
感知機整理筆記
假設輸入空間(特徵空間),輸出空間是
,輸入
表示例項的特徵向量,對應輸入空間(特徵空間)點;
輸出表示例項的類別,輸入空間到輸出空間的對映函式
稱為感知機。
其中w b為模型引數,w*x表示內積,sign表示指示函式:
感知機幾何解釋
線性方程,對應於特徵空間 Rn 超平面S,S的法向量為w,S的截距為b。超平面S將特徵空間分為兩部分,位於兩部分(特徵空間)
的點分為正負兩類,因此也稱為分離超平面。二維空間分離平面示意圖:
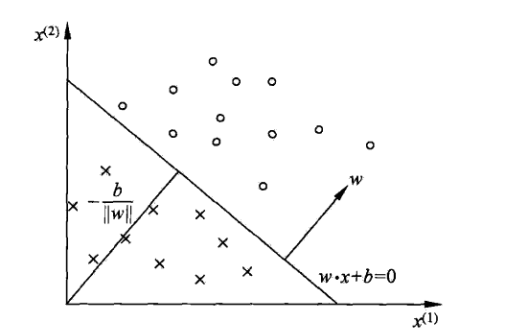
感知機的學習策略
給定訓練集,需要找到模型引數w 、b,確定將正負樣例正確分開的超平面。這時我們需要定義損失函式並極小化。損失函式一個自然的想法是誤分類點
的總數,但它不是w 、b的連續可導數;另一個想法是計算所有誤分類點到超平面S的距離,其中任一點
到S的距離可表示為:
,其中
是w的L2 範數。
對於誤分類的資料(xi ,yi)有:
誤分類點集合有:
誤分類點到超平面S的距離為:
因此所有誤分類點到超平面的距離為:,M為誤分類點的集合。
不考慮就得到感知機的損失函式
,感知機的學習策略就是在假設空間選取使
最小的模型引數w 、b。
感知機損失函式極小化方法
感知機誤分類集合M,所有點離超平面S越近,越小,而
對
是連續可導的,對w求偏導得:
對b求偏導得:
訓練時隨機選取誤分類點對
更新:
其中為學習率或步長。
比較直觀的程式碼實現:
# 資料線性可分,二分類資料 # 此處為一元一次線性方程 class Model: def __init__(self): self.w = np.ones(len(data[0])-1, dtype=np.float32) self.b = 0 self.l_rate = 0.1 # self.data = data def sign(self, x, w, b): y = np.dot(x, w) + b return y # 隨機梯度下降法 def fit(self, X_train, y_train): is_wrong = False while not is_wrong: wrong_count = 0 for d in range(len(X_train)): X = X_train[d] y = y_train[d] if y * self.sign(X, self.w, self.b) <= 0: self.w = self.w + self.l_rate*np.dot(y, X) self.b = self.b + self.l_rate*y wrong_count += 1 if wrong_count == 0: is_wrong = True return 'Perceptron Model!' def score(self): pass
感知機的收斂性

Novikoff定理說明:1)線性可分的樣本一定存在超平面將正負樣本分開;
2)誤分類次數有上限,經過有限次搜尋可以找到樣本完全正確分開的超平面,也就是說原始形式通過不斷迭代是收斂的。
3)當樣本線性不可分時,感知機演算法不收斂,原始形式迭代過程會發生震盪。
4)感知機的演算法存在許多解,依賴於初值選擇,也依賴於誤分類點在迭代過程中的順序。
5)在增加約束條件下,可以得到唯一分離超平面。
感知機學習對偶形式
感知機學習演算法對偶形式:
輸入:線性可分的資料集其中
,
,i=1,2...N,學習率
輸出:a,b: 感知機模型 ,其中a=
1)
2)在訓練集中選取資料
3)如果
4)轉至(2)直到沒有誤分類資料。
對偶形式中樣本例項以內積形式預先計算出來,儲存在Gram矩陣中。
對偶形式與原始形式本質一樣,它出現的意義在於:樣本點特徵向量以內積事先計算好,放在Gram矩陣中,在更新引數a、b時,直接
通過查詢矩陣,可以加快計算。
不妨假設特徵空間是,n很大,而樣本行數N遠小於n,如果採用原始形式時間複雜度為
;採用對偶形式的話,直接在Gram矩陣
裡查表就能拿到內積 ,所以這個誤判檢測的時間複雜度是
,大大降低了時間複雜度。
換句話說感知機的對偶形式,通過提前計算好樣本點內積並存儲於Grama Matrix,把每輪資料迭代的時間複雜度,從特徵空間維度n轉移
到樣本集大小的維度,達到了效能的提升。
參考推薦 李航《統計學習方法》 https://github.com/wzyonggege/statistical-learning-method https://www.zhihu.com/question/26526858/answer/253579695