
新一代分布式任務調度框架:當當elastic-job開源項目的10
阿新 • • 發佈:2018-12-21
判斷 oba 早期 cep gin bean 社區 之前 都是
原文地址:https://www.cnblogs.com/qiumingcheng/p/5573845.html
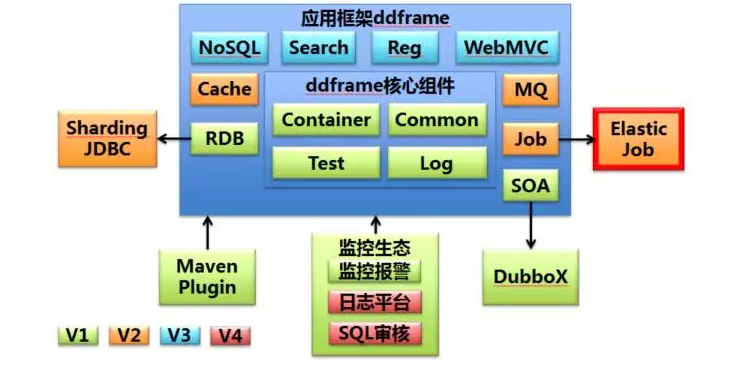
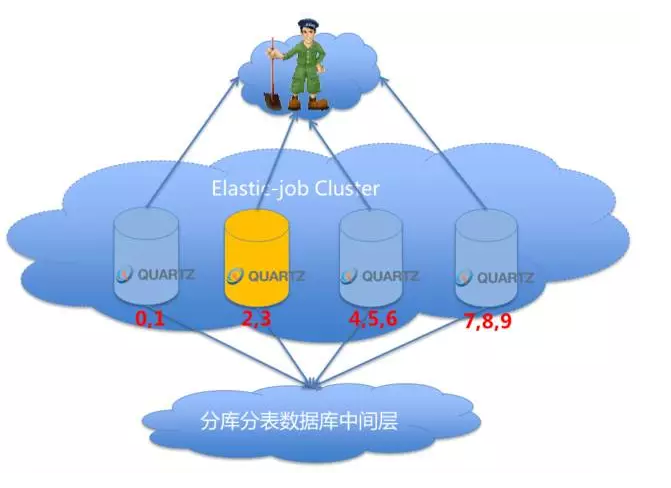
作者簡介: 張亮,當當網架構師、當當技術委員會成員、消息中間件組負責人。對架構設計、分布式、優雅代碼等領域興趣濃厚。目前主導當當應用框架ddframe研發,並負責推廣及撰寫技術白皮書。 一、為什麽需要作業(定時任務)? 作業即定時任務。一般來說,系統可使用消息傳遞代替部分使用作業的場景。兩者確有相似之處。可互相替換的場景,如隊列表。將待處理的數據放入隊列表,然後使用頻率極短的定時任務拉取隊列表的數據並處理。這種情況使用消息中間件的推送模式可更好的處理實時性數據。而且基於數據庫的消息存儲吞吐量遠遠小於基於文件的順序追加消息存儲。
新一代分布式任務調度框架:當當elastic-job開源項目的10