
HDFS(hadoop distributed File System)詳解
HDFS(hadoop distributed File System)分散式檔案系統
特點:高容錯性(多個文字副本儲存),價格低,高吞吐量。
常見的系統 gfs,HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS。
Hdfs總體上採用了master/slave 架構,主要由以下幾個元件組成:Client 、NameNode 、Secondary namenode 和DataNode
HDFS結構圖

一個HDFS叢集是有一個 Namenode和一定數目的 Datanode組成。 Namenode是一箇中心伺服器,負責管理檔案系統的
Namenode:執行nameSpace,一個檔案會被分為多個block,nameNode決定block會被對映到那個datanode, Datanode在 Namenode的指揮下進行 block的建立、刪除和複製。
HDFS讀寫原理
1. 客戶端要向HDFS寫資料,首先要跟namenode通訊以確認可以寫檔案並獲得接收檔案block的datanode,然後,客戶端按順序將檔案逐個block傳遞給相應datanode,並由接收到block的datanode負責向其他datanode複製block的副本


傳送過程是以流式寫入,檔案會被分為Block塊。
1. 客戶端將要讀取的檔案路徑傳送給namenode,namenode獲取檔案的元資訊(主要是block的存放位置資訊)返回給客戶端,客戶端根據返回的資訊找到相應datanode逐個獲取檔案的block並在客戶端本地進行資料追加合併從而獲得整個檔案



HFDS架構
核心目標,因為硬體的錯誤是常態,而非異常情況,hdfs由上千個節點組成,所以hdfs的核心目標是錯誤檢測和快速,自動的恢復。
主要以流式讀取,做批處理。
1 master和slave架構
主要角色:NameNode,dataNode,scendaryNameNode。
NameNode是master節點,大領導,負責管理整個hdfs,以及檔案目錄樹和檔案和目錄。和資料塊的對映,處理客戶端的讀寫請求,具體包括namespace(檔案目錄)和block管理(
NameNode提供的是始終被動接收服務的server,主要有三類協議介面:ClientProtocol介面、DatanodeProtocol介面、NamenodeProtocol介面。
dataNode slave節點,用來幹活,主要是用來存取資料,(一個是塊管理(datanode之間的聯絡),一個物理儲存)。hdfs將檔案拆分為多個block,block存在一個或者多個datanode中。執行資料塊的讀寫操作。
secondaryNameNode 是NameNode的冷備份。

合併fsimage和fsedits然後再發給namenode。預設是1小時,定期查詢,減少Namenode的負擔。
NameNode的核心是FSNamesysem,包括Fsdirectory(管理目錄),blocksMAP(維護塊資訊), LeaseManagr維護租約資訊;此外,還通過DatanodeDescriptor、corruptReplicas等維護資料結點(DN)狀態、壞副本等資訊;
fsname->block列表的對映
所有有效blocks集合
block與其所屬的datanodes之間的對映(該對映是通過block reports動態構建的,維護在namenode的記憶體中。每個datanode在啟動時向namenode報告其自身node上的block)
每個datanode與其上的blocklist的對映
採用心跳檢測根據LRU演算法更新的機器(datanode)列表
FSNamesystem體系結構
FSDirectory
FSDirectory用於維護當前系統中的檔案樹,儲存整個檔案系統的目錄狀態。 FSDirectory通過FSImage及FSEditLog儲存目錄結構的某一時刻映象及對映象的修改(從namenode本地磁碟讀取元資料資訊和向本地磁碟寫入元資料資訊,並登記對目錄結構所作的修改到日誌檔案);另外,FSDirectory儲存了檔名和資料塊的對映關係。
blocksMAP namenode中是通過block->datanode list的方式來維護一個block的副本是儲存在哪幾個datanodes上的對應關係的。
hdfs工作原理
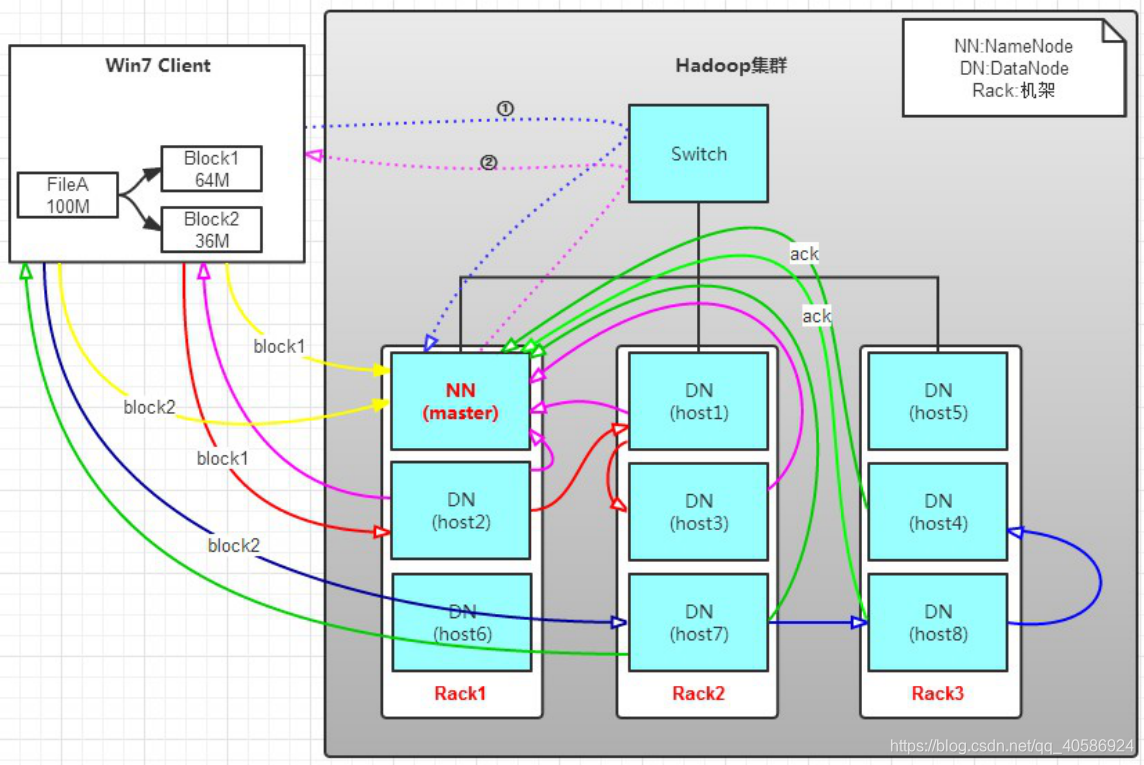
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode傳送寫資料請求,如圖藍色虛線①------>。
c. NameNode節點,記錄block資訊。並返回可用的DataNode,如粉色虛線②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
---------------------
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那儲存block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那儲存block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode傳送block1;傳送過程是以流式寫入。
流式寫入過程,
1>將64M的block1按64k的package劃分;
2>然後將第一個package傳送給host2;
3>host2接收完後,將第一個package傳送給host1,同時client想host2傳送第二個package;
4>host1接收完第一個package後,傳送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1傳送完畢。
6>host2,host1,host3向NameNode,host2向Client傳送通知,說“訊息傳送完了”。如圖粉紅顏色實線所示。
7>client收到host2發來的訊息後,向namenode傳送訊息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8>傳送完block1後,再向host7,host8,host4傳送block2,如圖藍色實線所示。
9>傳送完block2後,host7,host8,host4向NameNode,host7向Client傳送通知,如圖淺綠色實線所示。
10>client向NameNode傳送訊息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
---------------------
Hadoop檔案的常用操作:
檢視檔案命令,可以列出path目錄下的內容,包括檔名,許可權,所有者,大小和修改時間等。
命令格式
hdfs dfs -ls path 檢視檔案列表
hdfs dfs -lsr path 遞迴檢視檔案列表
hdfs dfs -du path 檢視path下的磁碟情況,單位位元組
使用示例 hdfs dfs -ls / 檢視當前目錄 hdfs dfs -lsr / 遞迴檢視當前目錄
建立資料夾
命令格式 hdfs dfs -mkdir path
使用示例 hdfs dfs -mkdir /user/trunk
建立檔案
命令格式:
hdfs dfs -touchz path 使用示例: hdfs dfs -touchz /user/test1.txt
賦予許可權
命令格式 hdfs dfs –chmod [許可權引數][擁有者][組] path 使用示例 hdfs dfs –chmod 777 /user/test.txt 許可權:
讀(r):4; 寫(w):2; 執行(x):1
上傳檔案
命令格式 hdfs dfs - put 原始檔夾 目標資料夾
使用示例 hdfs dfs -put /home/hadoop/data/record /guide/todayData
上傳record整個資料夾(含資料夾)
hdfs dfs -put /home/hadoop/data/record/* /guide/todayData
上傳record中的所有檔案(不含資料夾)
類似命令 hdfs dfs -copyFromLocal 原始檔夾 目標資料夾
作用同put hdfs dfs -moveFromLocal 原始檔夾 目標資料夾 上傳後刪除本地
下載檔案
命令格式 hdfs dfs -get 原始檔夾 目標資料夾
類似上傳命令
類似命令 hdfs dfs -copyToLocal 原始檔夾 目標資料夾
作用同get hdfs dfs -moveToLocal 原始檔夾 目標資料夾 get後刪除原始檔
檢視檔案
內容命令格式 hadoop fs -cat path
從頭檢視這個檔案
hadoop fs -tail path 從尾部檢視最後1K
使用示例
hadoop fs -cat /user/trunk/test.txt
hadoop fs -tail /user/trunk/test.txt
fs VS dfs從兩個命令的定義中可以看到這兩者之間似乎沒有什麼區別。
fs涉及到一個通用的檔案系統,使用面最廣,可以指向任何的檔案系統,如local,hdfs等。
但是dfs僅是針對hdfs的,只能操作HDFS檔案系統相關,包括與Local FS間的操作。 什麼時候用dfs,什麼時候用fs?
絕大部分都可以使用dfs命令。 僅在本地與hadoop分散式檔案系統的互動操作中,可以考慮使用fs命令。
hadoop fs VS hdfs dfs 兩者的相同和不同。