
Hive解決資料傾斜問題及Hive優化
阿新 • • 發佈:2018-12-21
資料傾斜概述
簡單來說資料傾斜就是資料的key的分化嚴重不均,造成一部分資料很多,一部分資料很少的情況。舉個word count的入門例子,在map階段形成了(“hello”,1)的形式,然後在reduce階段進行value統計,算出"hello"出現的次數,假設word count的文字大小是100G,其中70G都是"hello",剩下的30G是其它單詞,那就會形成70G的資料量交給一個reduce進行處理,其餘30G根據key的不同分散到對應的reduce進行處理,這樣的情況就會造成資料傾斜,結果就是其它reduce跑到99%以後一直在等待那個處理70G的reduce。
從另一角度看資料傾斜,其本質還是單臺節點在執行那部分資料reduce的時候,由於資料量大,造成任務進度緩慢。若這臺節點的機器記憶體和CPU、網路資源充足,處理100G和10M的資料所耗時間差不多,那也就不會存在其它reduce等待的現象,這點資料傾斜也掀不起什麼風浪,但是如果資料量非常的大,TB/PB級的時候,一旦資料量遠超機器的極限時就會造成reduce的緩慢甚至卡頓。日常工作中容易造成資料傾斜的原因可以歸納為如下幾點:
1.group by
2.distinct count(distinct xx)
3. join
group by 的資料傾斜處理
調優引數:
hive.map.aggr=true;
set hive.groupby.skewindata=true;
原理:hive.map.aggr=true 這個配置項代表是否在map端進行聚合
set hive.groupby.skewindata=true;資料傾斜時負載均衡,當設定為true,生成的查詢計劃會有兩個MRJob,第一個Job中Map的輸出結果集合會隨機分佈到Reduce中,每個reduce做部分聚合處理,並輸出結果,這樣處理的結果是相同groupby key有可能被分佈到不同的reduce中,從而達到負載均衡的目的。第二個MRJob再根據預處理的結果按照GroupBy key 分佈到reduce中(這個過程可以保證相同的GroupBy key 被分佈到同一個reduce中),完成最終的聚合操作,因此基本可以解決資料傾斜問題。
Hive優化
1.map side join
MapJoin的意思就是當連結的兩個表是一個比較小的表,一個是比較大的表的時候,把比較小的表直接放到記憶體中去,然後再對比較大的表進行Map操作,join就會在map操作的時候,每當掃描一個大的table中的資料,就要去檢視小表的資料,哪條與之相符,繼而進行連線。 這裡的join並不會涉及reduce操作。map端join的優勢就是在於沒有shuffle,在實際的應用中,我們這樣設定:
set hive.auto.convert.join=true; //將小表載入到記憶體中
此外hive有一個引數 hive.mapjoin.smalltable.filesize 預設值是25mb(其中一個表大小小於25m時,自動開啟mapjoin)。
注意:在hive做join時,要求小表在前(左)。
2.join 語句優化
優化前:select m.cid,
優化後:select m.cid,u.id from (select cid from order where dt=‘20181220’)m join customer u on m.cid = u.id;
注意;hive在做join時小表寫在前面。
3.group by優化
hive.groupby.skewindata=true;
如果group by 過程出現數據傾斜,應該設定為true
4.count distinct 優化
優化前:select count(distinct id) from tablename;
注意:count操作是全域性計數,在底層轉換MRJob時用於計數的分割槽(reduce Task)只有一個。
優化後:select count(*) from (select distinct id from tablename) tmp;
此外再設定一下reduce任務數量
注意:count這種全域性計數操作hive只會用一個reduce來實現。
日常統計場景中我們經常會對一段時期內的欄位進行去重並統計數量,SQL語句類似於:select count(distinct id) from table_name where…; 這條語句是從一個表符合where條件的記錄中統計不重複的id總數,此語句轉化為MapReduce後執行示意圖如下
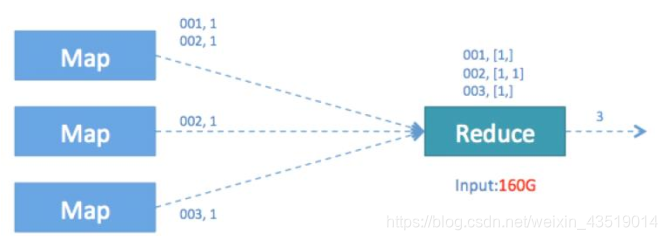
由於引入了distinct,因此在Map階段無法用combine對輸出的結果去重,必須將id作為key輸出,在Reduce階段再對來自於不同Map task 、相同key的結果進行去重,計入最終統計值。我們看到執行的Reduce Task 個數為1 ,對於統計大量資料時會導致最終Map的全部輸出由單個Reduce Task處理,這唯一 的Reduce Task需要Shuffle大量的資料,並且進行排序聚合等處理,這使得它成為整個作業的IO的運算瓶頸。
經過上述分析後,我們嘗試顯式地增大Reduce Task個數來提高Reduce階段的併發,使每一個Reduce Task的資料處理量控制在2G左右。具體設定如下:
set mapred.reduce.tasks=100
調整後我們發現這一引數並沒有影響實際Reduce Task個數,Hive執行時輸出
“Number of reduce tasks determined at compile time: 1”。
原因是Hive在處理count這種“全聚合(full aggregates)”計算時,它會忽略使用者指定的Reduce Task數,而強制使用1。
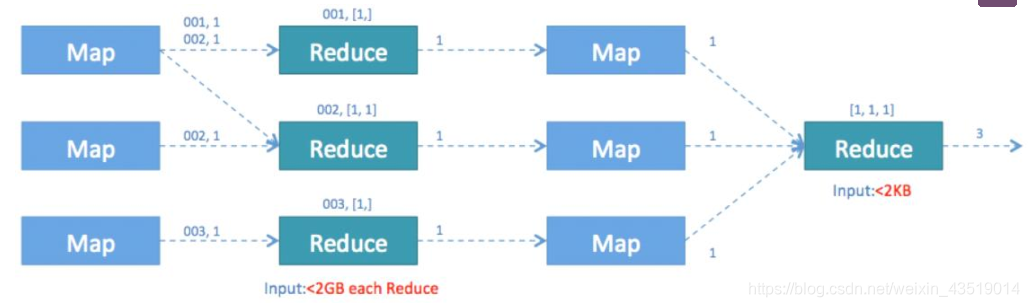
所以我們只能採用變通的方法來繞過這一限制。我們利用Hive對巢狀語句的支援,將原分割槽 hive02 的第 8 頁所以我們只能採用變通的方法來繞過這一限制。我們利用Hive對巢狀語句的支援,將原來一個MapReduce作業轉換為兩個作業,在第一階段選出全部的非重複id,在第二階段再對這些已消重的id進行計數。這樣在第一階段我們可以通過增大Reduce的併發數,併發處理Map輸出。在第二階段,由於id已經消重,因此count()操作在Map階段不需要輸出原id資料,只輸出一個合併後的計數即可。這樣即使第二階段Hive強制指
定一個Reduce Task,極少量的Map輸出資料也不會使單一的Reduce Task成為瓶頸。
改進後的SQL語句如下:
**select count() from (select distinct id from table_name where …);**
這一優化使得在同樣的執行環境下,優化後的語句執行只需要原語句20%左右的時間,優化後的MapReduce作業流程如下:
5.調整切片數(Map任務數)
Hive底層自動對小檔案做了優化,用了CombineTextInputFormat,將多個小檔案切片合成一個切片。合成完之後的切片大小,如果>mapred.max.split.size 的大小,就會生成一個新的切片。
mapred.max.split.size 預設是128MB
**set mapred.max.split.size=134217728 ** //(128MB)
對於切片數(MapTask)數量的調整,要根據實際業務來定,比如一個100MB的檔案,假設有1千萬條資料,此時可以調成10個MapTask,則每個MapTask處理1百萬條資料。
6.JVM重利用
set mapred.job.reuse.jvm.num.tasks=20(預設是1個)
JVM重用是hadoop調優引數的內容,對hive的效能具有非常大的影響,特別是對於很難避免小檔案的場景或者task特別多的場景,這類場景大多數執行時間都很短。這時JVM的啟動過程可能會造成相當大的開銷,尤其是執行的job包含有成千上萬個task任務的情況。
JVM重用可以使得一個JVM程序在同一個JOB中重新使用N次後才會銷燬。
7.啟用嚴格模式
在hive裡面可以通過嚴格模式防止使用者執行那些可能產生意想不到的查詢,從而保護hive的叢集。
可以通過 set hive.mapred.mode=strict 來設定嚴格模式,改成unstrict則為非嚴格模式。
在嚴格模式下,使用者在執行如下query的時候會報錯:
①分割槽表的查詢沒有使用分割槽欄位來限制
②使用了order by 但沒有使用limit語句。(如果不使用limit,會對查詢結果進行全域性排序,消耗時間長)
③產生了笛卡爾積
當用戶寫程式碼將表的別名寫錯的時候會引起笛卡爾積,例如
select * from origindb.promotion__campaign c JOIN origindb.promotion__campaignex ce ON c.id = c.id limit 1000;
8.關閉推測執行機制
因為在測試環境下我們都把應用程式測試OK了,如果還加上推測執行,如果有一個數據分片本來就會發生資料傾斜,執行時間就是比其他的時間長,那麼hive就會把這個執行時間長的job當作執行失敗,繼而又產生一個相同的job去執行,後果可想而知,可通過如下設定關閉推測執行:
set mapreduce.map.speculative=false
set mapreduce.reduce.speculative=false
set hive.mapred.reduce.tasks.speculative.execution=false