
探祕Java中的String、StringBuilder以及StringBuffer
探祕Java中String、StringBuilder以及StringBuffer
相信String這個類是Java中使用得最頻繁的類之一,並且又是各大公司面試喜歡問到的地方,今天就來和大家一起學習一下String、StringBuilder和StringBuffer這幾個類,分析它們的異同點以及瞭解各個類適用的場景。下面是本文的目錄大綱:
一.你瞭解String類嗎?
二.深入理解String、StringBuffer、StringBuilder
三.不同場景下三個類的效能測試
四.常見的關於String、StringBuffer的面試題(闢謠網上流傳的一些曲解String類的說法)
若有不正之處,請多多諒解和指正,不勝感激。
請尊重作者勞動成果,轉載請標明轉載地址:
一.你瞭解String類嗎?
想要了解一個類,最好的辦法就是看這個類的實現原始碼,String類的實現在
\jdk1.6.0_14\src\java\lang\String.java 檔案中。
開啟這個類檔案就會發現String類是被final修飾的:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
final int offset;
|
從上面可以看出幾點:
1)String類是final類,也即意味著String類不能被繼承,並且它的成員方法都預設為final方法。在Java中,被final修飾的類是不允許被繼承的,並且該類中的成員方法都預設為final方法。在早期的JVM實現版本中,被final修飾的方法會被轉為內嵌呼叫以提升執行效率。而從Java SE5/6開始,就漸漸擯棄這種方式了。因此在現在的Java SE版本中,不需要考慮用final去提升方法呼叫效率。只有在確定不想讓該方法被覆蓋時,才將方法設定為final。
2)上面列舉出了String類中所有的成員屬性,從上面可以看出String類其實是通過char陣列來儲存字串的。
下面再繼續看String類的一些方法實現:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
從上面的三個方法可以看出,無論是sub操、concat還是replace操作都不是在原有的字串上進行的,而是重新生成了一個新的字串物件。也就是說進行這些操作後,最原始的字串並沒有被改變。
在這裡要永遠記住一點:
“對String物件的任何改變都不影響到原物件,相關的任何change操作都會生成新的物件”。
在瞭解了於String類基礎的知識後,下面來看一些在平常使用中容易忽略和混淆的地方。
二.深入理解String、StringBuffer、StringBuilder
1.String str="hello world"和String str=new String("hello world")的區別
想必大家對上面2個語句都不陌生,在平時寫程式碼的過程中也經常遇到,那麼它們到底有什麼區別和聯絡呢?下面先看幾個例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
這段程式碼的輸出結果為
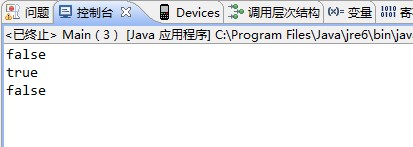
為什麼會出現這樣的結果?下面解釋一下原因:
在前面一篇講解關於JVM記憶體機制的一篇博文中提到 ,在class檔案中有一部分 來儲存編譯期間生成的 字面常量以及符號引用,這部分叫做class檔案常量池,在執行期間對應著方法區的執行時常量池。
因此在上述程式碼中,String str1 = "hello world";和String str3 = "hello world"; 都在編譯期間生成了 字面常量和符號引用,執行期間字面常量"hello world"被儲存在執行時常量池(當然只儲存了一份)。通過這種方式來將String物件跟引用繫結的話,JVM執行引擎會先在執行時常量池查詢是否存在相同的字面常量,如果存在,則直接將引用指向已經存在的字面常量;否則在執行時常量池開闢一個空間來儲存該字面常量,並將引用指向該字面常量。
總所周知,通過new關鍵字來生成物件是在堆區進行的,而在堆區進行物件生成的過程是不會去檢測該物件是否已經存在的。因此通過new來建立物件,創建出的一定是不同的物件,即使字串的內容是相同的。
2.String、StringBuffer以及StringBuilder的區別
既然在Java中已經存在了String類,那為什麼還需要StringBuilder和StringBuffer類呢?
那麼看下面這段程式碼:
|
1 2 3 4 5 6 7 8 9 |
|
這句 string += "hello";的過程相當於將原有的string變數指向的物件內容取出與"hello"作字串相加操作再存進另一個新的String物件當中,再讓string變數指向新生成的物件。如果大家還有疑問可以反編譯其位元組碼檔案便清楚了:
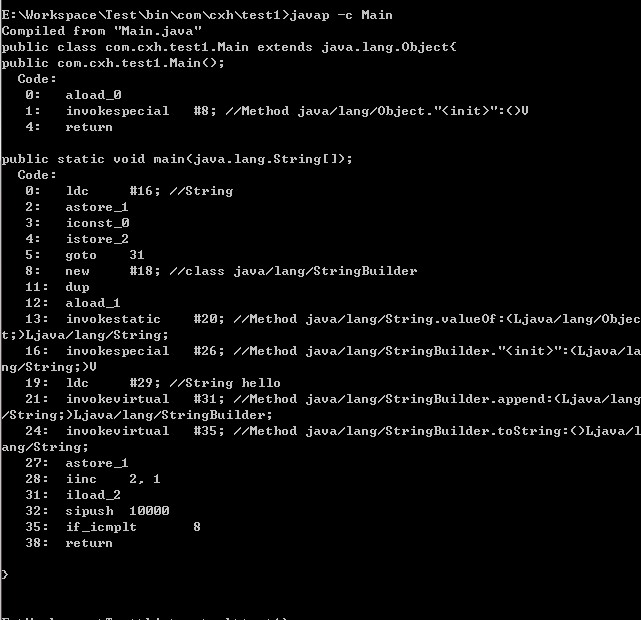
從這段反編譯出的位元組碼檔案可以很清楚地看出:從第8行開始到第35行是整個迴圈的執行過程,並且每次迴圈會new出一個StringBuilder物件,然後進行append操作,最後通過toString方法返回String物件。也就是說這個迴圈執行完畢new出了10000個物件,試想一下,如果這些物件沒有被回收,會造成多大的記憶體資源浪費。從上面還可以看出:string+="hello"的操作事實上會自動被JVM優化成:
StringBuilder str = new StringBuilder(string);
str.append("hello");
str.toString();
再看下面這段程式碼:
|
1 2 3 4 5 6 7 8 9 |
|
反編譯位元組碼檔案得到:
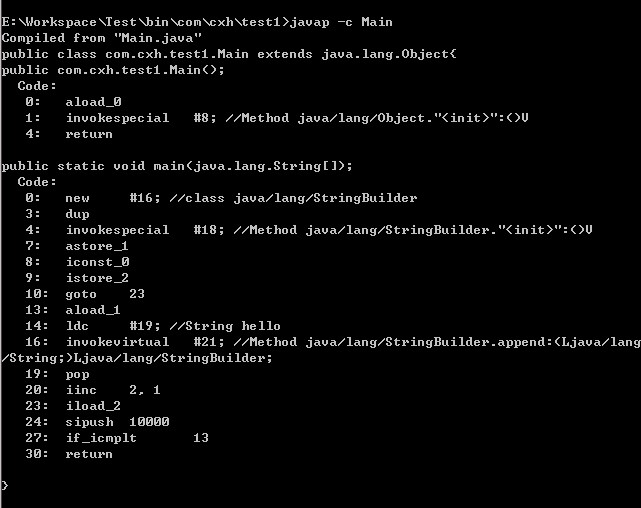
從這裡可以明顯看出,這段程式碼的for迴圈式從13行開始到27行結束,並且new操作只進行了一次,也就是說只生成了一個物件,append操作是在原有物件的基礎上進行的。因此在迴圈了10000次之後,這段程式碼所佔的資源要比上面小得多。
那麼有人會問既然有了StringBuilder類,為什麼還需要StringBuffer類?檢視原始碼便一目瞭然,事實上,StringBuilder和StringBuffer類擁有的成員屬性以及成員方法基本相同,區別是StringBuffer類的成員方法前面多了一個關鍵字:synchronized,不用多說,這個關鍵字是在多執行緒訪問時起到安全保護作用的,也就是說StringBuffer是執行緒安全的。
下面摘了2段程式碼分別來自StringBuffer和StringBuilder,insert方法的具體實現:
StringBuilder的insert方法
|
1 2 3 4 5 6 |
|
StringBuffer的insert方法:
|
1 2 3 4 5 6 |
|
三.不同場景下三個類的效能測試
從第二節我們已經看出了三個類的區別,這一小節我們來做個小測試,來測試一下三個類的效能區別:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
|
測試結果(win7,Eclipse,JDK6):

上面提到string+="hello"的操作事實上會自動被JVM優化,看下面這段程式碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
執行結果:
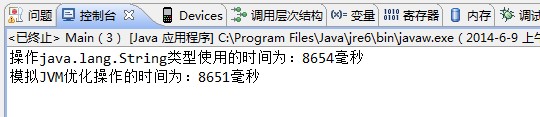
得到驗證。
下面對上面的執行結果進行一般性的解釋:
1)對於直接相加字串,效率很高,因為在編譯器便確定了它的值,也就是說形如"I"+"love"+"java"; 的字串相加,在編譯期間便被優化成了"Ilovejava"。這個可以用javap -c命令反編譯生成的class檔案進行驗證。
對於間接相加(即包含字串引用),形如s1+s2+s3; 效率要比直接相加低,因為在編譯器不會對引用變數進行優化。
2)String、StringBuilder、StringBuffer三者的執行效率:
StringBuilder > StringBuffer > String
當然這個是相對的,不一定在所有情況下都是這樣。
比如String str = "hello"+ "world"的效率就比 StringBuilder st = new StringBuilder().append("hello").append("world")要高。
因此,這三個類是各有利弊,應當根據不同的情況來進行選擇使用:
當字串相加操作或者改動較少的情況下,建議使用 String str="hello"這種形式;
當字串相加操作較多的情況下,建議使用StringBuilder,如果採用了多執行緒,則使用StringBuffer。
四.常見的關於String、StringBuffer的面試題
下面是一些常見的關於String、StringBuffer的一些面試筆試題,若有不正之處,請諒解和批評指正。
1. 下面這段程式碼的輸出結果是什麼?
String a = "hello2"; String b = "hello" + 2; System.out.println((a == b));
輸出結果為:true。原因很簡單,"hello"+2在編譯期間就已經被優化成"hello2",因此在執行期間,變數a和變數b指向的是同一個物件。
2.下面這段程式碼的輸出結果是什麼?
String a = "hello2"; String b = "hello"; String c = b + 2; System.out.println((a == c));
輸出結果為:false。由於有符號引用的存在,所以 String c = b + 2;不會在編譯期間被優化,不會把b+2當做字面常量來處理的,因此這種方式生成的物件事實上是儲存在堆上的。因此a和c指向的並不是同一個物件。javap -c得到的內容:

3.下面這段程式碼的輸出結果是什麼?
String a = "hello2"; final String b = "hello"; String c = b + 2; System.out.println((a == c));
輸出結果為:true。對於被final修飾的變數,會在class檔案常量池中儲存一個副本,也就是說不會通過連線而進行訪問,對final變數的訪問在編譯期間都會直接被替代為真實的值。那麼String c = b + 2;在編譯期間就會被優化成:String c = "hello" + 2; 下圖是javap -c的內容:

4.下面這段程式碼輸出結果為:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
輸出結果為false。這裡面雖然將b用final修飾了,但是由於其賦值是通過方法呼叫返回的,那麼它的值只能在執行期間確定,因此a和c指向的不是同一個物件。
5.下面這段程式碼的輸出結果是什麼?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
輸出結果為(JDK版本 JDK6):
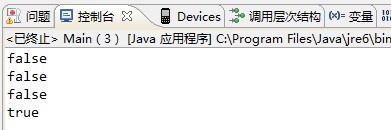
這裡面涉及到的是String.intern方法的使用。在String類中,intern方法是一個本地方法,在JAVA SE6之前,intern方法會在執行時常量池中查詢是否存在內容相同的字串,如果存在則返回指向該字串的引用,如果不存在,則會將該字串入池,並返回一個指向該字串的引用。因此,a和d指向的是同一個物件。
6.String str = new String("abc")建立了多少個物件?
這個問題在很多書籍上都有說到比如《Java程式設計師面試寶典》,包括很多國內大公司筆試面試題都會遇到,大部分網上流傳的以及一些面試書籍上都說是2個物件,這種說法是片面的。
如果有不懂得地方可以參考這篇帖子:
首先必須弄清楚建立物件的含義,建立是什麼時候建立的?這段程式碼在執行期間會建立2個物件麼?毫無疑問不可能,用javap -c反編譯即可得到JVM執行的位元組碼內容:

很顯然,new只調用了一次,也就是說只建立了一個物件。
而這道題目讓人混淆的地方就是這裡,這段程式碼在執行期間確實只建立了一個物件,即在堆上建立了"abc"物件。而為什麼大家都在說是2個物件呢,這裡面要澄清一個概念 該段程式碼執行過程和類的載入過程是有區別的。在類載入的過程中,確實在執行時常量池中建立了一個"abc"物件,而在程式碼執行過程中確實只建立了一個String物件。
因此,這個問題如果換成 String str = new String("abc")涉及到幾個String物件?合理的解釋是2個。
個人覺得在面試的時候如果遇到這個問題,可以向面試官詢問清楚”是這段程式碼執行過程中建立了多少個物件還是涉及到多少個物件“再根據具體的來進行回答。
7.下面這段程式碼1)和2)的區別是什麼?
|
1 2 3 4 5 6 7 8 |
|
1)的效率比2)的效率要高,1)中的"love"+"java"在編譯期間會被優化成"lovejava",而2)中的不會被優化。下面是兩種方式的位元組碼:
1)的位元組碼:

2)的位元組碼:

可以看出,在1)中只進行了一次append操作,而在2)中進行了兩次append操作。