
38-天亮大資料系列教程之初識Spark
阿新 • • 發佈:2018-12-21
目錄
1、spark的背景、定義、意義
2、在hadoop生態圈中位置
3、版本發展與就業前景詳情1、spark的背景、定義、特點
- 背景
-
MapReduce框架侷限性
-
僅支援Map和Reduce兩種操作,提供給使用者的只有這兩種操作
-
程式設計複雜度略高,學習和使用成本略高。
-
處理效率低效
- Map中間結果寫磁碟,Reduce寫HDFS,多個MR之間通過HDFS交換資料
- 任務排程和啟動開銷大
- 在機器學習、圖計算等方面支援有限,效能效率表現比較差。
- mapreduce的機器學習框架,稱為mahout。
-
定義
- 專為大規模資料處理而設計的快速通用的計算引擎,並形成一個高速發展應用廣泛的生態系統。
-
特點
-
速度快
- 記憶體計算下,Spark 比 Hadoop 快100倍
-
易用性
- 80多個高階運算子
- 跨語言:使用Java,Scala,Python,R和SQL快速編寫應用程式。
-
通用性
- Spark 提供了大量的庫,包括SQL、DataFrames、MLib、GraphX、Spark Streaming。
- 開發者可以在同一個應用程式中無縫組合使用這些庫。
-
-
支援多種資源管理器
- Spark 支援 Hadoop YARN,Apache Mesos,及其自帶的獨立叢集管理器
-
生態元件豐富與成熟
- spark streaming :實時資料處理
- shark/sparkSQL : 用sql語句操作spark引擎
- sparkR : 用R語言操作Spark
- mlib : 機器學習演算法庫
- graphx : 圖計算元件
-
2、在hadoop生態圈中位置
* 在hadoop生態圈位置
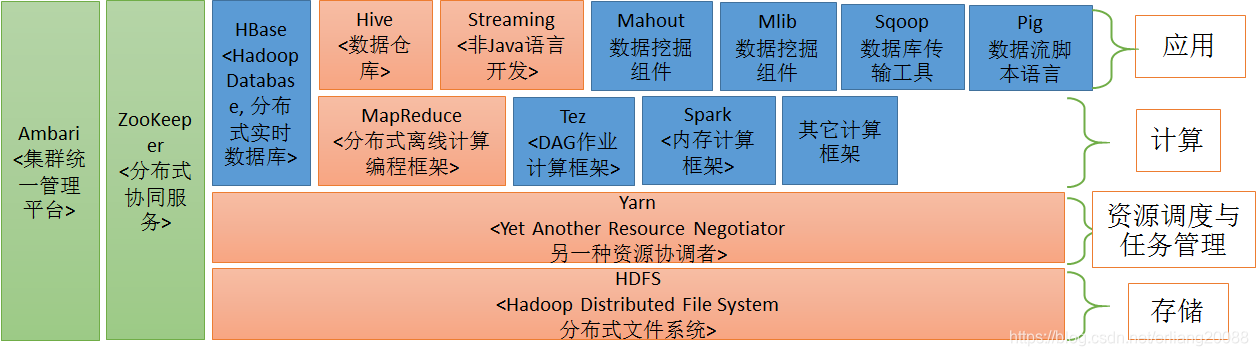
* spark生態圈
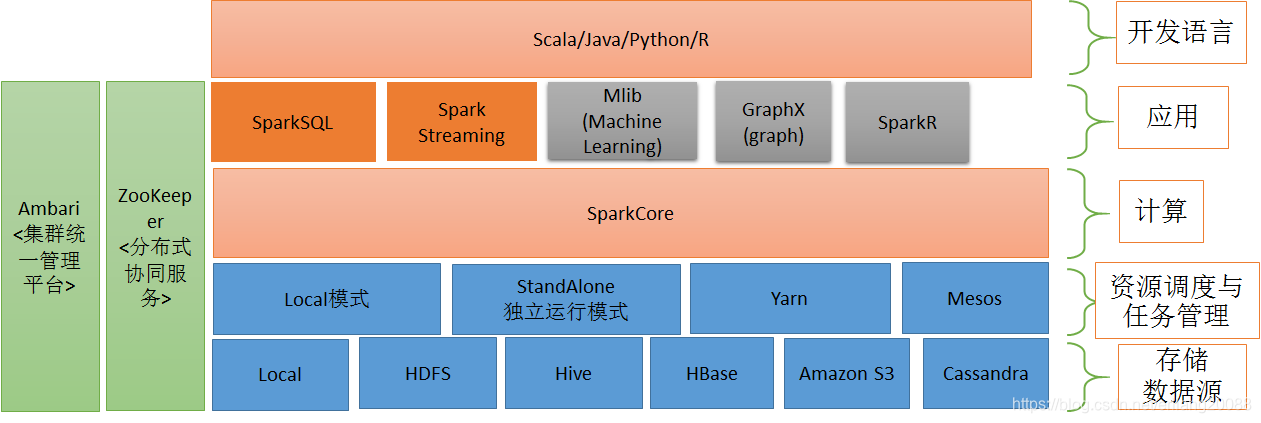
- Spark Core:包含Spark的基本功能;尤其是定義RDD(彈性分散式資料集)的API、操作以及這兩者上的動作。其他Spark的庫都是構建在RDD和Spark Core之上的
- Spark SQL:提供通過Apache Hive的SQL變體Hive查詢語言(HiveQL)與Spark進行互動的API。每個資料庫表被當做一個RDD,Spark SQL查詢被轉換為Spark操作。
- Spark Streaming:對實時資料流進行處理和控制。Spark Streaming允許程式能夠像普通RDD一樣處理實時資料
- MLib:一個常用機器學習演算法庫,演算法被實現為對RDD的Spark操作。這個庫包含可擴充套件的學習演算法,比如分類、迴歸等需要對大量資料集進行迭代的操作。
- GraphX:控制圖、並行圖操作和計算的一組演算法和工具的集合。GraphX擴充套件了RDD API,包含控制圖、建立子圖、訪問路徑上所有頂點的操作
- SparkR是一個提供從R中使用Spark的輕量級前端的R包。在Spark1.6以後,SparkR提供了分散式資料框架,它支援selection,filtering,aggregation等操作。也支援使用MLib分散式機器學習。
3、版本發展與就業前景
- 版本發展
-
重要里程碑
-
穩定版本一覽( 2016年至今)
Spark 2.3.1 (Jun 08 2018)
Spark 2.3.0 (Feb 28 2018)
Spark 2.2.2 (Jul 02 2018)

我們選擇經典的1.6.2版本,成熟穩定,市佔率高。 -
spark1.x與2.x的優缺點對比
-
優點
- API抽象更高階、更統一,包括在spark-core,sparksql,sparksession等方面,學習更簡單,開發效率更高,執行效率綜合提升明顯。
- 統一DataFrames和DataSets為DataSets,API進行了全部統一,簡化學習和程式設計複雜度。
基本定位是低層API程式設計延用RDD,高階API程式設計均為DataSets,而大多數情況下用DataSets均可以解決問題。 * spark-streaming基於spark sql進行了API更高階抽象,即structured streaming(結構化流式程式設計),易用性和效能雙雙提高。 - 對諸多元件中的舊的rdd計算邏輯用DataFrame或DataSet進行了重寫優化,並擴充了更多的演算法。
-
缺點
- 對以前版本不是完全相容,只是絕大部分相容。
- 相對於1.6.x來講,穩定性略差, bug不斷。
-
-
就業前景
- 成熟度相比於hadoop還差一些,但自身迭代和生態圈發展很快。
- 業務對實時性要求日漸增高,各大公司和小公司都在積極調研轉向spark,都需要懂spark的人
- Spark特別適合於迭代運算比較多的機器學習演算法,而機器學習正在如火如荼發展中。
- Spark未來可能會取代MapReduce,但與Hadoop仍會友好共生。
- 基於記憶體計算是最大優勢,而記憶體瓶頸會越來越少,故Spark的爆發點還有很大空間。
- 總結:崗位需求量和發展前景都很廣闊,是未來3-5年的技術應用最大熱門。
-
天亮教育是一家從事大資料雲端計算、人工智慧、教育培訓、產品開發、諮詢服務、人才優選為一體的綜合型網際網路科技公司。
公司由一批BAT等一線網際網路IT精英人士建立,
以"快樂工作,認真生活,打造高階職業技能教育的一面旗幟"為願景,胸懷"讓天下沒有難找的工作"使命,
堅持"客戶第一、誠信、激情、擁抱變化"的價值觀,
全心全意為學員賦能提效,踐行技術改變命運的初心。
歡迎關注天亮教育公眾號,大資料技術資料與課程、招生就業動態、教育資訊動態、創業歷程分享一站式分享,官方微信公眾號二維碼:
