
MapReduce shuffle的過程分析
shuffle階段其實就是多個map任務的輸出,按照不同的分割槽,通過網路copy到不同的reduce節點上。
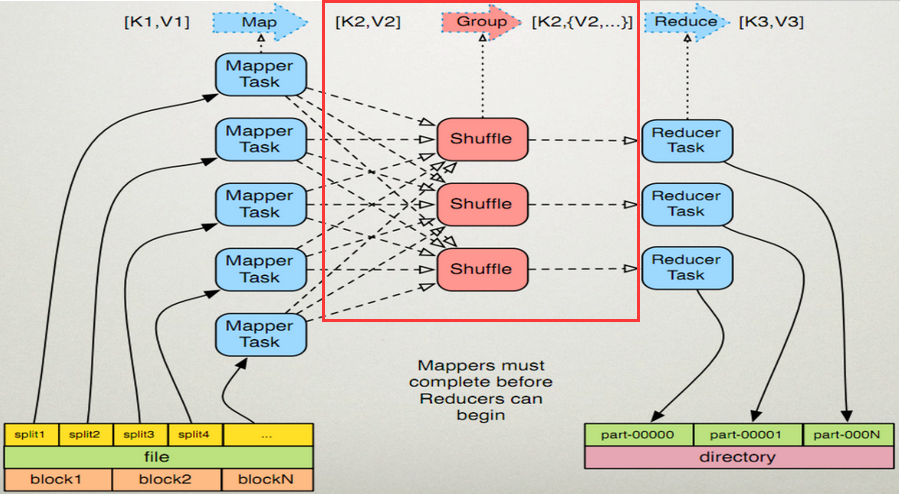

Map端:
1、在map端首先接觸的是InputSplit,在InputSplit中含有DataNode中的資料,每一個InputSplit都會分配一個Mapper任務,Mapper任務結束後產生<K2,V2>的輸出,這些輸出先存放在快取中,每個map有一個環形記憶體緩衝區,用於儲存任務的輸出。預設大小100MB(io.sort.mb屬性),一旦達到閥值0.8(io.sort.spil l.percent),一個後臺執行緒就把內容寫到(spill)Linux本地磁碟中的指定目錄(mapred.local.dir)下的新建的一個溢位寫檔案。(注意:map過程的輸出是寫入本地磁碟而不是HDFS,但是一開始資料並不是直接寫入磁碟而是緩衝在記憶體中,快取的好處就是減少磁碟I/O的開銷,提高合併和排序的速度
2、寫磁碟前,要進行partition、sort和combine等操作。通過分割槽,將不同型別的資料分開處理,之後對不同分割槽的資料進行排序,如果有Combiner,還要對排序後的資料進行combine。等最後記錄寫完,將全部溢位檔案合併為一個分割槽且排序的檔案。(注意:在寫磁碟的時候採用壓縮的方式將map的輸出結果進行壓縮是一個減少網路開銷很有效的方法!)
3、最後將磁碟中的資料送到Reduce中,從圖中可以看出Map輸出有三個分割槽,有一個分割槽資料被送到圖示的Reduce任務中,剩下的兩個分割槽被送到其他Reducer任務中。而圖示的Reducer任務的其他的三個輸入則來自其他節點的Map輸出。
Reduce端:
1、Copy階段:Reducer通過Http方式得到輸出檔案的分割槽。reduce端可能從n個map的結果中獲取資料,而這些map的執行速度不盡相同,當其中一個map執行結束時,reduce就會從JobTracker中獲取該資訊。map執行結束後TaskTracker會得到訊息,進而將訊息彙報給JobTracker,reduce定時從JobTracker獲取該資訊,reduce端預設有5個數據複製執行緒從map端複製資料。
2、Merge階段:如果形成多個磁碟檔案會進行合併從map端複製來的資料首先寫到reduce端的快取中,同樣快取佔用到達一定閾值後會將資料寫到磁碟中,同樣會進行partition、combine、排序等過程。如果形成了多個磁碟檔案還會進行合併,最後一次合併的結果作為reduce的輸入而不是寫入到磁碟中。
3、Reducer的引數:最後將合併後的結果作為輸入傳入Reduce任務中。(注意:當Reducer的輸入檔案確定後,整個Shuffle操作才最終結束。之後就是Reducer的執行了,最後Reducer會把結果存到HDFS上。)