
歡迎光臨啊噗不是阿婆主的酒館
命名實體識別是序列標註的子問題,需要將元素進行定位和分類,如人名、組織名、地點、時間、質量等。命名實體識別的任務就是識別出待處理文字中三大類(實體類、時間類和數字類)、七小類(人名、機構名、地名、時間、日期、貨幣和百分比) 命名實體。
一般來說進行命名實體識別的方法可以分成兩大類:基於規則的方法和基於統計的方法。 基於規則的方法是要人工建立實體識別規則,存在著成本高昂的缺點。 基於統計的方法一般需要語料庫來進行訓練,常用的方法有最大熵、CRF、HMM、神經網路等方法。
逐一介紹。
1. 必備知識點
1.1 概率圖
1.1.1 概覽
在統計概率圖(probability graph models)中,參考宗成慶老師的書,是這樣的體系結構:
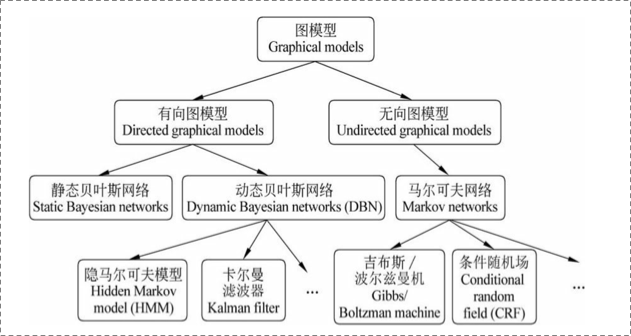
- 表示節點,即隨機變數(可以是一個token或者一個label),具體地,用為隨機變數建模,注意現在是代表了一批隨機變數(想象對應一條sequence,包含了很多的token),為這些隨機變數的分佈;
- 表示邊,即概率依賴關係。後面結合HMM或CRF的graph具體解釋。
1.1.2 有向圖 vs 無向圖
上圖可以看到,貝葉斯網路(信念網路)都是有向的,馬爾可夫網路無向。所以,貝葉斯網路適合為有單向依賴的資料建模,馬爾可夫網路適合實體之間互相依賴的建模。具體地,他們的核心差異表現在如何求,即怎麼表示 這個的聯合概率。
-
有向圖 對於有向圖模型,這麼求聯合概率:
舉個例子,對於下面的這個有向圖的隨機變數:
應該這樣表示他們的聯合概率:
-
無向圖 對於無向圖,一般就指馬爾可夫網路。
如果一個圖太大,可以用因子分解將 P=(Y) 寫為若干個聯合概率的乘積。將一個圖分為若干個“小團”,注意每個團必須是“最大團”。則有:
其中:
所以像上面的無向圖:
其中, 是一個最大團 C 上隨機變數們的聯合概率,一般取指數函式的:
上面的函式叫做勢函式。注意 即有CRF的影子~
那麼概率無向圖的聯合概率分佈可以在因子分解下表示為:
上述公式是CRF的開端~
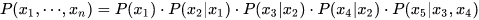
1.1.3 齊次馬爾可夫假設&馬爾可夫性
-
齊次馬爾科夫假設 齊次馬爾科夫假設,這樣假設:馬爾科夫鏈 裡的總是隻受一個引數的影響。 馬爾科夫假設這裡相當於就是個1-gram。
馬爾科夫過程呢?即,在一個過程中,每個狀態的轉移只依賴於前n個狀態,並且只是個n階的模型。最簡單的馬爾科夫過程是一階的,即只依賴於其哪一個狀態。
-
馬爾科夫性馬爾科夫性是是保證或者判斷概率圖是否為概率無向圖的條件。 三點內容:a. 成對,b. 區域性,c. 全域性。
1.2 判別式(discriminative)模型 vs. 生成式(generative)模型
在監督學習下,模型可以分為判別式模型與生成式模型。 根據經驗,A批模型(神經網路模型、SVM、perceptron、LR、DT……)與B批模型(NB、LDA……)的區別:
- A批模型是這麼工作的,他們直接將資料的Y(或者label),根據所提供的features,學習,最後畫出了一個明顯或者比較明顯的邊界(具體怎麼做到的?通過複雜的函式對映,或者決策疊加等等mechanism),這一點線性LR、線性SVM很明顯。
- B批模型是這麼工作的,他們先從訓練樣本資料中,將所有的資料的分佈情況摸透,然後最終確定一個分佈,來作為所有的輸入資料的分佈,並且他是一個聯合分佈 (注意 包含所有的特徵 ,包含所有的label)。然後來了新的樣本資料(inference),通過學習來的模型的聯合分佈 ,再結合新樣本給的,通過條件概率就能出來:
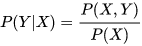
-
判別式模型
A批模型對應了判別式模型。根據上面的兩句話的區別,可以知道判別模型的特徵了,所以有句話說:判別模型是直接對建模,即直接根據X特徵來對Y建模訓練。 具體地,訓練過程是確定構件 模型裡面“複雜對映關係”中的引數,然後再去inference一批新的sample。
- 所以判別式模型的特徵總結如下:
- 對 P(Y|X) 建模
- 對所有的樣本只構建一個模型,確認總體判別邊界
- 根據新輸入資料的特徵,預測最可能的label
- 判別式的優點是:對資料量要求沒生成式的嚴格,速度也會快,小資料量下準確率也會好些。
-
生成式模型 B批模型對應了生成式模型。並且需要注意的是,在模型訓練中,學習到的是X與Y的聯合模型 ,也就是說,在訓練階段是隻對 建模,需要確定維護這個聯合概率分佈的所有的資訊引數。完了之後在inference再對新的sample計算 ,匯出 ,但這已經不屬於建模階段了。
結合NB過一遍生成式模型的工作流程。學習階段,建模: ,然後 。另外,LDA也是這樣,只是需要確定很多個概率分佈,並且建模抽樣都比較複雜。
- 所以生成式總結下有如下特點:
- 對 建模
- 這裡我們主要講分類問題,所以是要對每個label()都需要建模,最終選擇最優概率的label為結果,所以 沒有什麼判別邊界。(對於序列標註問題,那隻需要構件一個model)
- 中間生成聯合分佈,並可生成取樣資料。
- 生成式模型的優點在於,所包含的資訊非常齊全,所以不僅可以用來輸出label,還可以幹其他的事情。生成式模型關注結果是如何產生的。但是生成式模型需要非常充足的資料量以保證取樣到了資料本來的面目,所以速度相比之下,慢。
最後identity the picture below:

1.3 序列建模
常見的序列有如:時序資料、本文句子、語音資料等等。廣義下的序列有這些特點:
- 節點之間有關聯依賴性/無關聯依賴性序列的
- 節點是隨機的/確定的
- 序列是線性變化/非線性的……
對不同的序列有不同的問題需求,常見的序列建模方法總結有如下:
-
擬合,預測未來節點(或走勢分析): a. 常規序列建模方法:AR、MA、ARMA、ARIMA b. 迴歸擬合 c. Neural Networks
-
判斷不同序列類別,即分類問題:HMM、CRF、General Classifier(ML models、NN models)
-
不同時序對應的狀態的分析,即序列標註問題:HMM、CRF、RecurrentNNs
本文只關注在2. & 3. 類問題下的建模過程和方法。
1. 最大熵模型
2. 隱馬爾可夫模型HMM
3. 條件隨機場CRF
4. Bi-LSTM+CRF
該命名實體識別方法是一種將深度學習方法和機器學習方法相結合的模型。
 Bi-LSTM+CRF模型結構圖
Bi-LSTM+CRF模型結構圖
如圖:
- 輸入層是一個將文字序列中的每個漢字利用預先訓練好的字向量進行向量化,作為Bi-LSTM層的輸入。
- 利用一個雙向的LSTM(Bi-LSTM)對輸入序列進行encode操作,也就是進行特徵提取操縱。採用雙向LSTM的效果要比單向的LSTM效果好,因為雙向LSTM將序列正向和逆向均進行了遍歷,相較於單向LSTM可以提取到更多的特徵。
- 在經過雙向LSTM層之後,我們這裡使用一個CRF層進行decode,將Bi-LSTM層提取到的特徵作為輸入,然後利用CRF從這些特徵中計算出序列中每一個元素的標籤。
CRF是機器學習的方法,機器學習中困難的一點就是如何選擇和構造特徵。Bi-LSTM屬於深度學習方法,深度學習的優勢在於不需要人為的構造和選擇特徵,模型會根據訓練語料自動的選擇構造特徵。因此採用Bi-LSTM進行特徵的選擇構造,然後採用CRF根據得到的特徵進行decode,得到最終的序列標註的結果。這樣講深度學習和機器學習相結合的,互相取長補短。