
Spark RDD與MapReduce
什麼是Map、什麼是Reduce
MapReduce是一個分散式程式設計計算模型,用於大規模資料集的分散式系統計算。
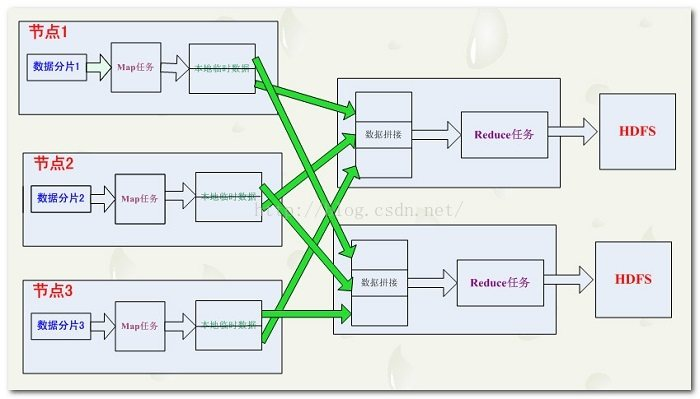
我個人理解,Map(對映、過濾)就是對一個分散式檔案系統(HDFS)中的每一行(每一塊檔案)執行相同的函式進行處理;
Reduce(規約、化簡)就是對Map處理好的資料進行兩兩運算,因此reduce函式必須要有兩個引數。
Map/Reduce的執行原理其實可以參考python的map/reduce函式:
Spark中的MapReduce
RDD(Resilient Distributed Dataset)叫做彈性分散式資料集,是Spark中最基本的資料抽象,它代表一個不可變、可分割槽、裡面的元素可平行計算的集合。RDD具有資料流模型的特點:自動容錯、位置感知性排程和可伸縮性。RDD允許使用者在執行多個查詢時顯式地將工作集快取在記憶體中,後續的查詢能夠重用工作集,這極大地提升了查詢速度。
RDD也支援常見的MapReduce操作。
RDD操作:
-
-
轉換操作:
每一次轉換操作都會產生不同的RDD,供給下一個“轉換”使用。轉換得到的RDD是惰性求值的,並不會發生真正的計算,只是記錄了轉換的軌跡,只有遇到行動操作時,才會發生真正的計算。
-
filter(func):篩選出滿足函式func的元素,並返回一個新的資料集
-
map(func):將每個元素傳遞到函式func中,並將結果返回為一個新的資料集
-
flatMap(func):與map()相似,但每個輸入元素都可以對映到0或多個輸出結果
-
groupByKey():應用於(K,V)鍵值對的資料集時,返回一個新的(K, Iterable)形式的資料集
-
reduceByKey(func):應用於(K,V)鍵值對的資料集時,返回一個新的(K, V)形式的資料集,其中的每個值是將每個key傳遞到函式func中進行聚合。
reduceByKey 函式應用於(Key,Value)格式的資料集。
reduceByKey 函式的作用是把 key 相同的合併。
reduceByKey 函式同樣返回一個(Key,Value)格式的資料集。
-
-
行動操作:
行動操作是真正觸發計算的地方。從檔案中載入資料,完成一次又一次轉換操作
-
count() 返回資料集中的元素個數
-
collect() 以陣列的形式返回資料集中的所有元素
-
first() 返回資料集中的第一個元素
-
take(n) 以陣列的形式返回資料集中的前n個元素
-
reduce(func) 通過函式func(輸入兩個引數並返回一個值)聚合資料集中的元素
-
foreach(func) 將資料集中的每個元素傳遞到函式func中執行。
-
-
Spark相關API文件
http://spark.apache.org/docs/latest/rdd-programming-guide.html