
caffe,資料輸入層,分類資料label是圖片名字加上一個值,對於迴歸任務或者其他任務,標籤是一組值(一個向量)用hdf5
引言
如果關注Kaggle 機器學習專案的同學,一定很熟悉人臉關鍵點檢測這個任務,在2013 年的時候,ICML舉辦一個的challgene,現在放在kaggle 上作為 一種最常規kaggle入門任務而存在。
本文的主要目的在於驗證深度學習模型在人臉點檢測效果,踩踩裡面的坑。
任務介紹
人臉關鍵點檢測,也稱之為人臉點檢測,是在一張已經被人臉檢測器檢測到的人臉影象中,再進一步檢測出五官等關鍵點的二維座標資訊,以便於後期的人臉對齊(face alignment)任務。
根據不同的任務,需要檢測的關鍵點數目有多有少,有些僅要求檢測2隻眼睛的座標位置,有些要求檢測眼睛、嘴巴、鼻子的5個座標位置,還有更多的,68個位置,它包含了五官的輪廓資訊。 如圖所示:
根據任務,可以把要學習的模型函式表示為:
其中, 是輸入的人臉影象,是我們要學習的模型引數, 是我們需要檢測的人臉點座標位置。這是一個典型的迴歸問題,可以採用最簡單的平方誤差損失函式,然後用機器學習方法學習這個模型。
其中為預測的位置, 為標註的關鍵點位置。
很顯然,也很容易的就將該任務放到caffe中進行學習。
實驗過程:
資料準備
由於港中文[1]他們有公開了訓練集,所以我們就可以直接使用他們提供的影象庫就好了。 資料是需要轉化的:
1、框出人臉影象部分,從新計算關鍵點的座標 2、縮放人臉框大小,同時更新計算的關鍵點座標 3、一些資料增強處理:我只取樣了左右對稱的增強方法(還可以採用的資料增強方法有旋轉影象,影象平移部分) 轉換指令碼如下:
略- 1
- 1
資料轉化
跟以往的影象分類採用LMDB或者LevelDB 作為資料處理不同,這裡我們的標籤是一個向量,而不是一個值,所以不能直接用LMDB來作為儲存,還好,caffe提供了另外一種資料儲存方法來處理這種需求,那就是HDF5, 直觀的差別就在於LMDB的標籤是一個數,而HDF5 的標籤可以是任意(blob),也就是說對於分類任務,我們也可以取樣HDF5作為儲存的資料模式,但是HDF5直接讀取檔案,相比LMDB 速度上有所損失。
指令碼如下:
略- 1
- 1
網路結構
資料處理好之後,就可以開始設計網路結構了。 網路結構取樣的是參照[1]的網路結構,相比於其它的大型的網路的特點在於: 1,輸入影象小。 2,權值非共享。 這樣的網路相比ImageNet 上的那些模型的優點很明顯,引數比較少,學習相對快一些,
圖片1:是論文中描繪的網路結構: 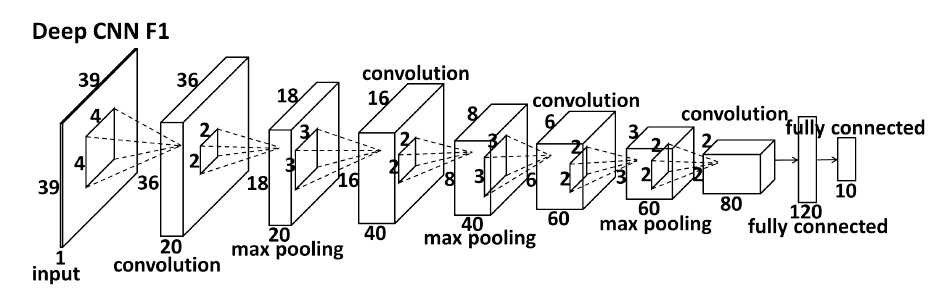
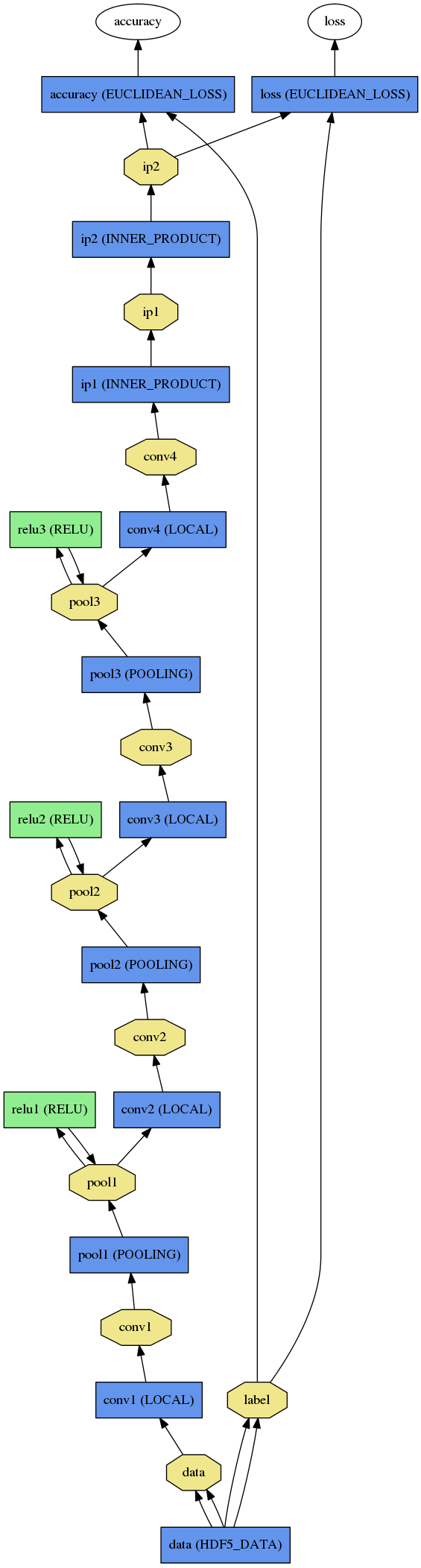
需要注意的是,caffe 的master分支是沒有local 層的,這個local 層去年(Caffe Local)就已經請求合併,然而由於各種原因卻一直未能合入正式的版本。大家可以從上面那個連結裡面clone 版本進行實驗。
實驗結果
正確的結果 失敗的結果
//update 2015.11.19://由於之前實驗人臉鏡面對稱的時候,沒有將左右眼睛和嘴巴的座標也對換,導致嘴巴和眼睛都不準的情況出現。感謝 @cyq0122 指出

實驗分析
用深度學習來做迴歸任務,很容易出現迴歸到均值的問題,在人臉關鍵點檢測的任務中,就是檢測到的人臉點是所有值的平均值。在上面失敗的例子中,兩隻眼睛和嘴巴預測的都比較靠近。//修正bug 過後就不會出現這個問題了。
這篇文章中,我只是嘗試復現人臉關鍵點檢測文章[1]的第一步,後面有時間的話,也會考慮用caffe 復現所有的結果。
要想完全的復現文章的結果,還需要: 1,級聯,從粗到細的檢測 2,訓練多個網路取平均值(各個網路的輸入影象塊不一樣)
程式碼託管
//update 2015.11.18:添加了資料處理的python檔案。
引用
[1] Y. Sun, X. Wang, and X. Tang. Deep Convolutional Network Cascade for Facial Point Detection. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013.