
做優化的資料庫工程師請參考!CynosDB的計算層設計優化揭祕
本文由雲+社群發表
本文作者:孫旭,騰訊資料庫開發工程師,9年資料庫核心開發經驗;熟悉資料庫查詢處理,併發控制,日誌以及儲存系統;熟悉PostgreSQL(Greenplum,PGXC等)、Teradata等資料庫核心實現機制。
CynosDB 是騰訊資料庫研發團隊推出的自研資料庫,有PostgreSQL和MySQL兩個版本。本文以相容PostgreSQL版CynosDB為例,介紹我們的架構設計和優化思路。
1、概述
PostgreSQL是世界上最先進的開源資料庫,始於1986年,有30多年的社群演進歷史。其先進的架構、可靠性以及豐富的功能已經獲得業界高度認可。同時,PostgreSQL能夠在多種作業系統上執行,支援多種索引型別和擴充套件,特別是對PostGIS擴充套件的支援,可以讓PostgreSQL輕鬆的處理地理資訊資料。
相容PostgreSQL版CynosDB作為PostgreSQL在NewSQL領域的一個產品,也具有良好的擴充套件性。由其架構特點帶來的資源池化,可以讓使用者付出更少的成本而獲得同等的效能,並且不損失PostgreSQL資料庫原有的功能特性。
2、基礎架構
現有共有云上的資料庫存在一些不足:
1.網路IO重。傳統雲上的主備架構下,會有大量資料需要寫到磁碟,主要包括:WAL LOG、髒頁資料、防止頁部分寫的Double Write或者Full Page Write。
2.主從例項不共享資料。一方面浪費了大量儲存,另一方面進一步加重了網路IO。這樣會導致磁碟利用率低、CPU閒置等問題。
而CynosDB可以通過日誌下沉、共享儲存來解決上述問題,以實現共有云資料庫的高性價比、高可用性以及彈性擴充套件。其基礎架構如下:
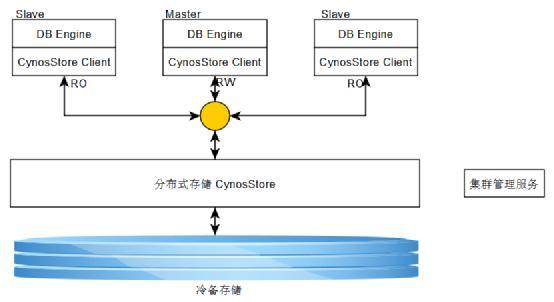
架構中的元件:
\1. master是資料庫的主例項,負責接收應用的讀寫事務請求。
\2. slave是資料庫的只讀例項,負責處理應用的讀請求,可以支援多個slave例項。
\3. CynosStore Client提供訪問分散式儲存(CynosStore)的介面。DB引擎通過這些介面訪問儲存,完成資料檔案的讀寫等操作。
\4. CynosStore是一個分散式儲存系統,存放資料庫的資料和日誌,並負責日誌到資料頁面的轉換。
\4. 叢集管理服務負責整個系統的管理,例如:儲存擴容,例項建立等。
\5. 冷備儲存用來儲存系統的日誌。
master例項將資料的變更以日誌方式傳送到儲存系統(CynosStore)中,同時CynosStore會定期將日誌合併到資料頁面上。因此,CynosDB無需將髒頁寫入到儲存中,這點與傳統資料庫是不同的。slave資料庫例項沒有寫事務,不會向儲存傳送日誌,但是會從儲存中讀取頁面,也會接收master例項的日誌來重新整理記憶體中的資料頁面;如果收到的日誌所對應的頁面沒有在slave的記憶體中,則會丟棄這些日誌。
從架構上看,CynosDB實現了儲存和計算分離,並把資源進行池化,因此適合雲上部署。而且計算和儲存傳輸資料的僅有日誌流,無需寫髒頁面,因此也減少了系統中的網路量。總的來說,CynosDB具有如下優勢:
1.計算能力彈性擴充套件。可以快速增加slave節點來擴充套件讀能力,而不必進行全量的資料拷貝。
\2. 儲存能力彈性擴充套件。不像傳統資料庫那樣受單機儲存能力的限制。
\3. 充分利用硬體資源。緩解傳統主備架構中的CPU閒置、磁碟利用率不高等問題。
\4. 備份容易。備份完全由後臺持續進行,使用者無需干預。
3、相容PostgreSQL版CynosDB的計算層架構
CynosDB實現了計算與儲存分離,系統也因此被分成兩大塊:計算層和儲存層。計算層負責SQL解析、日誌生成等;儲存層負責資料儲存、日誌歸檔以及日誌合併等。本節以CynosDB的PostgreSQL相容版本為例來介紹計算層架構。其計算層架構如下圖所示。為了實現這種NewSQL架構,我們對PostgreSQL核心做了新設計:
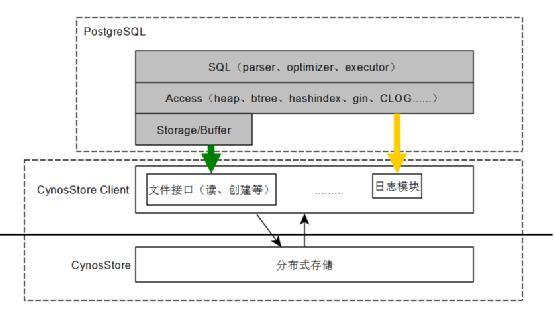
灰色部分是PostgreSQL核心原生模組:
\1. SQL:PostgreSQL的SQL引擎,包括詞法/語法分析、語義分析、查詢重寫/優化和查詢執行。CynosDB的設計不涉及SQL層改動,因此它相容PostgreSQL原來的SQL語法和語義。
\2. Access:資料庫的訪問層,定義了物件的組織方式和訪問方法。其中包括:
lHeap:表實現以及訪問方法,包括掃描、更新、插入、刪除等。
lbtree/gin/gist/spgist/hash/brin:索引實現,包括各種索引的實現和操作方式,如索引掃描、插入等。
lCLOG/MultiXACT:與事務提交狀態以及併發等。
Access是設計和優化的重點模組。當表和索引等資料庫物件被修改時,原生的PostgreSQL會生成XLog,並寫入到日誌檔案中。在CynosDB中,這些物件修改時也會生成日誌,但是這些日誌不會寫本地的日誌檔案,而是傳送到CynosStore中。
\3. storage/buffer:buffer pool和儲存管理,呼叫檔案介面對資料檔案進行讀寫。在CynosDB中使用CynosStore Client對CynosStore中的檔案進行操作。
\5. CynosStore Client提供訪問CynosStore的介面,以完成資料庫對資料檔案的操作。包括資料頁面讀取介面、日誌傳送介面等。
\6. 分散式儲存CynosStore是一個基於日誌的分散式的塊儲存,在本文中不做重點介紹。
CynosDB的計算層把資料檔案修改所生成的日誌,通過CynosStore Client傳送到分散式儲存CynosStore中,而CynosStore會將日誌定時合併到資料頁面上。這裡比較重要的一點是,計算層寫出日誌並不是PostgreSQL原生的XLog,而是我們自己重新設計的日誌系統和日誌格式。因此CynosDB不依賴於PostgreSQL的原生日誌系統,這種設計也可以讓我們有機會在CynosDB上做更多的效能優化。具體可以參見下節。
4、架構優化
CynosDB計算層的架構設計遵循瞭如下思路:
1.“極簡IO”。即,降低網路/磁碟IO
\2. 高效的系統設計。非同步的日誌設計、降低計算層CPU負載
通過這些設計,使CynosDB的效能比雲上的同等配置效能要高。本節主要介紹計算層所做的優化手段。
4.1 日誌系統
相容PostgreSQL版CynosDB的底層儲存CynosStore是一個支援日誌寫的、可以提供多版本讀的、分散式的塊裝置,DB引擎對儲存中檔案的修改,都是以日誌的方式傳送到儲存中。其日誌格式是:<頁面號,頁面偏移,修改內容,修改長度>,含義是:在頁面的哪個偏移做了什麼內容的修改。這樣設計的日誌是冪等的。
以表插入元組為例,PostgreSQL原來的XLog日誌格式可能是:
<relfilenode, pageno, offsetnum,informask2,infomask,hoff,tuple_data>:代表在頁面(由relfilenode和pageno來確定一個頁面)的offsetnum位置插入一條元組,插入的元組是在恢復時由informask2, infomask, hoff, tuple_data等資訊進行重構。
同樣的操作,在CynosDB中生成的日誌可能如下。假設在頁面號為n的頁面上插入元組tuple:
<n,10,(char *) &pd_flag,2> – 儲存頁面頭pd_flag到日誌
<n,12,(char *) &pd_lower,2> – 儲存頁面頭pd_lower到日誌
<n,14,(char *) &pd_upper,2> – 儲存頁面頭pd_upper到日誌
<n,36,(char *) &ItemIdData,4> – 儲存ItemIdData陣列的第3個元素到日誌
<n,7488,(char *) tuple,172> – 儲存tuple到日誌
這些條目記錄了頁面在插入元組時的所有修改,它們最終會在CynosStore Client中形成一個MTR(mini-transaction record:多條日誌的集合,代表對資料庫儲存結構的一次原子修改,例如:btree結構、頁面結構的修改;在日誌重放的時候需要將一個MTR的所有日誌都應用完畢,否則會導致資料庫儲存結構的破壞),並放到日誌流中傳送到儲存。當儲存需要將這個MTR合併到頁面時,要保證MTR中的所有日誌應用完畢,任何不完全的應用都會導致頁面結構不正確。
利用日誌特點,我們對PostgreSQL 的核心進行了優化,而優化之後的日誌大小開銷與PostgreSQL的原生XLOG差不多。這些優化和設計包括:
\1. 移除原本PostgreSQL中full page write(FPW)特性。為了保證系統crash再重啟之後,那些部分寫的頁面(torn page)可以被正確恢復,PostgreSQL在Checkpoint之後,對頁面執行第一次被修改時,會將整個頁面記錄到日誌中,這種特性就是FPW,類似MySQL的double write。當crash recovery時,系統會以這個全頁作為基頁面進行日誌回放,並將恢復好的頁面寫到儲存,而不必關心儲存頁面中的頁面是否是半頁。由於CynosDB日誌的冪等性,當出現半頁寫時,系統直接重新在此頁面上直接進行日誌回放,即可將頁面修復到一致狀態。因此CynosDB中無需原生的FPW,從而減少了日誌量。
\2. 移除系統中髒頁面刷盤操作。CynosDB通過日誌儲存頁面的修改,並且可以通過在基頁上合併日誌而得到最新頁面,因此無需原本系統的刷髒操作,僅僅刷日誌就足夠。
通過如上優化,可以很大程度上減少網路IO和日誌量。
\3. 除了以上對PostgreSQL核心的優化,CynosDB對日誌的記錄方式也進行了精簡和壓縮。CynosDB的日誌都有日誌頭(LogHeader),如果修改同一個頁面的多條日誌共享一個日誌頭,則可以省去多個日誌頭的開銷,如下圖所示:
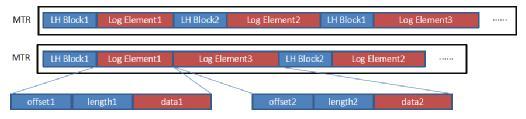
LH代表LogHeader,Log Element代表對頁面的頁一次修改。如上圖,有兩條對Block1的修改日誌,並且每個修改都有一個日誌頭(LH),經過日誌頭合併優化後,形成新的MTR中,修改Block1的那些日誌共享了同一個日誌頭。
如果修改同一個頁面的兩條日誌是相鄰的,那麼可以將兩條日誌進一步合併成一條日誌。這種方式減少了日誌條目,從而可以提高日誌合併和頁面生成速度。
4.2 頁面CRC
在PostgreSQL中,頁面在刷盤前會計算並填充頁面的CRC屬性,而在CynosDB中,如果為CRC也生成了一條日誌寫入到儲存中的話,會增加計算節點的CPU負擔和日誌條數。為了解決這個問題,我們將CRC的計算任務下放到儲存中,從而減輕了計算層的CPU負擔,以及日誌條數。
4.3 非同步表擴充套件
原生的PostgreSQL資料庫使用的是本地檔案系統儲存資料,其檔案擴充套件操作同步並實時的反映到磁碟檔案上。但是CynosDB的擴充套件操作是通過日誌實現,如果每次擴充套件都對日誌做一次flush操作,讓擴充套件實時的反應到儲存上,勢必會影響系統的效能。因此,我們實現了檔案的非同步擴充套件,即檔案擴充套件的日誌先保留在系統的日誌buffer中,而不是每次擴充套件都實時的重新整理到儲存中,當事務提交的時候再把這些日誌刷到儲存上,對資料批量匯入的效能提升很明顯。另外,擴充套件操作可以一次性在檔案中擴展出多個頁面,減少呼叫擴充套件操作的次數。
後續
後續我們會在新硬體、多Master架構等領域作更多探索,為雲上的資料庫產品形態帶來更多驚喜和亮點。
此文已由作者授權騰訊雲+社群釋出