
十分鐘瞭解K-means聚類
聚類演算法分類
1.基於劃分 給定一個有N個元組或者紀錄的資料集,分裂法將構造K個分組,每一個分組就代表一個聚類,K<N。 特點:計算量大。很適合發現中小規模的資料庫中小規模的資料庫中的球狀簇。 演算法:K-MEANS演算法、K-MEDOIDS演算法、CLARANS演算法
2.基於層次 對給定的資料集進行層次似的分解,直到某種條件滿足為止。具體又可分為“自底向上”和“自頂向下”兩種方案。 特點:較小的計算開銷。然而這種技術不能更正錯誤的決定。 演算法:BIRCH演算法、CURE演算法、CHAMELEON演算法
3.基於密度 只要一個區域中的點的密度大過某個閾值,就把它加到與之相近的聚類中去。 特點:能克服基於距離的演算法只能發現“類圓形”的聚類的缺點。 演算法:DBSCAN演算法、OPTICS演算法、DENCLUE演算法
4.基於網格 將資料空間劃分成為有限個單元(cell)的網格結構,所有的處理都是以單個的單元為物件的。 特點:處理速度很快,通常這是與目標資料庫中記錄的個數無關的,只與把資料空間分為多少個單元有關。 演算法:STING演算法、CLIQUE演算法、WAVE-CLUSTER演算法

K-means聚類演算法
1. K-means聚類演算法簡介 由於具有出色的速度和良好的可擴充套件性,Kmeans聚類演算法算得上是最著名的聚類方法。Kmeans演算法是一個重複移動類中心點的過程,把類的中心點,也稱重心(centroids),移動到其包含成員的平均位置,然後重新劃分其內部成員。k是演算法計算出的超引數,表示類的數量;Kmeans可以自動分配樣本到不同的類,但是不能決定究竟要分幾個類。k必須是一個比訓練集樣本數小的正整數。有時,類的數量是由問題內容指定的。例如,一個鞋廠有三種新款式,它想知道每種新款式都有哪些潛在客戶,於是它調研客戶,然後從資料裡找出三類。也有一些問題沒有指定聚類的數量,最優的聚類數量是不確定的。後面我將會詳細介紹一些方法來估計最優聚類數量。
Kmeans的引數是類的重心位置和其內部觀測值的位置。與廣義線性模型和決策樹類似,Kmeans引數的最優解也是以成本函式最小化為目標。Kmeans成本函式公式如下:
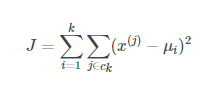
μi是第k個類的重心位置。成本函式是各個類畸變程度(distortions)之和。每個類的畸變程度等於該類重心與其內部成員位置距離的平方和。若類內部的成員彼此間越緊湊則類的畸變程度越小,反之,若類內部的成員彼此間越分散則類的畸變程度越大。求解成本函式最小化的引數就是一個重複配置每個類包含的觀測值,並不斷移動類重心的過程。首先,類的重心是隨機確定的位置。實際上,重心位置等於隨機選擇的觀測值的位置。每次迭代的時候,Kmeans會把觀測值分配到離它們最近的類,然後把重心移動到該類全部成員位置的平均值那裡。
2. K值的確定 2.1 根據問題內容確定 這種方法就不多講了,文章開篇就舉了一個例子。
2.2 肘部法則 如果問題中沒有指定kk的值,可以通過肘部法則這一技術來估計聚類數量。肘部法則會把不同kk值的成本函式值畫出來。隨著kk值的增大,平均畸變程度會減小;每個類包含的樣本數會減少,於是樣本離其重心會更近。但是,隨著kk值繼續增大,平均畸變程度的改善效果會不斷減低。kk值增大過程中,畸變程度的改善效果下降幅度最大的位置對應的kk值就是肘部。為了讓讀者看的更加明白,下面讓我們通過一張圖用肘部法則來確定最佳的kk值。下圖資料明顯可分成兩類:
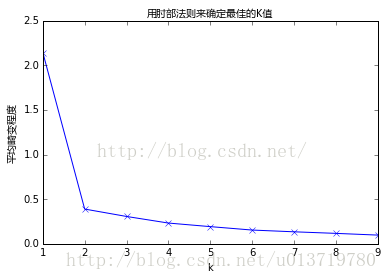
從圖中可以看出,k值從1到2時,平均畸變程度變化最大。超過2以後,平均畸變程度變化顯著降低。因此最佳的k是2。
2.3 與層次聚類結合 經常會產生較好的聚類結果的一個有趣策略是,首先採用層次凝聚演算法決定結果粗的數目,並找到一個初始聚類,然後用迭代重定位來改進該聚類。
2.4 穩定性方法 穩定性方法對一個數據集進行2次重取樣產生2個數據子集,再用相同的聚類演算法對2個數據子集進行聚類,產生2個具有kk個聚類的聚類結果,計算2個聚類結果的相似度的分佈情況。2個聚類結果具有高的相似度說明kk個聚類反映了穩定的聚類結構,其相似度可以用來估計聚類個數。採用次方法試探多個kk,找到合適的k值。
2.5 系統演化方法 系統演化方法將一個數據集視為偽熱力學系統,當資料集被劃分為kk個聚類時稱系統處於狀態kk。系統由初始狀態k=1k=1出發,經過分裂過程和合並過程,系統將演化到它的穩定平衡狀態 kiki ,其所對應的聚類結構決定了最優類數 kiki 。系統演化方法能提供關於所有聚類之間的相對邊界距離或可分程度,它適用於明顯分離的聚類結構和輕微重疊的聚類結構。
2.6 使用canopy演算法進行初始劃分 基於Canopy Method的聚類演算法將聚類過程分為兩個階段
(1) 聚類最耗費計算的地方是計算物件相似性的時候,Canopy Method在第一階段選擇簡單、計算代價較低的方法計算物件相似性,將相似的物件放在一個子集中,這個子集被叫做Canopy,通過一系列計算得到若干Canopy,Canopy之間可以是重疊的,但不會存在某個物件不屬於任何Canopy的情況,可以把這一階段看做資料預處理;
(2) 在各個Canopy內使用傳統的聚類方法(如Kmeans),不屬於同一Canopy的物件之間不進行相似性計算。
從這個方法起碼可以看出兩點好處:首先,Canopy不要太大且Canopy之間重疊的不要太多的話會大大減少後續需要計算相似性的物件的個數;其次,類似於Kmeans這樣的聚類方法是需要人為指出K的值的,通過(1)得到的Canopy個數完全可以作為這個k值,一定程度上減少了選擇k的盲目性。
其他方法如貝葉斯資訊準則方法(BIC)可參看文獻[4]。
3. 初始質心的選取 選擇適當的初始質心是基本kmeans演算法的關鍵步驟。常見的方法是隨機的選取初始中心,但是這樣簇的質量常常很差。處理選取初始質心問題的一種常用技術是:多次執行,每次使用一組不同的隨機初始質心,然後選取具有最小SSE(誤差的平方和)的簇集。這種策略簡單,但是效果可能不好,這取決於資料集和尋找的簇的個數。
第二種有效的方法是,取一個樣本,並使用層次聚類技術對它聚類。從層次聚類中提取kk個簇,並用這些簇的質心作為初始質心。該方法通常很有效,但僅對下列情況有效:(1)樣本相對較小,例如數百到數千(層次聚類開銷較大);(2) kk相對於樣本大小較小。
第三種選擇初始質心的方法,隨機地選擇第一個點,或取所有點的質心作為第一個點。然後,對於每個後繼初始質心,選擇離已經選取過的初始質心最遠的點。使用這種方法,確保了選擇的初始質心不僅是隨機的,而且是散開的。但是,這種方法可能選中離群點。此外,求離當前初始質心集最遠的點開銷也非常大。為了克服這個問題,通常該方法用於點樣本。由於離群點很少(多了就不是離群點了),它們多半不會在隨機樣本中出現。計算量也大幅減少。
第四種方法就是上面提到的canopy演算法。
4. 距離的度量 常用的距離度量方法包括:歐幾里得距離和餘弦相似度。兩者都是評定個體間差異的大小的。
歐氏距離是最常見的距離度量,而餘弦相似度則是最常見的相似度度量,很多的距離度量和相似度度量都是基於這兩者的變形和衍生,所以下面重點比較下兩者在衡量個體差異時實現方式和應用環境上的區別。
藉助三維座標系來看下歐氏距離和餘弦相似度的區別:

從圖上可以看出距離度量衡量的是空間各點間的絕對距離,跟各個點所在的位置座標(即個體特徵維度的數值)直接相關;而餘弦相似度衡量的是空間向量的夾角,更加的是體現在方向上的差異,而不是位置。如果保持A點的位置不變,B點朝原方向遠離座標軸原點,那麼這個時候餘弦相似cosθ是保持不變的,因為夾角不變,而A、B兩點的距離顯然在發生改變,這就是歐氏距離和餘弦相似度的不同之處。
根據歐氏距離和餘弦相似度各自的計算方式和衡量特徵,分別適用於不同的資料分析模型:歐氏距離能夠體現個體數值特徵的絕對差異,所以更多的用於需要從維度的數值大小中體現差異的分析,如使用使用者行為指標分析使用者價值的相似度或差異;而餘弦相似度更多的是從方向上區分差異,而對絕對的數值不敏感,更多的用於使用使用者對內容評分來區分使用者興趣的相似度和差異,同時修正了使用者間可能存在的度量標準不統一的問題(因為餘弦相似度對絕對數值不敏感)。
因為歐幾里得距離度量會受指標不同單位刻度的影響,所以一般需要先進行標準化,同時距離越大,個體間差異越大;空間向量餘弦夾角的相似度度量不會受指標刻度的影響,餘弦值落於區間[-1,1],值越大,差異越小。但是針對具體應用,什麼情況下使用歐氏距離,什麼情況下使用餘弦相似度?
從幾何意義上來說,n維向量空間的一條線段作為底邊和原點組成的三角形,其頂角大小是不確定的。也就是說對於兩條空間向量,即使兩點距離一定,他們的夾角餘弦值也可以隨意變化。感性的認識,當兩使用者評分趨勢一致時,但是評分值差距很大,餘弦相似度傾向給出更優解。舉個極端的例子,兩使用者只對兩件商品評分,向量分別為(3,3)和(5,5),這兩位使用者的認知其實是一樣的,但是歐式距離給出的解顯然沒有餘弦值合理。
5. 聚類效果評估 我們把機器學習定義為對系統的設計和學習,通過對經驗資料的學習,將任務效果的不斷改善作為一個度量標準。Kmeans是一種非監督學習,沒有標籤和其他資訊來比較聚類結果。但是,我們還是有一些指標可以評估演算法的效能。我們已經介紹過類的畸變程度的度量方法。本節為將介紹另一種聚類演算法效果評估方法稱為輪廓係數(Silhouette Coefficient)。輪廓係數是類的密集與分散程度的評價指標。它會隨著類的規模增大而增大。彼此相距很遠,本身很密集的類,其輪廓係數較大,彼此集中,本身很大的類,其輪廓係數較小。輪廓係數是通過所有樣本計算出來的,計算每個樣本分數的均值,計算公式如下:
a是每一個類中樣本彼此距離的均值,b是一個類中樣本與其最近的那個類的所有樣本的距離的均值。
6. Kmeans演算法流程 輸入:聚類個數k,資料集XmxnXmxn。 輸出:滿足方差最小標準的k個聚類。
(1) 選擇k個初始中心點,例如c[0]=X[0] , … , c[k-1]=X[k-1];
(2) 對於X[0]….X[n],分別與c[0]…c[k-1]比較,假定與c[i]差值最少,就標記為i;
(3) 對於所有標記為i點,重新計算c[i]={ 所有標記為i的樣本的每個特徵的均值};
(4) 重複(2)(3),直到所有c[i]值的變化小於給定閾值或者達到最大迭代次數。
Kmeans的時間複雜度:O(tkmn),空間複雜度:O((m+k)n)。其中,t為迭代次數,k為簇的數目,m為樣本數,n為特徵數。
7. Kmeans演算法優缺點 7.1 優點 (1). 演算法原理簡單。需要調節的超引數就是一個k。
(2). 由具有出色的速度和良好的可擴充套件性。
7.2 缺點 (1). 在 Kmeans 演算法中 kk 需要事先確定,這個 kk 值的選定有時候是比較難確定。
(2). 在 Kmeans 演算法中,首先需要初始k個聚類中心,然後以此來確定一個初始劃分,然後對初始劃分進行優化。這個初始聚類中心的選擇對聚類結果有較大的影響,一旦初始值選擇的不好,可能無法得到有效的聚類結果。多設定一些不同的初值,對比最後的運算結果,一直到結果趨於穩定結束。
(3). 該演算法需要不斷地進行樣本分類調整,不斷地計算調整後的新的聚類中心,因此當資料量非常大時,演算法的時間開銷是非常大的。
(4). 對離群點很敏感。
(5). 從資料表示角度來說,在 Kmeans 中,我們用單個點來對 cluster 進行建模,這實際上是一種最簡化的資料建模形式。這種用點來對 cluster 進行建模實際上就已經假設了各 cluster的資料是呈圓形(或者高維球形)或者方形等分佈的。不能發現非凸形狀的簇。但在實際生活中,很少能有這種情況。所以在 GMM 中,使用了一種更加一般的資料表示,也就是高斯分佈。
(6). 從資料先驗的角度來說,在 Kmeans 中,我們假設各個 cluster 的先驗概率是一樣的,但是各個 cluster 的資料量可能是不均勻的。舉個例子,cluster A 中包含了10000個樣本,cluster B 中只包含了100個。那麼對於一個新的樣本,在不考慮其與A cluster、 B cluster 相似度的情況,其屬於 cluster A 的概率肯定是要大於 cluster B的。
(7). 在 Kmeans 中,通常採用歐氏距離來衡量樣本與各個 cluster 的相似度。這種距離實際上假設了資料的各個維度對於相似度的衡量作用是一樣的。但在 GMM 中,相似度的衡量使用的是後驗概率 αcG(x|μc,∑c)αcG(x|μc,∑c) ,通過引入協方差矩陣,我們就可以對各維度資料的不同重要性進行建模。
(8). 在 Kmeans 中,各個樣本點只屬於與其相似度最高的那個 cluster ,這實際上是一種 hard clustering 。
針對Kmeans演算法的缺點,很多前輩提出了一些改進的演算法。例如 K-modes 演算法,實現對離散資料的快速聚類,保留了Kmeans演算法的效率同時將Kmeans的應用範圍擴大到離散資料。還有K-Prototype演算法,可以對離散與數值屬性兩種混合的資料進行聚類,在K-prototype中定義了一個對數值與離散屬性都計算的相異性度量標準。當然還有其它的一些演算法,這裡我 就不一一列舉了。
Kmeans 與 GMM 更像是一種 top-down 的思想,它們首先要解決的問題是,確定 cluster 數量,也就是 k 的取值。在確定了 k 後,再來進行資料的聚類。而 hierarchical clustering 則是一種 bottom-up 的形式,先有資料,然後通過不斷選取最相似的資料進行聚類。
8. 程式碼實現 import random from sklearn import datasets import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D %matplotlib inline
# 正規化資料集 X def normalize(X, axis=-1, p=2): lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis)) lp_norm[lp_norm == 0] = 1 return X / np.expand_dims(lp_norm, axis)
# 計算一個樣本與資料集中所有樣本的歐氏距離的平方 def euclidean_distance(one_sample, X): one_sample = one_sample.reshape(1, -1) X = X.reshape(X.shape[0], -1) distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1) return distances
class Kmeans(): """Kmeans聚類演算法.
Parameters: ----------- k: int 聚類的數目. max_iterations: int 最大迭代次數. varepsilon: float 判斷是否收斂, 如果上一次的所有k個聚類中心與本次的所有k個聚類中心的差都小於varepsilon, 則說明演算法已經收斂 """ def __init__(self, k=2, max_iterations=500, varepsilon=0.0001): self.k = k self.max_iterations = max_iterations self.varepsilon = varepsilon
# 從所有樣本中隨機選取self.k樣本作為初始的聚類中心 def init_random_centroids(self, X): n_samples, n_features = np.shape(X) centroids = np.zeros((self.k, n_features)) for i in range(self.k): centroid = X[np.random.choice(range(n_samples))] centroids[i] = centroid return centroids
# 返回距離該樣本最近的一箇中心索引[0, self.k) def _closest_centroid(self, sample, centroids): distances = euclidean_distance(sample, centroids) closest_i = np.argmin(distances) return closest_i
# 將所有樣本進行歸類,歸類規則就是將該樣本歸類到與其最近的中心 def create_clusters(self, centroids, X): n_samples = np.shape(X)[0] clusters = [[] for _ in range(self.k)] for sample_i, sample in enumerate(X): centroid_i = self._closest_centroid(sample, centroids) clusters[centroid_i].append(sample_i) return clusters
# 對中心進行更新 def update_centroids(self, clusters, X): n_features = np.shape(X)[1] centroids = np.zeros((self.k, n_features)) for i, cluster in enumerate(clusters): centroid = np.mean(X[cluster], axis=0) centroids[i] = centroid return centroids
# 將所有樣本進行歸類,其所在的類別的索引就是其類別標籤 def get_cluster_labels(self, clusters, X): y_pred = np.zeros(np.shape(X)[0]) for cluster_i, cluster in enumerate(clusters): for sample_i in cluster: y_pred[sample_i] = cluster_i return y_pred
# 對整個資料集X進行Kmeans聚類,返回其聚類的標籤 def predict(self, X): # 從所有樣本中隨機選取self.k樣本作為初始的聚類中心 centroids = self.init_random_centroids(X)
# 迭代,直到演算法收斂(上一次的聚類中心和這一次的聚類中心幾乎重合)或者達到最大迭代次數 for _ in range(self.max_iterations): # 將所有進行歸類,歸類規則就是將該樣本歸類到與其最近的中心 clusters = self.create_clusters(centroids, X) former_centroids = centroids
# 計算新的聚類中心 centroids = self.update_centroids(clusters, X)
# 如果聚類中心幾乎沒有變化,說明演算法已經收斂,退出迭代 diff = centroids - former_centroids if diff.any() < self.varepsilon: break
return self.get_cluster_labels(clusters, X)
def main(): # Load the dataset X, y = datasets.make_blobs(n_samples=10000, n_features=3, centers=[[3,3, 3], [0,0,0], [1,1,1], [2,2,2]], cluster_std=[0.2, 0.1, 0.2, 0.2], random_state =9)
# 用Kmeans演算法進行聚類 clf = Kmeans(k=4) y_pred = clf.predict(X)
# 視覺化聚類效果 fig = plt.figure(figsize=(12, 8)) ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=30, azim=20) plt.scatter(X[y==0][:, 0], X[y==0][:, 1], X[y==0][:, 2]) plt.scatter(X[y==1][:, 0], X[y==1][:, 1], X[y==1][:, 2]) plt.scatter(X[y==2][:, 0], X[y==2][:, 1], X[y==2][:, 2]) plt.scatter(X[y==3][:, 0], X[y==3][:, 1], X[y==3][:, 2]) plt.show()
if __name__ == "__main__": main()
KNN和K-Means的區別
|
KNN |
K-Means |
| 1.KNN是分類演算法
2.監督學習 3.餵給它的資料集是帶label的資料,已經是完全正確的資料 |
1.K-Means是聚類演算法
2.非監督學習 3.餵給它的資料集是無label的資料,是雜亂無章的,經過聚類後才變得有點順序,先無序,後有序 |
| 沒有明顯的前期訓練過程,屬於memory-based learning | 有明顯的前期訓練過程 |
| K的含義:來了一個樣本x,要給它分類,即求出它的y,就從資料集中,在x附近找離它最近的K個數據點,這K個數據點,類別c佔的個數最多,就把x的label設為c | K的含義:K是人工固定好的數字,假設資料集合可以分為K個簇,由於是依靠人工定好,需要一點先驗知識 |
| 相似點:都包含這樣的過程,給定一個點,在資料集中找離它最近的點。即二者都用到了NN(Nears Neighbor)演算法,一般用KD樹來實現NN。 | |