
CUDA學習筆記(一):GPU背景知識
host:CPU,記憶體 device:GPU,視訊記憶體 我是純粹小白,裡面的一些圖是根據我自己的理解畫的,可能並不一定對
GPU的背景知識
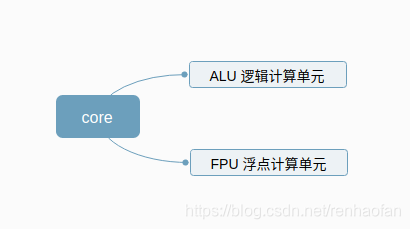
GPU的每一個core(計算核心)都有兩個計算單元
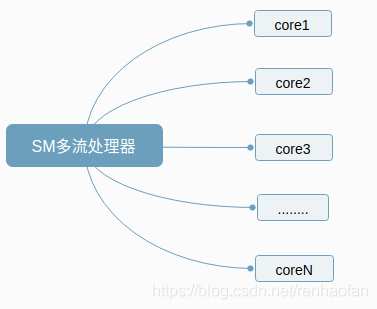 輸出指令之後GPU執行程式的流程
輸出指令之後GPU執行程式的流程
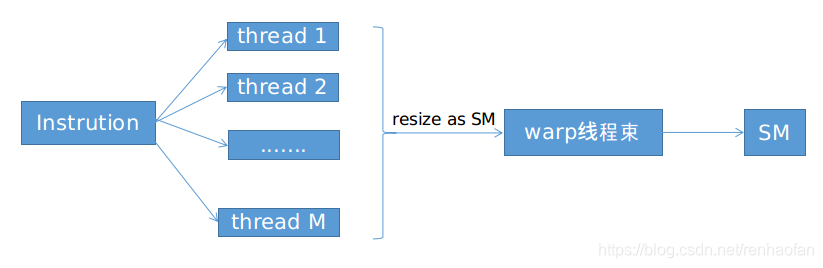 SM中每一個core執行的具體的運算是不一樣的,有CUDA統一排程
SM中每一個core執行的具體的運算是不一樣的,有CUDA統一排程
GPU和CPU執行程式的區別
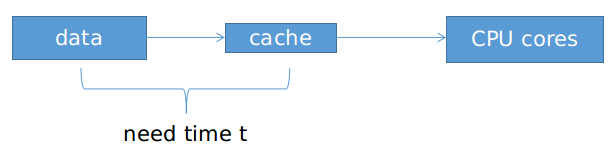
通常來說,訪問資料的時間隨著計算核和儲存資料的記憶體位置的距離而增加
Latency延遲是核等待資料的時間。
CPU是通過大量的告訴快取cache來縮短這個時間的,也就是儘可能減少時間t來減小延遲,CPU關注單個核心的執行速度
 如果warp1所需要的而資料不可以獲得的話,那麼SM就會轉向一個可以獲得資料的執行緒束。
如果warp1所需要的而資料不可以獲得的話,那麼SM就會轉向一個可以獲得資料的執行緒束。GPU所關注的是整體的運算吞吐量,而不是單個核心的執行速度
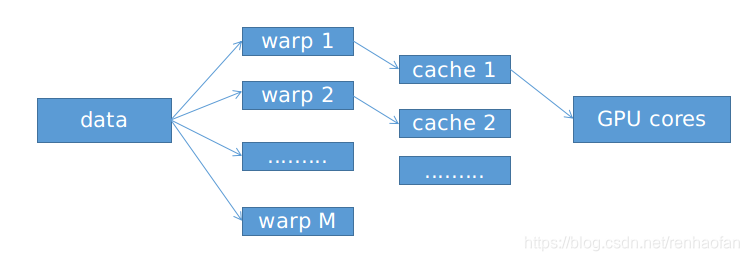
如何產生大量的執行緒? CUDA通過一種叫做核函式(kernel)的特殊函式去實現的,這個函式會產生大量的可以分配SM的計算執行緒
參考
- 《CUDA高效能平行計算》機械工業出版社
相關推薦
Ubuntu16.04:CUDA學習筆記(一):GPU背景知識
host:CPU,記憶體 device:GPU,視訊記憶體 我是純粹小白,裡面的一些圖是根據我自己的理解畫的,可能並不一定對 一,GPU和CPU執行程式的區別 (圖片來源:CUDA_C_Programming-Guide) 可以看到GPU有跟多的cores,你可以先把cores理
CUDA學習筆記(一):GPU背景知識
host:CPU,記憶體 device:GPU,視訊記憶體 我是純粹小白,裡面的一些圖是根據我自己的理解畫的,可能並不一定對 GPU的背景知識 GPU的每一個core(計算核心)都有兩個計算單元 輸
朱老師ARM裸機學習筆記(一):計算機基礎知識
RISC和CISC的區別 CISC(complex instruction-set computer)複雜指令集 特點: 指令較多,較豐富,CISC的CPU 較難設計,Intel是典型的CISC體系CPU。 RISC(reduce instruction
HLSL學習筆記(一):基礎
pad ddx 做了 cto har 分割 with 圖形 content http://www.cnblogs.com/rainstorm/archive/2013/05/04/3057444.html 前言 五一在家無事,於是學習了一下HLSL,基於XAN4.0的。學習
EF6 學習筆記(一):Code First 方式生成數據庫及初始化數據庫實際操作
view sqlserver 4.5 xpl 安裝 右鍵 ef6 字符串 ref 參考原文地址: https://docs.microsoft.com/en-us/aspnet/mvc/overview/getting-started/getting-started-wit
Servlet學習筆記(一):生命周期
磁盤 停止 生命 第一個 每一個 clas 瀏覽器 doget des 一、Servlet 生命周期: Servlet 生命周期可被定義為從創建直到毀滅的整個過程。以下是 Servlet 遵循的過程:初始化——響應請求——終止——回收 Servlet 通過調用 in
JSP學習筆記(一):JSP語法和指令
沒有 文件的 encoding 引入 2.0 .cn name blog .get 一、語法 1、腳本程序的語法格式: 腳本程序可以包含任意量的Java語句、變量、方法或表達式,只要它們在腳本語言中是有效的。 <% 代碼片段 %> 2、中文編碼問題
C#可擴展編程之MEF學習筆記(一):MEF簡介及簡單的Demo(轉)
com ring this exec hosting code .cn 引用 展開 在文章開始之前,首先簡單介紹一下什麽是MEF,MEF,全稱Managed Extensibility Framework(托管可擴展框架)。單從名字我們不難發現:MEF是專門致力於解決擴展性
《機器學習》學習筆記(一):線性回歸、邏輯回歸
ros XA andrew ID learn 給定 編程練習 size func 《機器學習》學習筆記(一):線性回歸、邏輯回歸 本筆記主要記錄學習《機器學習》的總結體會。如有理解不到位的地方,歡迎大家指出,我會努力改正。 在學習《機器學習》時,我主要是
算法學習筆記(一):插入排序和線性查找
插入排序 算法學習 AS 獲取 ear array import 右移 創建 (一)插入排序 看下面這張圖片:把打牌時手上的牌抽象為一個列表A,j表示當前最新抓的牌的索引(先放到手上最右邊) 索引 j =0 時 A[j] = 3 j >= 1時, 1、我們拿到
Django學習筆記(一):環境安裝與簡單實例
rom dex ftime not host 名稱 本機 turn perl Django學習筆記(一):環境安裝與簡單實例 通過本文章實現: Django在Windows中的環境安裝 Django項目的建立並編寫簡單的網頁,顯示歡迎語與當前時間 一、環境安裝 結合版
深度學習學習筆記(一):logistic regression與Gradient descent 2018.9.16
寫在開頭:這是本人學習吳恩達在網易雲課堂上的深度學習系列課程的學習筆記,僅供參考,歡迎交流學習! 一,先介紹了logistic regression,邏輯迴歸就是根據輸入預測一個值,這個值可能是0或者1,其影象是一條s形曲線,由預測值與真實值的差距計算出loss function損失函式和cos
Javaweb學習筆記(一):Servlet常見問題
1. 在server.xml中設定context路徑,如果Path值為“”,則可以訪問自己的頁面,無法訪問Tomcat主頁 2. 同樣的context路徑,path為空,卻啟動toncat失敗 解決:原因是有兩個相同的path路徑,空字元算相同的路徑 path=“”
javaweb學習筆記(一):web入門簡介、tomcat
目錄 1.web入門 2.tomcat 2.1 Tomcat的安裝與使用 2.2 Tomcat的目錄結構 2.3 Web應用的目錄結構 1.web入門 B/S (Broswer -Server 瀏覽器端- 伺服器端)架構,其典型應用就是各種網站。它的特點是第一,不
機器學習筆記(一):最小二乘法和梯度下降
一、最小二乘法 1.一元線性擬合的最小二乘法 先選取最為簡單的一元線性函式擬合助於我們理解最小二乘法的原理。 要讓一條直接最好的擬合紅色的資料點,那麼我們希望每個點到直線的殘差都最小。 設擬合直線為
學習筆記(一):使用K近鄰演算法檢測web異常操作
黑客入侵Web伺服器後,通常會通過系統漏洞進一步提權,獲得ROOT許可權。我們可以通過蒐集LINUX伺服器的bash操作日誌,通過訓練識別出特定使用者的操作習慣,然後進一步識別出異常操作的行為。 1.資料蒐集 訓練集包括50個使用者的操作
LCD實驗學習筆記(一):Makefile
主Makefile總領全域性的就這句—— lcd.bin: $(objs) 要生成lcd.bin,依賴於objs列舉的一堆檔案:head.o init.o nand.o interrupt.o serial.o lcddrv.o framebuffer.o lcdlib.o main.o l
Spring AOP學習筆記(一):基礎概念
AOP產生背景 AOP(Aspect Oriented Programming),即面向切面程式設計,可以說是OOP(Object Oriented Programming,面向物件程式設計)的補充和完善。OOP引入封裝、繼承、多型等概念來建立一種物件層次結構,用於模擬公共行為的一個集合。不
資料庫連線池學習筆記(一):原理介紹+常用連線池介紹
什麼是連線池 資料庫連線池負責分配、管理和釋放資料庫連線,它允許應用程式重複使用一個現有的資料庫連線,而不是再重新建立一個。 為什麼要使用連線池 資料庫連線是一種關鍵的有限的昂貴的資源,這一點在多使用者的網頁應用程式中體現得尤為突出。 一個數據庫連線物件均對應
Python3《機器學習實戰》學習筆記(一):k-近鄰演算法
**轉載:**http://blog.csdn.net/c406495762執行平臺: WindowsPython版本: Python3.xIDE: Sublime text3 他的個人網站:http://cuijiahua.com 文章目錄