
NLP --- 文字分類(基於概率的隱語意分析(PLSA)詳解)
上一節我們詳細的講解了SVD的隱語意分析,一旦提到這個,大家腦海裡應該立刻有如下的矩陣形式:
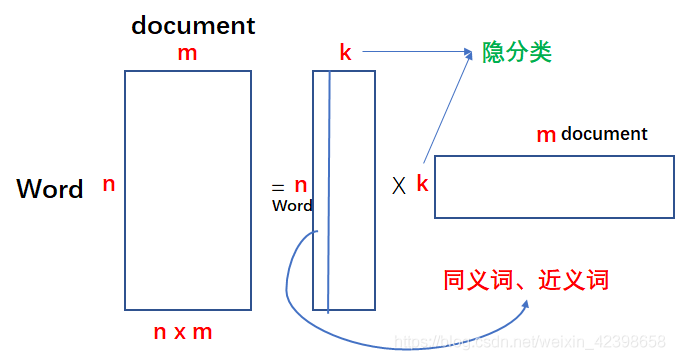
我們通過矩陣的分解對文字資料進行壓縮,壓縮量很可觀,尤其是原始的矩陣的維度很高時壓縮的更可觀,因為k通常要遠遠小於n。如上圖等號左邊的矩陣其實就是我們的文字的詞向量組成的,我們知道一篇文章的詞是很多的,而且還是稀疏的,如果一旦文章數也很多,那麼整個矩陣的元素會很大很大,但是通過矩陣分解就會減少很多。上圖中的每一列都代表一個文字的詞向量,裡面的值是詞向量的權值,那麼我們分解後的矩陣分別代表什麼呢?其中k就是隱分類或者說是隱特徵,如果多個詞在同一列出現就說明這幾個詞是相近的,在最右邊的矩陣是什麼意思呢?可以理解為經過壓縮後的文字特徵,每個文字都有k個特徵,然後對比一下,以此來判斷是否相似。還有一種用法就是我先通過矩陣分解,然後在組合成nxm的矩陣,這個新組合的矩陣和原始矩陣很像,但是肯定不一樣,因為我們中間在特徵值時略去了部分特徵值,怎麼理解這一步呢?大家可以理解為我們是去除噪聲,留下的才是主要特徵,和PCA技術差不多。但是這個方法就沒有缺點嗎?有的,下面我們來看看:
缺點是SVD的分解的計算量太大,計算複雜度高,當矩陣達到1000維以上時計算已經非常緩慢,但文字分析一般都會形成非常大型的“文件-詞”矩陣,從而難以實現,甚至儲存都很困難。因此需要引入新的求解SVD的方法,這時一種新型的求解思路就出來了,下面還以推薦系統的電影分類為例進行講解:
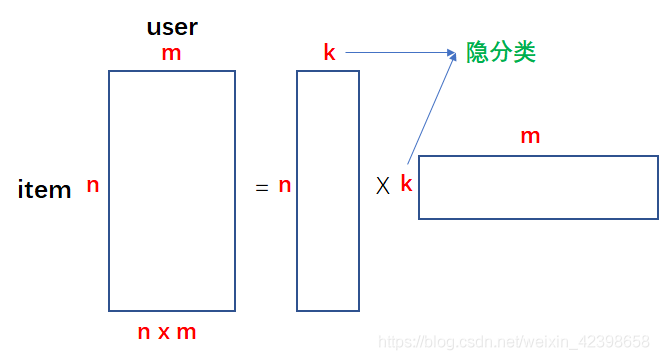
按照我們上一節的內容就是當得到評分矩陣時,就可以直接對其進行分解,但是問題是當這個評分矩陣的維度很大時,SVD的計算量將很大,為了避免這麼大的計算量,我們採用這樣的做法,就是我把上圖的等號右邊的兩個矩陣的元素全看做 變數,對,你沒看錯,全看做變數,那麼我讓他們相乘就會得到和原始評分矩陣維度一樣的矩陣,那麼這個時候我把原始矩陣已知的值和計算出來的矩陣相對應位置的值儘量相等,這樣就建立了優化函式,然後使用優化演算法使其誤差達到最低,一旦我們合成的矩陣符合我們的要求,同時就可推測原始評分稀疏矩陣的值了,通過預測的值的大小就可以推薦給使用者分值高的電影了,下面結合圖來講:
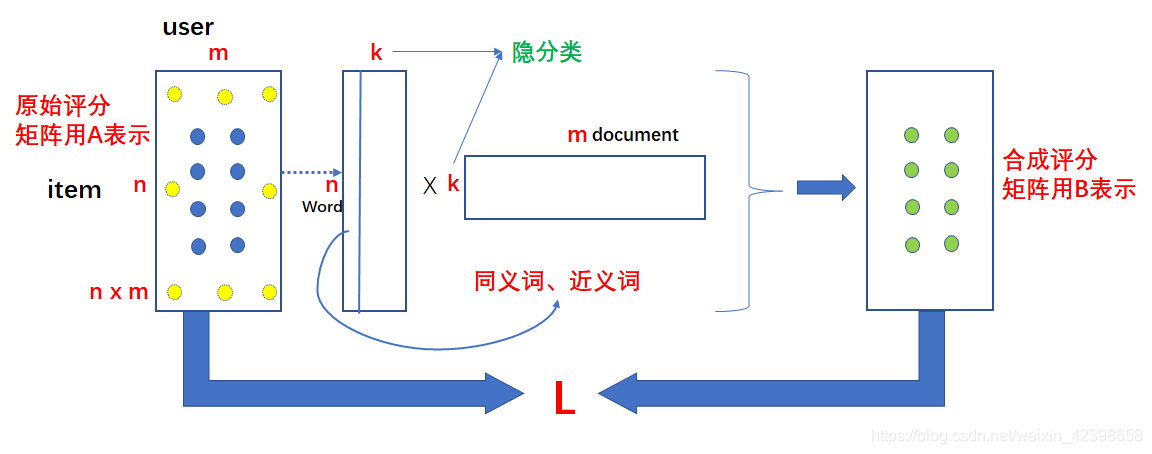
首先我們構建兩個矩陣維度為nxk和kxm的,如上圖的中間部分,那麼我把這兩個矩陣的元素都看做變數,這時候把矩陣相乘得到合成評分矩陣B,如上圖的右端,那麼把合成的資料和原始的評分矩陣A對應的位置相比較如上圖的A藍色點,黃色點是缺少的(意思是使用者沒有看過該影片),使他們儘量的接近,怎麼衡量呢?誤差平方和函式呀,因此可以得到關於很多變數的誤差函式L,此時我們使用優化演算法進行優化,一旦達到我們的要求,那麼說明我們的分解矩陣就確定了,此時使用這個 再去預測A矩陣的位置的黃色的點,這可以對評分矩陣的稀缺值進行填充,進而根據分值大小給使用者推薦電影了,就是這個原理。這樣就巧妙的避免了求解SVD了,一旦得到優化函式,我們就可以通過梯度下降得到我們的極值,下面我們就介紹一下基於PLSA對文字分類的演算法。
基於PLSA對文字分類
儘管基於 SVD 的 LSA 取得了一定的成功,但是其缺乏嚴謹的數理統計基礎,而且 SVD 分解非常耗時。Hofmann 在 SIGIR'99 上提出了基於概率統計的 PLSA 模型,並且用 EM 演算法學習模型引數。PLSA 的概率圖模型如下:
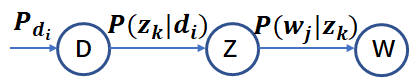
其中 D 代表文件,Z 代表隱含類別或者主題,W 為觀察到的單詞, ![]() 表示單詞出現在文件
表示單詞出現在文件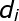
![]() 表示文件
表示文件 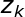
![]() 給定主題
給定主題的概率。並且每個主題在所有詞項上服從Multinomial 分佈,每個文件在所有主題上服從Multinomial 分佈。整個文件的生成過程是這樣的:
(1) 以![]() 的概率選中文件
的概率選中文件
(2) 以 ![]() 的概率選中主題
的概率選中主題
(3) 以 ![]() 的概率產生一個單詞。
的概率產生一個單詞。
我們可以觀察到的資料就是 對,而
的聯合分佈為:

而 ![]() 和
和 ![]() 分別對應了兩組 Multinomial 分佈,我們需要估計這兩組分佈的引數。
分別對應了兩組 Multinomial 分佈,我們需要估計這兩組分佈的引數。
這裡需要好好解釋一下,其中就是我們上面的推薦系統的A評分矩陣,
![]() 就是我們的上面分解第一個矩陣,而
就是我們的上面分解第一個矩陣,而就是我們分解的第二個矩陣,這裡大家把這些矩陣裡的數全看成概率理解就容易了。因此上式其實就是我們上面SVD分解的概率形式而已,這裡在把公式寫一下:
其中大家把他看成概率歸一化因子就好了。現在如何求,因為
都是未知的,怎麼求呢?這裡可以通過EM演算法進行求解,這裡需要大家理解EM演算法,不理解的請參考我的這篇文章。
用EM估計PLSA中的引數
首先我們根據最大釋然估計寫出釋然函式,如下:
![]()
其中 是單詞
出現在文件
中的次數。注意這是一個關於
![]() 和
和 的函式,一共有 N*K + M*K 個自變數,如果直接對這些自變數求偏導數,我們會發現由於自變數包含在對數和中,這個方程的求解很困難。因此對於這樣的包含“隱含變數”或者“缺失資料”的概率模型引數估計問題,我們採用 EM 演算法。
EM 演算法的步驟是:
(1)E 步驟:求隱含變數 Given 當前估計的引數條件下的後驗概率。
(2)M 步驟:最大化 Complete data 對數似然函式的期望,此時我們使用 E 步驟裡計算的隱含變數
的後驗概率,得到新的引數值。
兩步迭代進行直到收斂。
針對我們 PLSA 引數估計問題,在 E 步驟中,直接使用貝葉斯公式計算隱含變數在當前引數取值條件下的後驗概率,有
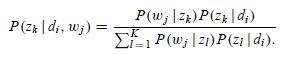
在這個步驟中,我們假定所有的 ![]() 和
和 都是已知的,因為初始時隨機賦值,後面迭代的過程中取前一輪 M 步驟中得到的引數值。
在 M 步驟中,我們最大化 Complete data 對數似然函式的期望。在 PLSA 中,Incomplete data 是觀察到的 ,隱含變數是主題
,那麼 complete data 就是三元組
,其期望是:
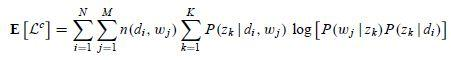
注意這裡 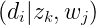
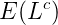
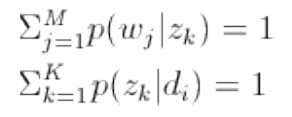
由此我們可以寫出拉格朗日函式
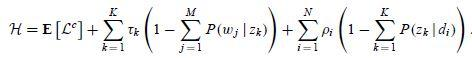
這是一個關於 ![]() 和
和 的函式,分別對其求偏導數,我們可以得到
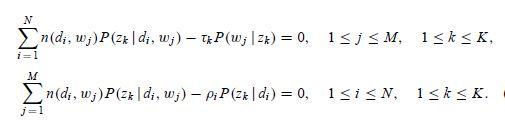
注意這裡進行過方程兩邊同時乘以![]() 和
和 的變形,聯立上面 4 組方程,我們就可以解出 M 步驟中通過最大化期望估計出的新的引數值
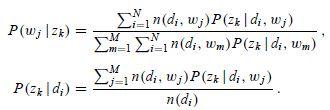
解方程組的關鍵在於先求出 ,其實只需要做一個加和運算就可以把
的係數都化成 1,後面就好計算了。然後使用更新後的引數值,我們又進入 E 步驟,計算隱含變數
Given 當前估計的引數條件下的後驗概率。如此不斷迭代,直到滿足終止條件。
本節主要參考了:
概率語言模型及其變形系列PLSA 及 及 EM 演算法 [email protected] 12/20/2012