
我與語言處理 - [Today is TF-IDF] - [詞頻-逆檔案頻率]
下看一個簡單的解釋。最通俗易懂:
TF-IDF 要解決的問題,如何衡量一個關鍵字在文章中的重要性
總起
TF-IDF,理解起來相當簡單,他實際上就是TF*IDF,兩個計算值的乘積,用來衡量一個詞庫中的詞對每一篇文件的重要程度。下面我們分開來講這兩個值,TF和IDF。
TF
TF,是Term Frequency的縮寫,就是某個關鍵字出現的頻率,具體來講,就是詞庫中的某個詞在當前文章中出現的頻率。那麼我們可以寫出它的計算公式:
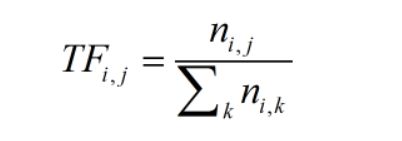
其中:
TF(i,j):關鍵詞j在文件i中的出現頻率。
n(i,j):關鍵詞j在文件i中出現的次數。
比如,一篇文章一共100個詞彙,其中“機器學習”一共出現10次,那麼他的TF就是10/100=0.1。
這麼看來好像僅僅是一個TF就能用來評估一個關鍵詞的重要性(出現頻率越高就越重要),其實不然,單純使用TF來評估關鍵詞的重要性忽略了常用詞的干擾。常用詞就是指那些文章中大量用到的,但是不能反映文章性質的那種詞,比如:因為、所以、因此等等的連詞,在英文文章裡就體現為and、the、of等等的詞。這些詞往往擁有較高的TF,所以僅僅使用TF來考察一個詞的關鍵性,是不夠的。這裡我們要引出IDF,來幫助我們解決這個問題。
IDF
IDF,英文全稱:Inverse Document Frequency,即“反文件頻率”。先看什麼是文件頻率,文件頻率DF就是一個詞在整個文庫詞典中出現的頻率,就拿上一個例子來講:一個檔案集中有100篇文章,共有10篇文章包含“機器學習”這個詞,那麼它的文件頻率就是10/100=0.1,反文件頻率IDF就是這個值的倒數,即10。因此得出它的計算公式:
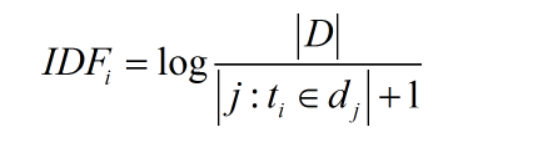
其中:
IDF(i):詞語i的反文件頻率
|D|:語料庫中的檔案總數
|j:t(i)屬於d(j)|出現詞語i的文件總數
+1是為了防止分母變0。
於是這個TF*IDF就能用來評估一個詞語的重要性。
還是用上面這個例子,我們來看看IDF是怎麼消去常用詞的干擾的。假設100篇文件有10000個詞,研究某篇500詞文章,“機器學習”出現了20次,“而且”出現了20次,那麼他們的TF都是20/500=0.04。再來看IDF,對於語料庫的100篇文章,每篇都出現了“而且”,因此它的IDF就是log1=0,他的TF*IDF=0。而“機器學習”出現了10篇,那麼它的IDF就是log10=1,他的TF*IDF=0.04>0,顯然“機器學習”比“而且”更加重要。
下面再往深處看一些:
詞頻 (term frequency, TF) 指的是某一個給定的詞語在該檔案中出現的次數。這個數字通常會被歸一化(一般是詞頻除以文章總詞數), 以防止它偏向長的檔案。(同一個詞語在長檔案裡可能會比短檔案有更高的詞頻,而不管該詞語重要與否。)
逆向檔案頻率 (inverse document frequency, IDF) IDF的主要思想是:如果包含詞條t的文件越少, IDF越大,則說明詞條具有很好的類別區分能力。某一特定詞語的IDF,可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取對數得到。
某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。
一個例子:
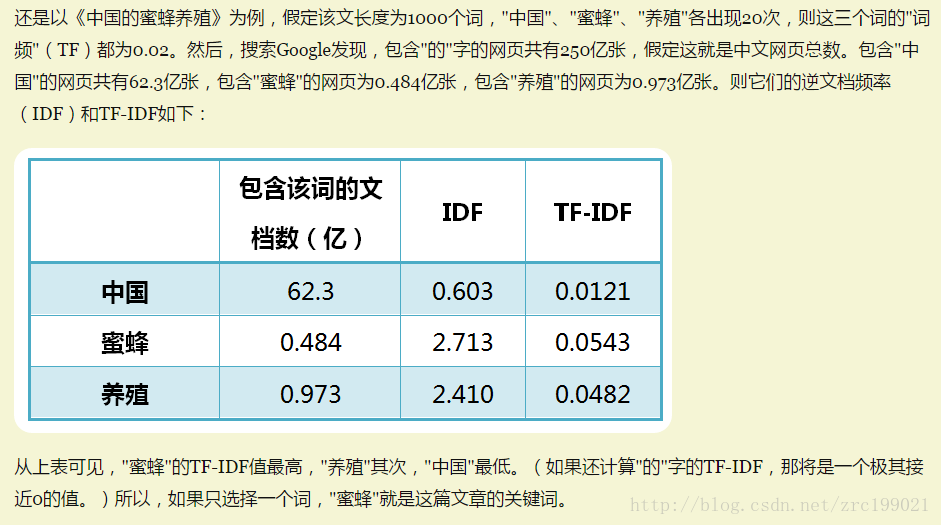
使用:
這裡使用sklearn
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, TfidfTransformer
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
CountVectorizer是通過fit_transform函式將文字中的詞語轉換為詞頻矩陣
get_feature_names()可看到所有文字的關鍵字
vocabulary_可看到所有文字的關鍵字和其位置
toarray()可看到詞頻矩陣的結果
vectorizer = CountVectorizer()
count = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(vectorizer.vocabulary_)
print(count.toarray())
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
{'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4}
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
TfidfTransformer是統計CountVectorizer中每個詞語的tf-idf權值
transformer = TfidfTransformer()
tfidf_matrix = transformer.fit_transform(count)
print(tfidf_matrix.toarray())
[[ 0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]
[ 0. 0.27230147 0. 0.27230147 0. 0.85322574
0.22262429 0. 0.27230147]
[ 0.55280532 0. 0. 0. 0.55280532 0.
0.28847675 0.55280532 0. ]
[ 0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]]
TfidfVectorizer可以把CountVectorizer, TfidfTransformer合併起來,直接生成tfidf值
TfidfVectorizer的關鍵引數:
max_df:
這個給定特徵可以應用在 tf-idf 矩陣中,用以描述單詞在文件中的最高出現率。假設一個詞(term)在 80% 的文件中都出現 過了,那它也許(在劇情簡介的語境裡)只攜帶非常少資訊。
min_df:
可以是一個整數(例如5)。意味著單詞必須在 5 個以上的文件中出現才會被納入考慮。設定為 0.2;即單詞至少在 20% 的 文件中出現 。
ngram_range:
這個引數將用來觀察一元模型(unigrams),二元模型( bigrams) 和三元模型(trigrams)。參考n元模型(n-grams)。
input:
'filename', 'file', 'content'
如果是'filename',序列作為引數傳遞給擬合器,預計為檔名列表,這需要讀取原始內容進行分析
如果是'file',序列專案必須有一個”read“的方法(類似檔案的物件),被呼叫作為獲取記憶體中的位元組數
否則,輸入預計為序列串,或位元組資料項都預計可直接進行分析。
stop_words:
'english', list, or None(default)
如果為english,用於英語內建的停用詞列表
如果為list,該列表被假定為包含停用詞,列表中的所有詞都將從令牌中刪除
如果None,不使用停用詞。max_df可以被設定為範圍[0.7, 1.0)的值,基於內部預料詞頻來自動檢測和過濾停用詞
sublinear_tf:
boolean, optional
應用線性縮放TF,例如,使用1+log(tf)覆蓋tf
tfidf_vec = TfidfVectorizer()
tfidf_matrix = tfidf_vec.fit_transform(corpus)
print(tfidf_vec.get_feature_names())
print(tfidf_vec.vocabulary_)
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
{'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4}
print(tfidf_matrix.toarray())
[[ 0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]
[ 0. 0.27230147 0. 0.27230147 0. 0.85322574
0.22262429 0. 0.27230147]
[ 0.55280532 0. 0. 0. 0.55280532 0.
0.28847675 0.55280532 0. ]
[ 0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]]