
文字分類(0)——scrapy爬新浪滾動新聞
阿新 • • 發佈:2018-12-21
這基本上就是一個從入門到差點放棄的故事。。程式碼在最下面
頁面的選擇
這門課需要100萬的中文語料來做文字分類,所以還要自己爬一些。
Problem 1
xPath沒有獲取到任何東西,看了下網頁的原始碼,才發現數據是由Ajax獲取的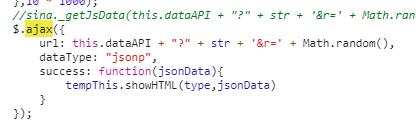 然後發現了API是
然後發現了API是
 就決定直接爬介面了。
就決定直接爬介面了。
Problem 2
可能因為他用的jQuery??(純猜測) 嘗試了一下去掉了callback這個引數,返回的就是純json了。 Page是頁碼,lid是新聞的類別,別的就不知道了沒試。
附程式碼
#encoding: utf-8
import scrapy
import re
import sys, os
#sys.setdefaultencoding("utf-8")