
Spark2.1.0——SparkContext概述
Spark應用程式的提交離不開Spark Driver,後者是驅動應用程式在Spark叢集上執行的原動力。瞭解Spark Driver的初始化,有助於讀者理解Spark應用程式與Spark Driver的關係。
Spark Driver的初始化始終圍繞著SparkContext的初始化。SparkContext可以算得上是Spark應用程式的發動機引擎,轎車要想跑起來,發動機首先要啟動。SparkContext初始化完畢,才能向Spark叢集提交應用程式。發動機只需以較低的轉速,就可以在平坦的公路上游刃有餘;在山區,你可能需要一臺能夠提供大功率的發動機,這樣才能滿足你轉山的體驗。發動機的引數都是通過駕駛員操作油門、檔位等傳送給發動機的,而SparkContext的配置引數則由SparkConf負責,SparkConf(已在3.1節詳細介紹)就是你的操作面板。
SparkContext是Spark中的元老級API,從0.x.x版本就已經存在。有過Spark使用經驗的部分讀者也許感覺SparkContext已經太老了,然而SparkContext始終跟隨著Spark的迭代不斷向前。SparkContext的內部“血液”也發生了很多翻天覆地的變化,有些內部元件廢棄了,有些內部元件有了一些優化,而且還會不斷地輸入一些新鮮的“血液”。希望剛才這些描述沒有嚇到Spark的老使用者,因為Spark的靈魂——Spark核心原理,依然是那麼令人熟悉。
在講解SparkContext的初始化過程之前,我們先來認識下SparkContext中的各個組成部分,如圖1所示。
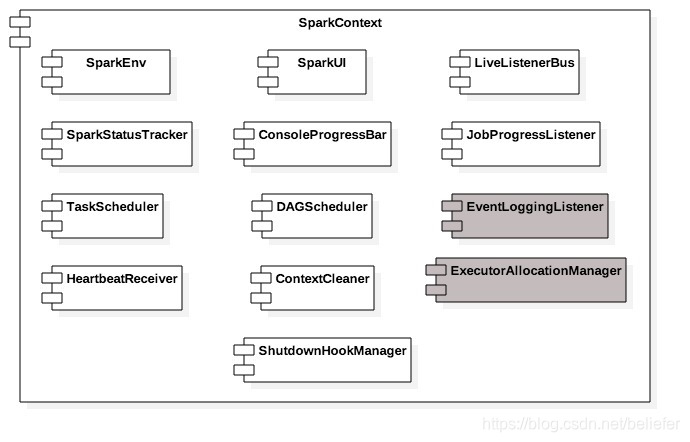
從圖1可以知道SparkContext主要由以下部分組成。
- SparkEnv:Spark執行時環境。Executor是處理任務的執行器,它依賴於SparkEnv提供的執行時環境。此外在Driver中也包含了SparkEnv,這是為了保證local模式下任務的執行。SparkEnv內部包含了很多元件,例如serializerManager、RpcEnv、BlockManager、mapOutputTracker等,讀者在這裡只需要認識它們即可,第5章將會對這些元件進行具體介紹。
- LiveListenerBus:SparkContext中的事件匯流排,可以接收各個使用方的事件,並且通過非同步方式對事件進行匹配後呼叫SparkListener的不同方法。LiveListenerBus的具體內容已經在3.3節詳細介紹,此處不再贅述。
- SparkUI:Spark的使用者介面。 SparkUI間接依賴於計算引擎、排程系統、儲存體系,作業(Job)、階段(Stage)、儲存、執行器(Executor)等元件的監控資料都會以SparkListenerEvent的形式投遞到LiveListenerBus中,SparkUI將從各個SparkListener中讀取資料並顯示到Web介面。
- SparkStatusTracker:提供對於作業、Stage(階段)等的監控資訊。SparkStatusTracker是一個低階的API,這意味著只能提供非常脆弱的一致性機制。
- ConsoleProgressBar:利用SparkStatusTracker的API,在控制檯展示Stage的進度。由於SparkStatusTracker存在的一致性問題,所以ConsoleProgressBar在控制檯的顯示往往有一定時延。
- DAGScheduler:DAG排程器,是排程系統中的重要元件之一。負責建立Job,將DAG中的RDD劃分到不同的Stage、提交Stage等。SparkUI中有關Job和Stage的監控資料都來自DAGScheduler。
- TaskScheduler:任務排程器,是排程系統中的重要元件之一。TaskScheduler按照排程演算法對叢集管理器已經分配給應用程式的資源進行二次排程後分配給任務。TaskScheduler排程的Task是由DAGScheduler建立的,所以DAGScheduler是TaskScheduler的前置排程。
- HeartbeatReceiver:心跳接收器。所有執行Executor都會向HeartbeatReceiver傳送心跳資訊,HeartbeatReceiver接收到Executor的心跳資訊後,首先更新Executor的最後可見時間,然後將此資訊交給TaskScheduler作進一步處理。
- ContextCleaner:上下文清理器。ContextCleaner實際用非同步方式清理那些超出應用作用域範圍的RDD、ShuffleDependency和Broadcast等資訊。
- JobProgressListener:作業進度監聽器。JobProgressListener在3.3.3節介紹SparkListener的繼承體系時提到過,根據之前的介紹我們知道JobProgressListener將註冊到LiveListenerBus中作為事件監聽器之一使用。
- EventLoggingListener:將事件持久化到儲存的監聽器,是SparkContext中的可選元件。當spark.eventLog.enabled屬性為true時啟用。
- ExecutorAllocationManager:Executor(執行器)動態分配管理器。顧名思義,可以根據工作負載動態調整Executor的數量。在配置spark.dynamicAllocation.enabled屬性為true的前提下,在非local模式下或者當spark.dynamicAllocation.testing屬性為true時啟用。
- ShutdownHookManager:用於設定關閉鉤子的管理器。可以給應用設定關閉鉤子,這樣就可以在JVM程序退出時,執行一些清理工作。
除了以上介紹的這些SparkContext內部元件,SparkContext內部還包括以下屬性:
- creationSite[2]:型別為CallSite,其中儲存著執行緒棧中最靠近棧頂的使用者定義的類及最靠近棧底的Scala或者Spark核心類資訊,CallSite的shortForm屬性儲存著以上資訊的簡短描述,CallSite的longForm屬性則儲存著以上資訊的完整描述。Spark自帶的examples專案中有對單詞進行計數的應用例子JavaWordCount,執行JavaWordCount得到的CallSite物件的屬性值分別為:
shortForm:“getOrCreate at JavaWordCount.java:48”;
longForm:“org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860)
org.apache.spark.examples.JavaWordCount.main(JavaWordCount.java:48)”。
- allowMultipleContexts:是否允許多個SparkContext例項。預設為false,可以通過屬性spark.driver.allowMultipleContexts來控制。
- startTime:SparkContext啟動的時間戳。
- stopped:標記SparkContext是否已經停止的狀態,採用原子型別AtomicBoolean。
- addedFiles:用於每個本地檔案的URL與新增此檔案到addedFiles時的時間戳之間的對映快取。
- addedJars:用於每個本地Jar檔案的URL與新增此檔案到addedJars時的時間戳之間的對映快取。
- persistentRdds:用於對所有持久化的RDD保持跟蹤。
- executorEnvs:用於儲存環境變數。executorEnvs中環境變數都將傳遞給執行任務的Executor使用。
- sparkUser:當前系統的登入使用者,也可以通過系統環境變數SPARK_USER進行設定。這裡使用的Utils的getCurrentUserName方法的更多介紹,請閱讀附錄A。
- checkpointDir:RDD計算過程中儲存檢查點時所需要的目錄。
- localProperties:由InheritableThreadLocal保護的執行緒本地變數,其中的屬性值可以沿著執行緒棧傳遞下去,供使用者使用。
- _conf:SparkContext的配置,通過呼叫SparkConf的clone方法的克隆體。[3]在SparkContext初始化的過程中會對conf中的配置資訊做校驗,例如:使用者必須給自己的應用程式設定spark.master(採用的部署模式)和spark.app.name(使用者應用的名稱);使用者設定的spark.master屬性為yarn時,spark.submit.deployMode屬性必須為cluster且必須設定spark.yarn.app.id屬性。
- _jars:使用者設定的Jar檔案。當用戶選擇的部署模式是yarn時,_jars是由spark.jars屬性指定的jar檔案和spark.yarn.dist.jars屬性指定的jar檔案的並集。其它模式下只採用由spark.jars屬性指定的jar檔案。這裡使用了Utils的getUserJars方法,其具體介紹請閱讀附錄A。
- _files:使用者設定的檔案。可以使用spark.files屬性進行指定。
- _eventLogDir:事件日誌的路徑。當spark.eventLog.enabled屬性為true時啟用。預設為/tmp/spark-events,也可以通過spark.eventLog.dir屬性指定。
- _eventLogCodec:事件日誌的壓縮演算法。當spark.eventLog.enabled屬性與spark.eventLog.compress屬性皆為true時啟用。壓縮演算法預設為lz4,也可以通過spark.io.compression.codec屬性指定。Spark目前支援的壓縮演算法包括:lzf、snappy和lz4三種。冪等
- _hadoopConfiguration:Hadoop的配置資訊,具體根據Hadoop(Hadoop2.0之前的版本)和Hadoop Yarn(Hadoop2.0+的版本)的環境有所區別。如果系統屬性SPARK_YARN_MODE為true或者環境變數SPARK_YARN_MODE為true,那麼將會是Yarn的配置,否則為Hadoop配置。
- _executorMemory:Executor的記憶體大小。預設值為1024MB。可以通過設定環境變數(SPARK_MEM或者SPARK_EXECUTOR_MEMORY)或者spark.executor.memory屬性指定。其中spark.executor.memory的優先順序最高,SPARK_EXECUTOR_MEMORY次之,SPARK_MEM是老版本Spark遺留下來的配置方式,未來將會廢棄。
- _applicationId:當前應用的標識。TaskScheduler啟動後會建立應用標識,SparkContext中的_applicationId就是通過呼叫TaskScheduler的applicationId方法獲得的。
- _applicationAttemptId:當前應用嘗試執行的標識。Spark Driver在執行時會多次嘗試執行,每次嘗試都將生成一個標識來代表應用嘗試執行的身份。
- _listenerBusStarted:LiveListenerBus是否已經啟動的標記。
- nextShuffleId:型別為AtomicInteger,用於生成下一個Shuffle的身份標識。
- nextRddId:型別為AtomicInteger,用於生成下一個RDD的身份標識。
[1] 圖中深色的元件是SparkContext中的可選元件。
[2] creationSite通過呼叫Utils.getCallSite獲得,Utils.getCallSite的詳細資訊見附錄A。
[3] SparkConf的詳細內容已在3.1節介紹,此處不再贅述。