
39-天亮大資料系列教程之SparkCore核心基礎之part1
目錄 1、Spark架構設計 2、執行模式與使用者互動方式 3、java實現spark wordcount示例 4、scala實現spark wordcount示例 5、經典習題
詳情 1、Spark架構設計
-
1.1 架構設計圖
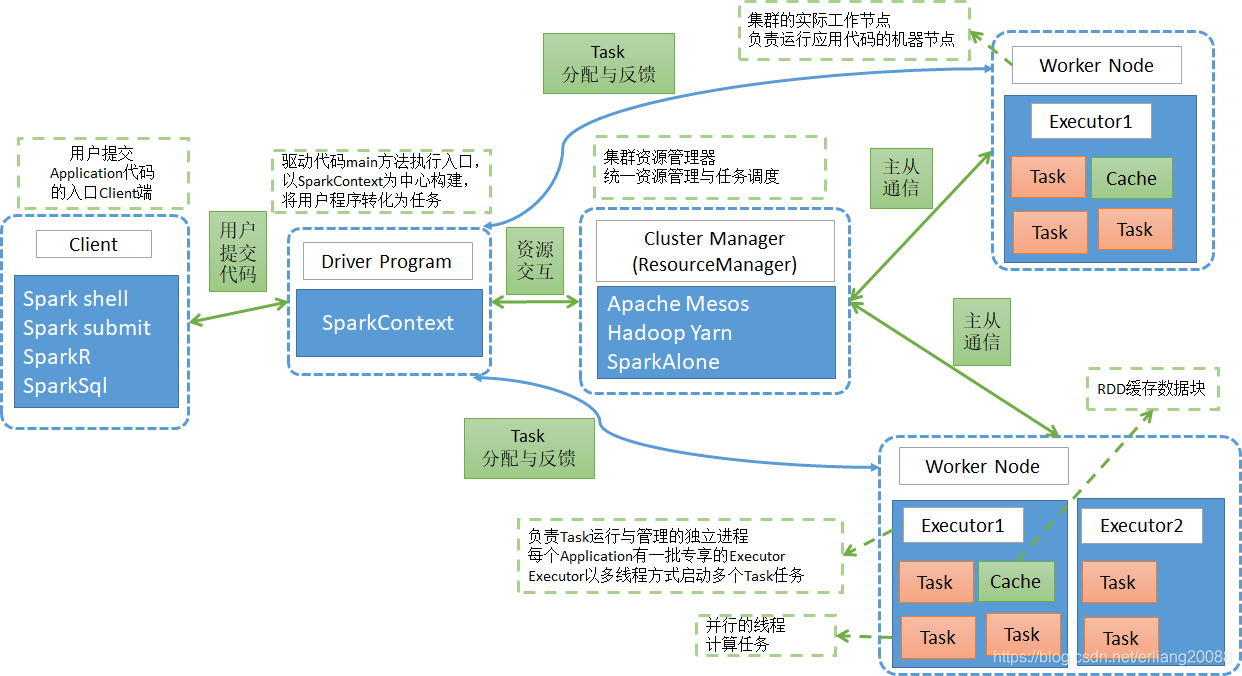
-
1.2 相關術語名詞解釋
-
RDD (Resilient Distributed DataSet)
- 彈性分散式資料集,是對資料集在spark儲存和計算過程中的一種抽象。
- 是一組只讀、可分割槽的的分散式資料集合
- 一個RDD 包含多個分割槽Partition(類似於MapReduce中的InputSplit),分割槽是依照一定的規則的,將具有相同規則的屬性的資料記錄放在一起 。
- 橫向上可切分平行計算,以分割槽Partition為切分後的最小儲存和計算單元。
- 縱向上可進行內外存切換使用,即當資料在記憶體不足時,可以用外存磁碟來補充。
-
Partition(分割槽)
- Partition類似hadoop的Split,計算是以partition為單位進行的,提供了一種劃分資料的方式。
- partition的劃分依據有很多,可以自己定義的,像HDFS檔案,劃分的方式就和MapReduce一樣,以檔案的block來劃分不同的partition。
- 一個Partition交給一個Task去計算處理
-
運算元
- 英文簡稱:Operator
- 廣義上講,對任何函式進行某一項操作都可以認為是一個運算元
- 通俗上講,運算元即為對映、關係、變換。
- MapReduce運算元,主要分為兩個,即為Map和Reduce兩個主要操作的運算元,導致靈活可用性比較差。
- Spark運算元,分為兩大類,即為Transformation和Action類,合計有80多個。
-
Transformation類運算元
-
操作是延遲計算的,也就是說從一個RDD 轉換生成另一個 RDD 的轉換操作不是馬上執行,需要等到有 Action 操作的時候才會真正觸發運算。
-
細分類
- Value資料型別的Transformation運算元
- Key-Value資料型別的Transfromation運算元
-
-
Action類運算元
- 會觸發 Spark 提交作業(Job),並將資料輸出 Spark系統。
-
窄依賴
- 如果一個父RDD的每個分割槽只被子RDD的一個分割槽使用 ----> 一對一關係
-
寬依賴
- 如果一個父RDD的每個分割槽要被子RDD 的多個分割槽使用 ----> 一對多關係
-
Application
- Spark Application的概念和MapReduce中的job或者yarn中的application類似,指的是使用者編寫的Spark應用程式,包含了一個Driver 功能的程式碼和分佈在叢集中多個節點上執行的Executor程式碼;
- 一般是指整個Spark專案從開發、測試、佈署、執行的全部。
-
Driver
-
執行main函式並且建立SparkContext的程式。
稱為驅動程式,Driver Program類似於hadoop的wordcount程式的main函式。
-
-
-
-
Cluster Manager
- 叢集的資源管理器,在叢集上獲取資源的外部服務。如Yarn、Mesos、Spark Standalone等。
- 以Yarn為例,驅動程式會向Yarn申請計算我這個任務需要多少的記憶體,多少CPU等,後由Cluster Manager會通過排程告訴驅動程式可以使用,然後驅動程式將任務分配到既定的Worker Node上面執行。
-
WorkerNode
-
叢集中任何一個可以執行spark應用程式碼的節點。
Worker Node就是物理機器節點,可以在上面啟動Executor程序。
-
-
Executor
- Application執行在Worker節點上的一個程序,該程序負責執行Task,並且負責將資料存在記憶體或者磁碟上,每個Application都有各自獨立專享的一批Executor。
- Executor即為spark概念的資源容器,類比於yarn的container容器,真正承載Task的執行與管理,以多執行緒的方式執行Task,更加高效快速。
-
Task
-
與Hadoop中的Map Task或者Reduce Task是類同的。
-
分配到executor上的基本工作單元,執行實際的計算任務。
-
Task分為兩類,即為ShuffleMapTask和ResultTask。
- ShuffleMapTask:即為Map任務和發生Shuffle的任務的操作,由Transformation操作組成,其輸出結果是為下個階段任務(ResultTask)進行做準備,不是最終要輸出的結果。
- ResultTask:即為Action操作觸發的Job作業的最後一個階段任務,其輸出結果即為Application最終的輸出或儲存結果。
-
-
Job(作業)
-
Spark RDD 裡的每個action的計算會生成一個job。
-
使用者提交的Job會提交給DAGScheduler(Job排程器),Job會被分解成Stage去執行,
每個Stage由一組相同計算規則的Task組成,該組Task也稱為TaskSet, 實際交由TaskScheduler去排程Task的機器執行節點, 最終完成作業的執行。
-
-
Stage(階段)
-
Stage是Job的組成部分,每個Job可以包含1個或者多個Stage。
-
Job切分成Stage是以Shuffle作為分隔依據,Shuffle前是一個Stage,Shuffle後是一個Stage。
即為按RDD寬窄依賴來劃分Stage。
-
-
每個Job會被拆分很多組Task,每組任務被稱為Stage,也可稱TaskSet,一個作業分為多個階段;
2、spark執行模式與使用者互動方式 * 執行模式
* 即作業以什麼樣的模式去執行,主要是單機、分散式兩種方式的細節選擇。
序號模式名稱特點應用場景 1本地執行模式(local)單臺機器多執行緒來模擬spark分散式計算機器資源不夠測試驗證程式邏輯的正確性 2偽分散式模式單臺機器多程序來模擬spark分散式計算機器資源不夠測試驗證程式邏輯的正確性 3standalone(client)獨立佈署spark計算叢集自帶clustermanagerdriver執行在spark submit client端機器資源充分純用spark計算框架任務提交後在spark submit client端實時檢視反饋資訊 4standalone(cluster)獨立佈署spark計算叢集自帶clustermanagerdriver執行在spark worknode端機器資源充分純用spark計算框架任務提交後將退出spark submit client端 5spark on yarn(yarn-client)以yarn叢集為基礎只新增spark計算框架相關包driver執行在yarn client上機器資源充分多種計算框架混用資料共享性強任務提交後在yarn client端實時檢視反饋資訊 6spark on yarn(yarn-cluster)以yarn叢集為基礎只新增spark計算框架相關包driver執行在叢集的am contianer中機器資源充分多種計算框架混用資料共享性強任務提交後將退出yarn client端 7spark on mesos/ec2與spark on yarn類似與spark on yarn類似在國內應用較少
-
使用者互動方式
- 互動方式列表
- 1、spark-shell: spark命令列方式來操作spark作業。
-
多用於簡單的學習、測試、簡易作業操作。
-
2、spark-submit: 通過程式指令碼,提交相關的程式碼、依賴等來操作spark作業。
- 最多見的提交任務的互動方式,簡單易用、引數齊全。
-
3、spark-sql :通過sql的方式操作spark作業。
- sql相關的學習、測試、生產環境研發均可以使用該直接操作互動方式。
-
4、spark-class: 最低層的呼叫方式,其它呼叫方式多是最終轉化到該方式中去提交。
- 直接使用較少
-
5、sparkR,sparkPython:通過其它非java、scala語言直接操作spark作業的方式。
- R、python語言使用者的互動方式。
-
-
重要互動方式使用介紹
-
重點說明spark-shell,spark-submit兩大方式,spark-sql後有專門章節介紹,其它小眾方式不做介紹。
-
1、spark-shell
-
互動方式定位
- 一個強大的互動式資料操作與分析的工具,提供一個簡單的方式快速學習spark相關的API。
-
啟動方式
- 前置環境:已將spark-shell等互動式指令碼已加入系統PATH變數,可在任意位置使用。
-
-
-
- 1、spark-shell: spark命令列方式來操作spark作業。
- 互動方式列表
#以本地2個執行緒來模擬執行spark相關操作,該數量一般與本機的cpu核數相一致為最佳spark-shell --master local[2]
- 相關引數
-
引數列表獲取方式:spark-shell --help
- 其引數非常多,但由於該方式主要是簡單學習使用,故其引數使用極少,故不做詳解。
-
使用示例介紹
- 互動式入口
-
構建一個scala列表,並輸出
-
通過scala列表,構造一個rdd,並進行基本操作
-
通過本地文字檔案構建rdd,並進行基本操作
-
通過hdfs文字檔案構建rdd,並進行基本操作
-
對rdd進行字串過濾操作
-
對rdd進行求最大值操作
-
對輸入進行wodcount計算-無排序
-
對輸入進行wodcount計算-按詞頻降序排列輸出
-
2、spark-submit
-
互動方式定位
- 最常用的通過程式指令碼,提交相關的程式碼、依賴等來操作spark作業的方式。
-
啟動方式
- spark-submit提交任務的模板 spark-submit \ --class \ --master \ --jars jar_list_by_comma \ --conf = \ … # other options \ [application-arguments]
-
-
天亮教育是一家從事大資料雲端計算、人工智慧、教育培訓、產品開發、諮詢服務、人才優選為一體的綜合型網際網路科技公司。 公司由一批BAT等一線網際網路IT精英人士建立, 以"快樂工作,認真生活,打造高階職業技能教育的一面旗幟"為願景,胸懷"讓天下沒有難找的工作"使命, 堅持"客戶第一、誠信、激情、擁抱變化"的價值觀, 全心全意為學員賦能提效,踐行技術改變命運的初心。
歡迎關注天亮教育公眾號,大資料技術資料與課程、招生就業動態、教育資訊動態、創業歷程分享一站式分享,官方微信公眾號二維碼:

天亮教育官方群318971238, 爬蟲、nlp技術qq群320349384 hadoop & spark & hive技術群297585251, 官網:http://myhope365.com 官方天亮論壇:http://bbs.myhope365.com/