現。
shazam演算法共有三個主要模組,下面分別進行介紹。
2.1 星狀圖
為了解決在噪音和失真情況下的音樂識別問題,我們嘗試了大量的特徵,最終選擇了“頻譜的極大值(spectrogram peaks)”。因為頻譜極大值(亦可稱為峰值)具有很強的抗噪能力,同時又具有近似的線性可加性[1]。頻譜上的極大值表示在給定的時頻區域內某個點的值大於所有的鄰居。在選擇候選極大值時需要滿足密度準則使選取的極大值在不同的時間段內能均勻分佈。在一個小的時間區間內選擇極大值也要保證選擇是最大值的極大值,因為最大值才最有可能在各種噪音和失真環境下保持不變(即最大值能在錄音前後保持不變,也就滿足指紋的健壯性)。
通過極大值選取,複雜的頻譜圖(1A)就簡化成了稀疏的極大值座標(1B)。需要注意一點,經過該步驟之後頻譜圖中的幅值資訊就丟失了(只利用時間和頻率資訊,不利用幅值資訊)。這種簡化操作具有對EQ(不清楚怎麼翻譯)不敏感的好處。因為一個極大值經過各種濾波之後依舊會是相同位置的極大值(假定濾波器傳遞函式的導數很小,也即訊號劇烈變化位置的峰值在經過傳遞函式之後只會引起輕微的頻率上下浮動)。我們將這些稀疏的座標稱為“星狀圖”,因為它們確實很像天空中的星星。
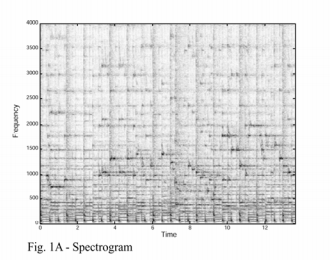
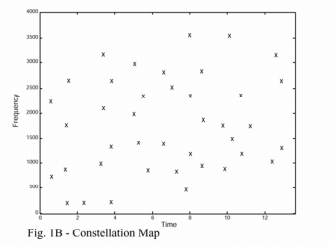
在要匹配的樣本中也會存在相同的星狀圖。如果將資料庫中某首歌的星狀圖散亂在一個條形圖上,然後將幾秒樣本的星狀圖放在一個透明的塑料板上。在條形圖上滑行塑料板(有點像遊標卡尺),到某個時刻的時候就會出現一件神奇的事情:當樣本和資料庫歌曲的正確位置對齊時,重疊的極大值就會格外多,這樣就意味著樣本和資料庫中正確音樂的正確位置匹配上了!
即使噪音導致樣本中存在很多虛假的極大值,但是由於極大值的位置都是相對獨立的,所以重疊的極大值點個數依舊非常多。另一方面,如果很多正確的極大值被刪掉了,也不影響重疊點的個數很多這個結論。所以星狀圖是噪音環境下音樂識別的一個利器,即使存在很多的虛假特徵或者刪除了過多的正確特徵,星狀圖都具有很好的魯棒性。通過星狀圖的使用,我們就將音樂識別問題簡化為一個“星際航行”問題,在該問題中我們需要根據一小段”時間-頻率”星狀圖快速定位它在長度可達10億秒的條形圖中的位置。Yang也考慮使用頻譜峰值作為特徵進行音樂識別,但是採用了不同的方式[10]。
2.2 快速組合雜湊
如果直接利用星狀圖來計算正確的偏移會非常緩慢,因為單個時頻點包含的資訊量很少。例如,頻率軸長度為1024時每個峰值至多產生10bit的頻率資訊(這就意味著相同頻率的峰值會非常多,從而影響匹配速度)。我們實現了一種快速索引星狀圖的方法。
索引的核心是將兩個時頻點組合在一起構成一個指紋雜湊。首先選擇錨點(anchor point),每個錨點都對應一個目標區域(target zone)。每一個錨點都按序和目標區域中的點進行組合,組合的結果是兩個頻率加一個時間差(圖1C和圖1D所示)。這種方式產生的組合雜湊具有很高的可復現性,即使噪音很強或者音訊進行過壓縮處理。此外,每一個指紋都可以存入一個int中(位數小於32)。每一個指紋都伴隨有一個從檔案開頭到該錨點的時間差,所以絕對時間不包含在指紋中(指紋中包含的時間差是兩個時頻點的時間差,是一個相對值;絕對的時間差作為伴隨屬性存在)。
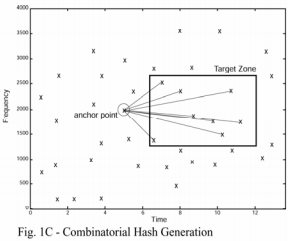
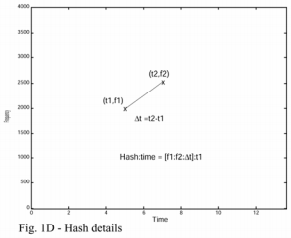
構造整個資料庫索引的過程就是在每首歌上執行上述構造步驟,從而產生一系列的指紋和對應的絕對時間差。歌曲ID也會新增到這個緊湊的資料結構中,生成一個64bit的結構體,其中32bit儲存雜湊值,32bit儲存時間差和歌曲ID。為了進行快速匹配,該結構根據雜湊值排序(可以理解為用高32位的雜湊值對上述結構進行排序)。
每秒產生的雜湊個數約等於星狀圖的密度乘以目標區域的外聯絡數(fan-out factor)(含義是星狀圖的每個點都要和目標區域中固定個數的點連線形成指紋)。例如,每個時頻點都是一個錨點,目標區域的外聯絡數F是10,則生成的雜湊個數約等於10倍的時頻點個數。通過限制外聯絡數,我們就可以限制最終生成指紋的個數。實際上,外聯絡數可以用來衡量儲存空間的耗費程度。
通過組合雜湊來代替單個時頻點的匹配會帶來巨大的效能提升。假設頻率軸為10bit,時間差也為10bit,則組合雜湊會產生一個30bit資訊量的指紋。與原始的匹配相比多出了20bit,從而使雜湊空間增大了100萬倍,匹配速度也相應地加快(這是因為匹配時產生的碰撞更少了)。另一方面,組合雜湊也會增大指紋的個數,資料庫中會增大F倍,檢索的時候樣本構造的指紋也會增大F倍,從而採用組合雜湊最終獲得的加速比為1000000/F2,大約為10000倍。
(組合雜湊也並非沒有壞處),它會使某個點存活的概率由p變為p2(就是概率變小)。假定p是頻率極大值點在原始訊號和錄製音訊中都存在的概率,組合雜湊也包含該極大值點的概率就為p2。速度的提升是以概率的降低為代價的。但是可以通過外聯絡數來減小概率的降低。假定F=10,則某個錨點至少存活一個雜湊的概率等於該錨點與其目標區域中至少有一個組合雜湊存活的概率。如果我們將目標區域中的點認為是獨立的,則某錨點至少有一個組合雜湊存活的概率為p*[1-(1-p)F]。對於很大的F(F>10)和合理的p(p>0.2),會存在
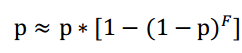
所以,組合雜湊加外聯絡數不會導致檢索準確率的大幅下降。
可以看出,通過採用組合雜湊,我們用10倍的空間獲得了10000倍的效能提升和輕微的準確率下降。
我們可以根據訊號源的噪音情況來決定外聯絡數大小和星狀圖的密度。比較乾淨的音訊,比如廣播監控,F值就可以選取得較小,星狀圖密度也可以很低(在該應用中,可以直接擷取廣播流,沒有環境噪音)。針對噪音很大的手機錄音,F值和星狀圖密度就需要適當大點。不同環境之間可能會產生幾個數量級的差異。
2.3 檢索和打分
在執行搜尋之前,需要先從錄音樣本中提取所有的雜湊值和時間偏移資訊。樣本中提取的雜湊都會用來和資料庫中的雜湊進行匹配。每一個匹配的雜湊會產生一個時間對:樣本中的時間和資料庫中的時間。根據對應的歌曲ID將時間對分類。
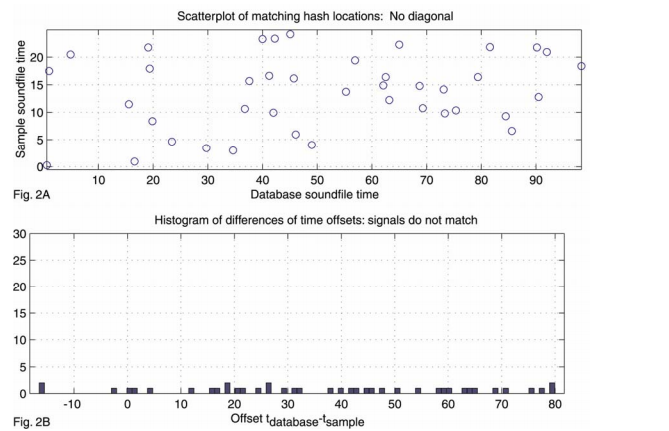
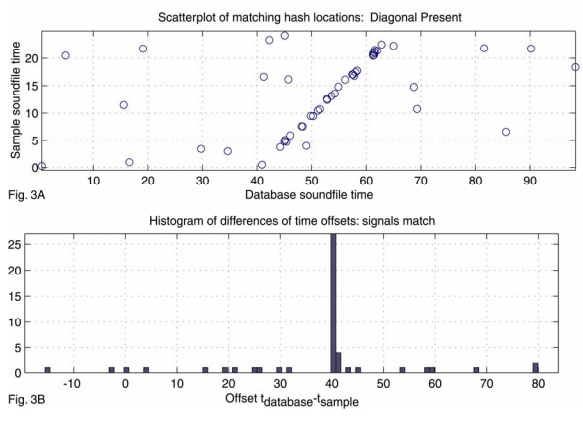
當樣本中提取的指紋都完成上述匹配之後,掃描時間對獲得正確的歌曲。每個歌曲對應的所有時間對構成了一個散點圖,如果歌曲和樣本匹配,則匹配上的特徵會有相近的相對時間偏移,也即樣本中提取的指紋和正確歌曲匹配上的指紋具有相同的相對時間(這個相對時間其實就是樣本在原始歌曲中的起始位置)。這樣就可以將搜尋問題簡化為散點圖中尋找明顯對角線的問題,該問題有很多現成的技術可以用,例如Hough變換或者其他迴歸技術。但是這些方法複雜度太高,同時對異常值比較敏感,所以不適用。
但是考慮到問題的特殊性,我們可以設計一個複雜度為N*logN的演算法,其中N表示散點圖中點的個數。不失一般性,假定對角線的斜率為1.0(錄音速度和原曲速度一致,絕大多數情況都是如此),則樣本和正確歌曲中匹配指紋的時間滿足下面的關係式:
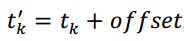
其中,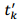
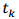
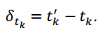
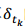 的直方圖並掃描獲得直方圖的最大值(其實就是將時間對的兩個時間相減,然後統計相同時間差個數的最大值)。
的直方圖並掃描獲得直方圖的最大值(其實就是將時間對的兩個時間相減,然後統計相同時間差個數的最大值)。
(其實就是將時間對的兩個時間相減,然後統計相同時間差個數的最大值)。求最大值可以通過掃描完成。由於組合雜湊的原因,散點圖通常會非常稀疏。同時每首歌對應的時間差個數通常很少,所以掃描過程會在幾微秒之內完成。每首歌對應的得分也即直方圖的最大值。如果直方圖的最大值很大,那就意味著該首歌就是要識別的正確歌曲。圖2A展示了一個錯誤匹配的例子,圖3A展示了一個正確匹配的例子。圖2B和圖3B分別表示圖2A和圖3A對應的時間差直方圖。
對每一首歌的時間對都執行上面的計算直到找到一個很明顯是正確的匹配。
需要注意的是上面介紹的匹配和掃描操作都沒有對雜湊的格式進行任何限制。實際上,雜湊值只需要包含足夠的資訊量來避免虛假匹配同時又具有可復現性即可。在掃描階段,只需要保證匹配的雜湊在時間上對齊即可。
2.3.1 置信度
如上所述,匹配的得分是具有相同時間差的指紋個數。在確定演算法false positive的過程中,錯誤歌曲的得分分佈也很重要。簡單概括一下,統計所有錯誤歌曲的得分獲得一個錯誤得分直方圖,同時根據資料庫中歌曲的數目生成一個錯誤得分的概率密度函式。我們之後就可以根據這個函式來設定可接受的false positive(根據不同的應用falsepositive可以設定為0.1%或者0.01%)。
3 效能
3.1 抗噪性
演算法在噪音很強或者非線性失真的情況下都表現良好,說話聲、汽車聲、片段丟失甚至其他正在播放的音樂都不影響最終的識別結果。利用shazam演算法,一段被破壞嚴重的15s片段也可以通過1~2%存活的雜湊獲得置信度非常高的匹配。通過統計直方圖的時間差個數作為匹配結果有一個優勢就是它對音訊是否連續不敏感,這樣即使存在片段丟失或者訊號掩蔽都不影響最終的匹配結果。一個更令人驚訝的結果是,即使在一個很大的資料庫中,我們也可以正確識別出混合在一起包含有重複片段的多首歌,我們將演算法的這個特性稱為(其他音樂對正在識別音樂具有)“透明性”。
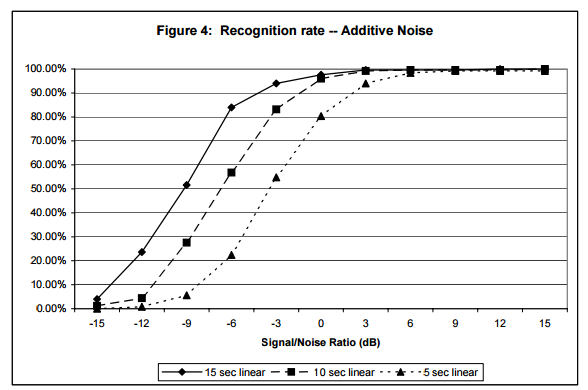
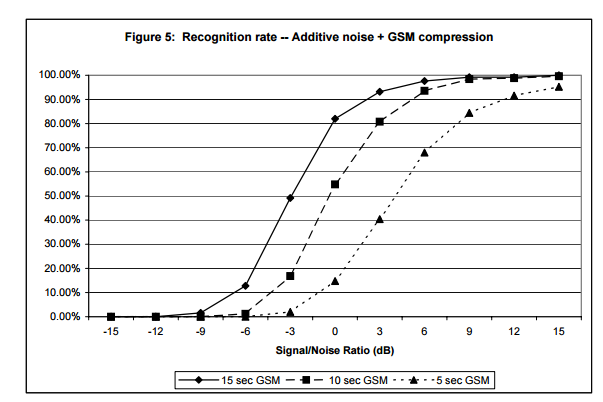
圖4表示不同長度和噪音情況下,對 250個片段進行10000曲庫規模檢索的結果。為了模擬真實情況,噪音樣本是從嘈雜的酒吧錄製的。音訊片段長度分別為15s,10s和5s,而且都包含在10000首歌中,新增的噪音也都是標準化之後的。可以看出,當15s,10s和5s片段的信噪比約為-9,-6和-3dB時,識別準確率降低到50%。圖5對進行過GSM6.10壓縮之後轉成PCM格式的音訊進行了同樣的分析,可以看出,當15s,10s和5s片段的信噪比上升為-3,0和+4dB時,識別準確率降低到50%。
3.2 速度
對於一個包含有2w首歌的曲庫,根據引數設定和具體應用的不同,檢索速度在5到500毫秒之間。如果樣本噪音較大,檢索時間通常在幾百毫秒;如果樣本非常乾淨,則演算法可以在10毫秒之內返回結果,通過進一步的優化還可以降低到每毫秒處理一個查詢。
3.3 Specificity and False Positives
演算法設計的初衷是檢索已經在資料庫中的音樂,所以不能識別現場演唱會演唱的歌曲。但是如果我們恰巧能在現場精確識別歌手正在演唱的歌曲,毫無疑問他在假唱!
需要注意的是,演算法對歌曲的版本很敏感。如果一首歌存在多個版本,演算法會返回當前正在播放的版本,即使人耳認為這些版本都一樣。
我們偶爾會收到誤報的案例。但是經過研究發現,演算法其實沒有誤報,它確實匹配上了歌曲中的某個片段,但不是正確歌曲說明存在剽竊的問題。如上所述,在效能和正確率方面需要進行權衡,我們要根據應用的不同選擇合理的引數。
5 參考
1] Avery Li-Chun Wang and Julius O. Smith,III., WIPO publication WO 02/11123A2, 7 February 2002, (Priority 31 July 2000).
[3] Jaap Haitsma, Antonius Kalker, ConstantBaggen, and Job Oostveen., WIPO publication WO 02/065782A1, 22 August 2002,(Priority 12 February, 2001).
[4] Jaap Haitsma, Antonius Kalker, “AHighly Robust Audio Fingerprinting System”, International Symposium on MusicInformation Retrieval (ISMIR) 2002, pp. 107-115. [5] Neuros Audio web site:http://www.neurosaudio.com/
[6] Sean Ward and Isaac Richards, WIPOpublication WO 02/073520A1, 19 September 2002, (Priority 13 March 2001)
[7] Audible Magic web site: http://www.audiblemagic.com/
[8] Erling Wold, Thom Blum, DouglasKeislar, James Wheaton, “Content-Based Classification, Search, and Retrieval ofAudio”, in IEEE Multimedia, Vol. 3, No. 3: FALL 1996, pp. 27-36
[9] Clango web site: http://www.clango.com/
[10] Cheng Yang, “MACS: Music AudioCharacteristic Sequence Indexing For Similarity Retrieval”, in IEEE Workshop onApplications of Signal Processing to Audio and Acoustics, 2001