
mysql 千萬級數據查詢效率實踐,分析 mysql查詢優化實踐--本文只做了一部分,僅供參考
數據量, 1300萬的表加上112萬的表
註意: 本文只做了部分優化,並不全面,僅供參考, 歡迎指點.請移步tim查看,因為寫的時候在tim寫的,粘貼過來截圖有問題,就直接上鏈接了.
https://823948977.docs.qq.com/T5e6dBYLoZz?opendocxfrom=tim
文章內容類似截圖:
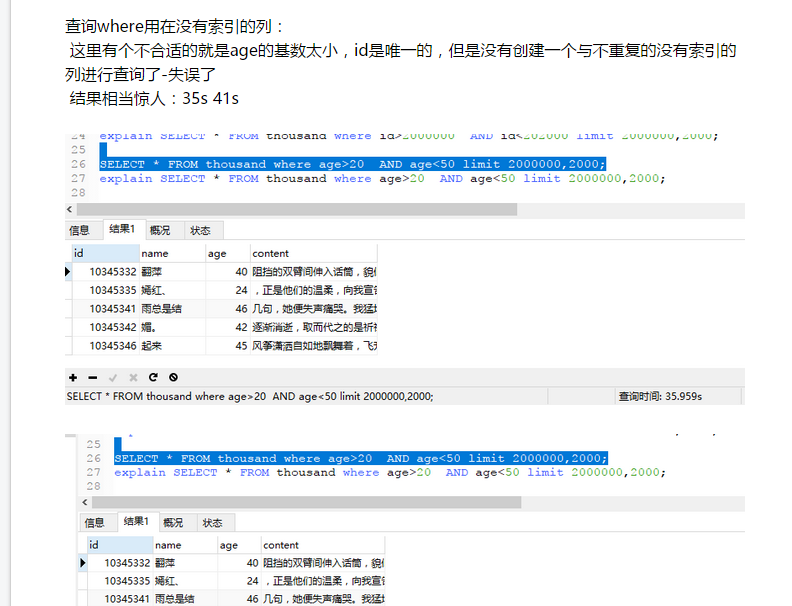
mysql 千萬級數據查詢效率實踐,分析 mysql查詢優化實踐--本文只做了一部分,僅供參考
相關推薦
mysql 千萬級數據查詢效率實踐,分析 mysql查詢優化實踐--本文只做了一部分,僅供參考
open ges -a 效率 2萬 https ini class cnblogs 數據量, 1300萬的表加上112萬的表 註意: 本文只做了部分優化,並不全面,僅供參考, 歡迎指點. 請移步tim查看,因為寫的時候在tim寫的,粘貼過來截圖有問題,就直接上鏈接了.
mysql千萬級數據優化查詢
arch nbsp 限定 方法 騰訊 tab 建立 垂直拆分 程序 我們在做一個項目,一個網站或一個app時,用戶量巨增,當使用的mysql數據庫中的表數據達到千萬級時,可以從以下方面考濾優化: 1、在設計數據庫表的時候就要考慮到優化 2、查詢sql語句上的優化
mysql千萬級數據表,創建表及字段擴展的幾條建議
計算 count 兩種 沒有 key值 null .cn 優點 關系 一:概述 當我們設計一個系統時,需要考慮到系統的運行一段時間後,表裏數據量大約有多少,如果在初期,就能估算到某幾張表數據量非常龐大時(比如聊天消息表),就要把表創建好,這篇文章從創建表,增加
Mysql千萬級數據性能調優配置
minimum mman format 表示 alter 時間 cee 版本 size 背景: 筆者的源數據一張表大概7000多萬條,數據大小36G,索引6G,加起來表空間有40G+,類似的表有4張,總計2億多條 數據庫mysql,引擎為innodb,版本5.7,服務器
php+中文分詞scws+sphinx+mysql打造千萬級數據全文搜索
libc 海量 modules shell pub redis集群 register 處理 onf Sphinx是由俄羅斯人Andrew Aksyonoff開發的一個全文檢索引擎。意圖為其他應用提供高速、低空間占用、高結果 相關度的全文搜索功能。Sphinx可以非常容易的與
MySQL百萬級、千萬級數據多表關聯SQL語句調優
減少 sql 有序 理解 ble 查詢 per mit type 本文不涉及復雜的底層數據結構,通過explain解釋SQL,並根據可能出現的情況,來做具體的優化,使百萬級、千萬級數據表關聯查詢第一頁結果能在2秒內完成(真實業務告警系統優化結果)。希望讀者能夠理解SQL的執
關於mysql百萬級數據的插入和刪除
只有一個 筆記 style linu xxx 程序 back exceptio ace 這幾天有個朋友讓我幫他優化mysql百萬級操作db的事。於是我就答應了……。優化完個人做個筆記。給大家一個參考……如果有更好的方法,[email protected]/* *
php實現mysql百萬級數據插入,耗時10s左右
auth 每次 esc 處理 ram foreach循環 數量 turn () 如題,最近做的一個項目,需求就是這樣,寫個功能模塊,實現批量導入,為客服省點時間(好吧,需求就是需求)。好在插入的數據,都是些連續的數字,所以可以利用 foreach循環出這些數據,然後拼接成
python爬取B站千萬級數據,發現了這些熱門UP主的秘密!
python 爬蟲 科技 web 編程Python(發音:英[?pa?θ?n],美[?pa?θɑ:n]),是一種面向對象、直譯式電腦編程語言,也是一種功能強大的通用型語言,已經具有近二十年的發展歷史,成熟且穩定。它包含了一組完善而且容易理解的標準庫,能夠輕松完成很多常見的任務。它的語法非常簡捷和清晰,與其它大
專案構建分析和 webpack 優化實踐
加入新公司一個月,最近接手在做一個 chrom 瀏覽器外掛的專案,開發過程中發現專案打包的時間很長,足足有30多秒,這是讓人很難接受的,而且構建的顯示了幾條包體積過大的提示資訊: 可以看到,打包後有三個包超過了建議的體積,是什麼導致了打包時間長和包的體積過大呢? 下面通過一些具體方法來分析原因和解決這
PTA 數據結構 一元多項式求導 (僅供參考)
僅供參考 struct -o sca scanf scan -1 can 數組 請勿粘貼 輸入格式: 以指數遞降方式輸入多項式非零項系數和指數(絕對值均為不超過1000的整數)。數字間以空格分隔。 輸出格式: 以與輸入相同的格式輸出導數多項式非零項的系數和指數。數字間以空格
測試計劃&性能測試分析報告模板(僅供參考)
分析報告 測試的 容量 4.2 結束 穩定性測試 測試計劃 能力 維護 一、測試計劃 1. 引言 1.1 編寫目的 2. 參考文檔 3. 測試目的 4. 測試範圍 4.1 測試對象 4.2 需要測試的特性 4.3 無需測試的特性 5
測試計劃&效能測試分析報告模板(僅供參考)
一、測試計劃 1. 引言 1.1 編寫目的 2. 參考文件 3. 測試目的 4. 測試範圍 4.1 測試物件 4.2 需要測試的特性 4.3 無需測試的特性 5. 測試啟動與結束準則 5.1 啟動準則 5
提高mysql千萬級大數據SQL查詢優化30條經驗
pro 字符串 插入數據 run 較差 存儲 同時 例程 鎖定 1.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 2.應盡量避免在 where 子句中對字段進行 null 值判斷,否則將導致引擎放棄使用索引而進
mysql千萬級大數據SQL查詢優化
意義 表達式 -1 大數據量 並且 系統 -s get 連接 1.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 2.應盡量避免在 where 子句中對字段進行 null 值判斷,否則將導致引擎放棄使用索引而進行全
mysql 存儲及查詢億級數據
緩存服務 explain 字段表 tex 大數據 語句 壓力 根據 等等 第一階段: 1,一定要正確設計索引 2,一定要避免SQL語句全表掃描,所以SQL一定要走索引(如:一切的 > < != 等等之類的寫法都會導致全表掃描) 3,一定要避免 limit
30個MySQL千萬級大數據SQL查詢優化技巧詳解
!= 結果 exist 進行 cluster date 有意義 參數 rop 本文總結了30個mysql千萬級大數據SQL查詢優化技巧,特別適合大數據裏的MYSQL使用。 1.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建
Lepus搭建企業級數據庫慢查詢分析平臺
gsl 手動 test history 選擇 tmp uri post socket 前言 Lepus的慢查詢分析平臺是獨立於監控系統的模塊,該功能需要使用percona-toolkit工具來采集和記錄慢查詢日誌,並且需要部署一個我們提供的shell腳本來進行數據采集。該
Mysql 多表聯合查詢效率分析及優化
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
分析為什麼mysql中like模糊查詢效率低
相比update和insert,一般查詢應該是資料庫中操作最頻繁的。而在有些應用場景需要用到like模糊查詢,那麼對於大資料,查詢的時候就要注意了。現在來分析一下為什麼like語句查詢的效率會很低,測試資料共4000000條,如下圖:第一步:不使用索引下圖可以看出,不使用索引的時候普通查詢與like查詢的耗時