
python爬蟲綜合篇,採集網易雲音樂全部歌手的熱門歌曲以及評論!

今天我給大家介紹一下用Python爬取網易雲音樂全部歌手的熱門歌曲.由於歌手個人主頁的網頁原始碼中還嵌入了一個子網頁(框架原始碼裡面包含了我們需要的資訊),因此我們不能使用requests庫來爬取,而使用selenium,接下來,讓我詳細講解整個爬取過程.
學習Python中有不明白推薦加入交流群
號:960410445
群裡有志同道合的小夥伴,互幫互助,
群裡有不錯的視訊學習教程和PDF!
一,構造歌手個人主頁的URL
前段時間我們獲取了網易雲音樂全部歌手的id號,今天我們就利用全部歌手的id號來構造歌手個人主頁的URL,從而實現用爬取全部歌手的熱門歌曲及其id號的目的.以歌手 薛之謙的個人主頁 為例,來看一下他的主頁的URL為:
https://music.163.com/#/artist?id=5781
因此只需要根據歌手對應的id就可以構造出歌手的個人主頁,在歌手的個人主頁我們能看到熱門作品這一欄.網易雲音樂全部歌手id號點選獲取(csv檔案)
二,分析網頁原始碼
現在我們就要用Python爬蟲去爬取這些內容.如果你用requests庫去爬取的話,返回的網頁原始碼中根本就沒有這些資訊.這時我們開啟薛之謙的個人主頁滑鼠右鍵分別檢視網頁的原始碼和檢視框架的原始碼.你會發現網頁原始碼和用requests庫請求返回的原始碼一摸一樣(裡面沒有我們要爬取的資訊),而在框架原始碼中有我們要爬取的熱門作品的資訊,因此我們只需要將框架原始碼爬取下來,然後再解析即可得到我們需要的歌手的熱門作品的資訊.
三,網頁原始碼和框架原始碼的區別
網頁原始碼是指父級網頁的原始碼.另外網頁中還有一種節點叫iframe,也就是子Frame,相當於網頁的子頁面,它的結構和外部網頁的結構完全一致,框架原始碼就是這個子網頁的原始碼.
四,獲取框架原始碼
這裡我們使用selenium庫來爬取,在selenium開啟頁面後,預設是在父級frame裡面進行操作,而此時頁面中還有子frame,它是不能獲取到子frame裡面的節點的,因此這時我們需要使用swith_to.frame()方法來切換到子frame中去,這時請求得到的程式碼就從網頁原始碼切換到了框架原始碼,於是我們便能夠提取我們需要的熱門作品的資訊了.通過歌手的個人主頁的URL來爬取其框架原始碼,具體爬取框架原始碼的函式:
def get_html_src(url):
# 可以任意選擇瀏覽器,前提是要配置好相關環境,更多請參考selenium官方文件
driver = webdriver.Chrome()
driver.get(url)
# 切換成frame
driver.switch_to_frame("g_iframe")
# 休眠3秒,等待載入完成!
time.sleep(3)
page_src = driver.page_source
driver.close()
return page_src
返回結果為歌手個人主頁的框架原始碼,裡面包含了我們需要的資訊.
五,解析原始碼
我們使用bs4庫進行解析,需要的資訊包含在HTML5的下面程式碼片段中:
<span class="txt"><a href="/song?id=(d*)"><b title="(.*?)">
因此可定義下面函式對其進行解析:
def parse_html_page(html):
# pattern = '<span class="txt"><a href="/song?id=(d*)"><b title="(.*?)">'
# 這裡是使用lxml解析器進行解析,lxml速度快,文件容錯能力強,也能使用html5lib
soup = BeautifulSoup(html, 'lxml')
items = soup.find_all('span', 'txt')
return items
六,寫入csv檔案
def write_to_csv(items, artist_name):
with open("music163_songs.csv", "a") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["歌手名字", artist_name])
for item in items:
writer.writerow([item.a['href'].replace('/song?id=', ''), item.b['title']])
print('歌曲id:', item.a['href'].replace('/song?id=', ''))
song_name = item.b['title']
print('歌曲名字:', song_name)
csvfile.close()
七,讀取csv檔案,構造全部歌手的個人主頁
# 獲取歌手id和歌手姓名
def read_csv():
with open("music163_artists.csv", "r", encoding="utf-8") as csvfile:
reader = csv.reader(csvfile)
for row in reader:
artist_id, artist_name = row
if str(artist_id) is "artist_id":
continue
else:
yield artist_id, artist_name
# 當程式的控制流程離開with語句塊後, 檔案將自動關閉
八,程式主函式
# 主函式
def main():
for readcsv in read_csv():
artist_id, artist_name = readcsv
url = "https://music.163.com/#/artist?id=" + str(artist_id)
print("正在獲取{}的熱門歌曲...".format(artist_name))
html = get_html_src(url)
items = parse_html_page(html)
print("{}的熱門歌曲獲取完成!".format(artist_name))
print("開始將{}的熱門歌曲寫入檔案".format(artist_name))
write_to_csv(items, artist_name)
print("{}的熱門歌曲寫入到本地成功!".format(artist_name))
用過網易雲音樂聽歌的朋友都知道,網易雲音樂每首歌曲後面都有很多評論,熱門歌曲的評論更是接近百萬或者是超過百萬條.現在我就來分享一下如何爬取網易雲音樂歌曲的全部評論,由於網易雲音樂的評論都做了混淆加密處理,因此我們需要深入瞭解它的加密過程之後才能爬取到網易雲音樂歌曲的全部評論.
一,首先分析資料的請求方式
網易雲音樂歌曲頁面的URL形式為
https://music.163.com/#/song?id=歌曲id號
這裡我用Delacey的Dream it possible 為例進行講解,它的URL為
https://music.163.com/#/song?id=38592976.
接下來開始分析資料的請求方式.
由於網易雲音樂的評論是通過Ajax傳輸,我們開啟瀏覽器的開發者工具(檢查元素),選中控制面板中的Network,再點選XHR(捕獲ajax資料),然後點選左上角的重新載入,會看到下面圖片中的資料請求列表
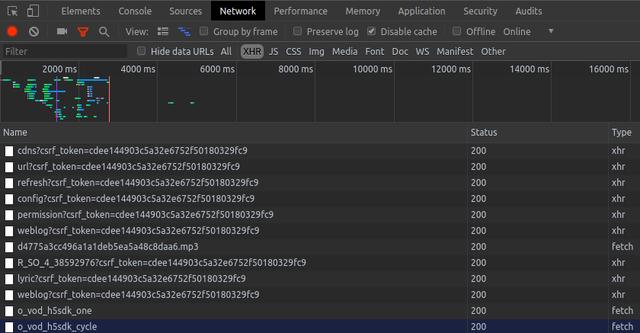
點選R_SO_4_38592976?csrf_token=cdee144903c5a32e6752f50180329fc9這一行,再點選Preview
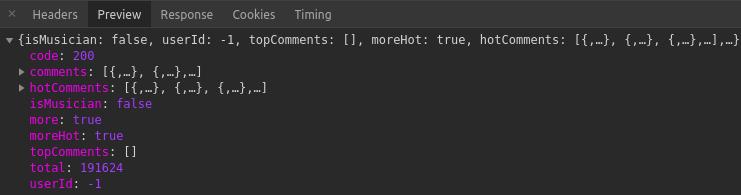
發現我們所需要的資料就在這json格式的資料中,其中comments中是第一頁的全部評論,一共20條,hotcomments是精彩評論一共有15條,每首歌曲只有第一頁評論才有精彩評論.接著看一下它的請求頭,點選Headers

我們發現的它是個post請求,向下滑你會發現這個post請求還帶有資料

這些資料都是經過加密處理的,因此我們需要分析它的加密過程來生成相應的引數,然後把加密後的引數加到post請求中才能獲取到我們需要的評論資料.
二,分析加密過程
通過斷點除錯發現params和encSecKey是由js指令碼中的window.asrsea()函式生成的.

我們發現window.asrsea()函式有4個引數,在瀏覽器的js控制檯分別對這四個引數進行除錯:

後面三個引數是定值,只有第一個引數是控制評論頁面偏移量的引數,它是一個變數.筆者經過分析發現第一個引數的形式是:
1
{"rid":"R_SO_4_38592976","offset":"0","total":"True","limit":"20","csrf_token":""}
下面我來詳細講解這個變數的發現過程:
首先找到core_dfe56728795d119e4d476fd09ea2dc51.js這個js指令碼,然後將斷點打在第12973行,點選第一頁評論,頁面載入到斷點處便停止了

然後按下電腦的Esc鍵開啟js控制檯,輸入i1x,檢視第一個變數:

這是第一頁的i1x的值,接下來看第二頁的(需要點選第2頁,然後輸入i1x的值):

再看第3頁:

再看第4頁:

通過這幾頁的分析,我們可以得到i1x值的變化規律,且可以得到它的一般形式:
{"rid":"R_SO_4_38592976","offset":"0","total":"True","limit":"20","csrf_token":""}
offset和limit是必選引數,其他引數是可選的,其他引數不影響data資料的生成,offset (頁面偏移量) = (頁數-1) * 20, 注意limit最大值為100,當設為100時,獲取第二頁時,預設前一頁是20個評論,也就是說第二頁最新評論有80個,有20個是第一頁顯示的.因此我們可以構造第一個引數為:
# 偏移量,page是頁數
offset = (page-1) * 20
msg = '{"offset":' + str(offset) + ',"total":"True","limit":"20","csrf_token":""}'
接下來,我們來看一下window.asrsea()函式的整個加密過程:
!function() {
// 函式a生成長度為16的隨機字串
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
// 函式b實現AES加密
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
// 函式c實現RSA加密
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d,
window.ecnonasr = e
}();
window.asrsea()函式就是上面的d函式,現在我們來看函式d:
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g), // 第一次AES加密
h.encText = b(h.encText, i), // 第二次AES加密
h.encSecKey = c(i, e, f), // RSA加密
h
}
引數h.encText是經過兩次AES加密得到的,h.encSecKey是經過一次RSA加密得到的,其中i是隨機生成的長度為16的隨機字串.
三,生成加密引數
首先我們需要生成長度為16的隨機字串,這裡我們仿照上面的javascript的實現,用Python生成16位長的隨機字串:
# 生成隨機字串 def generate_random_strs(length): string = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789" # 控制次數引數i i = 0 # 初始化隨機字串 random_strs = "" while i < length: e = random.random() * len(string) # 向下取整 e = math.floor(e) random_strs = random_strs + list(string)[e] i = i + 1 return random_strs
接著用Python實現AES加密,這裡要用到pycrypto庫,先安裝好這個庫:
pip install pycrypto
然後匯入加密模組:
from Crypto.Cipher import AES
由於AES加密的明文長度必須是16的倍數,因此我們需要對明文進行必要的填充,以滿足它的長度是16的倍數:
# msg是需要加密的明文,如果不是16的倍數則進行填充(paddiing) padding = 16 - len(msg) % 16 # 這裡使用padding對應的單字元進行填充 msg = msg + padding * chr(padding)
AES加密的模式是AES.MODE_CBC,初始化向量iv=’0102030405060708′,具體的AES加密:
# AES加密
def AESencrypt(msg, key):
# 如果不是16的倍數則進行填充(paddiing)
padding = 16 - len(msg) % 16
# 這裡使用padding對應的單字元進行填充
msg = msg + padding * chr(padding)
# 用來加密或者解密的初始向量(必須是16位)
iv = '0102030405060708'
cipher = AES.new(key, AES.MODE_CBC, iv)
# 加密後得到的是bytes型別的資料
encryptedbytes = cipher.encrypt(msg)
# 使用Base64進行編碼,返回byte字串
encodestrs = base64.b64encode(encryptedbytes)
# 對byte字串按utf-8進行解碼
enctext = encodestrs.decode('utf-8')
return enctext
然後是RSA加密.首先我簡單介紹一下RSA的加密過程.在RSA中,明文,金鑰和密文都是數字.RSA的加密過程可以用下列的公式來表達,這個公式非常的重要,你只有理解了這個公式,才能用Python實現RSA加密.
密文 = 明文E mod N (RSA加密)
RSA的密文是對代表明文的數字的E次方求mod N 的結果, 通俗的講就是將明文和自己做E次乘法,然後將其結果除以N 求餘數,這個餘數就是密文.
下面來看具體的RSA加密程式碼實現:
# RSA加密 def RSAencrypt(randomstrs, key, f): # 隨機字串逆序排列 string = randomstrs[::-1] # 將隨機字串轉換成byte型別資料 text = bytes(string, 'utf-8') seckey = int(codecs.encode(text, encoding='hex'), 16)**int(key, 16) % int(f, 16) return format(seckey, 'x').zfill(256)
RSA加密後得到的字串長為256,這裡不夠長我們用x字元填充.
最後就是獲取那兩個加密引數:
# 獲取引數
def get_params(page):
# msg也可以寫成msg = {"offset":"頁面偏移量=(頁數-1) * 20", "limit":"20"},offset和limit這兩個引數必須有(js)
# limit最大值為100,當設為100時,獲取第二頁時,預設前一頁是20個評論,也就是說第二頁最新評論有80個,有20個是第一頁顯示的
# 偏移量
offset = (page-1) * 20
# offset和limit是必選引數,其他引數是可選的,其他引數不影響data資料的生成,最好還是保留
msg = '{"offset":' + str(offset) + ',"total":"True","limit":"20","csrf_token":""}'
key = '0CoJUm6Qyw8W8jud'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
e = '010001'
enctext = AESencrypt(msg, key)
# 生成長度為16的隨機字串
i = generate_random_strs(16)
# 兩次AES加密之後得到params的值
encText = AESencrypt(enctext, i)
# RSA加密之後得到encSecKey的值
encSecKey = RSAencrypt(i, e, f)
return encText, encSecKey
四,獲取全部評論
上面我們獲取到了兩個引數encText和encSecKey,利用這兩個引數來構造post表單資料(Form Data),即data的值:
params, encSecKey = get_params(page)
data = {'params': params, 'encSecKey': encSecKey}
歌曲評論的URL為:
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(songid) + '?csrf_token='
然後把data加到post的引數中去就能獲取到json格式的評論資料.
html = requests.post(url, headers=headers, data=data)