
kubernetes-深入理解pod物件(七)
Pod中如何管理多個容器
Pod中可以同時執行多個程序(作為容器執行)協同工作。同一個Pod中的容器會自動的分配到同一個 node 上。同一個Pod中的容器共享資源、網路環境和依賴,它們總是被同時排程。
注意在一個Pod中同時執行多個容器是一種比較高階的用法。只有當你的容器需要緊密配合協作的時候才考慮用這種模式。例如,你有一個容器作為web伺服器執行,需要用到共享的volume,有另一個“sidecar”容器來從遠端獲取資源更新這些檔案,如下圖所示:
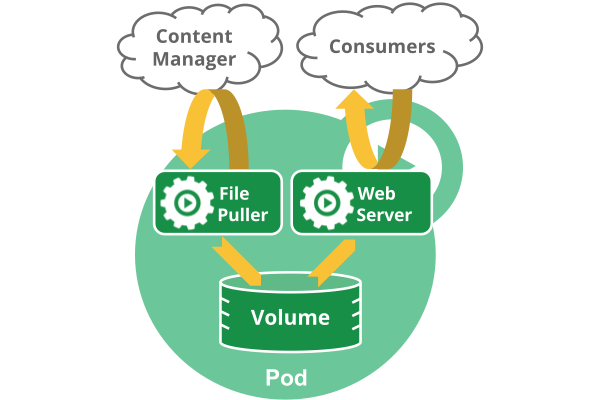
Pod中可以共享兩種資源:網路和儲存。
- 網路:每個Pod都會被分配一個唯一的IP地址。Pod中的所有容器共享網路空間,包括IP地址和埠。Pod內部的容器可以使用
localhost互相通訊。Pod中的容器與外界通訊時,必須分配共享網路資源(例如使用宿主機的埠對映)。
- 儲存:可以Pod指定多個共享的Volume。Pod中的所有容器都可以訪問共享的volume。Volume也可以用來持久化Pod中的儲存資源,以防容器重啟後文件丟失。
Pod容器分類
•Infrastructure Container:基礎容器,維護整個Pod網路空間
•InitContainers:初始化容器,先於業務容器開始執行
•Containers:業務容器,並行啟動
kubernetes中pod建立流程
Pod是Kubernetes中最基本的部署排程單元,可以包含container,邏輯上表示某種應用的一個例項。例如一個web站點應用由前端、後端及資料庫構建而成,這三個元件將執行在各自的容器中,那麼我們可以建立包含三個container的pod。
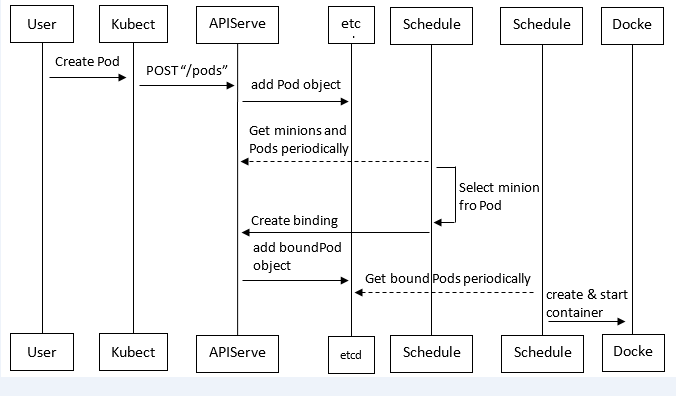
具體的建立步驟包括:
(1)客戶端提交建立請求,可以通過API Server的Restful API,也可以使用kubectl命令列工具。支援的資料型別包括JSON和YAML。 (2)API Server處理使用者請求,儲存Pod資料到etcd。 (3)排程器通過API Server檢視未繫結的Pod。嘗試為Pod分配主機。 (4)過濾主機 (排程預選):排程器用一組規則過濾掉不符合要求的主機。比如Pod指定了所需要的資源量,那麼可用資源比Pod需要的資源量少的主機會被過濾掉。 (5)主機打分(排程優選):對第一步篩選出的符合要求的主機進行打分,在主機打分階段,排程器會考慮一些整體優化策略,比如把容一個Replication Controller的副本分佈到不同的主機上,使用最低負載的主機等。 (6)選擇主機:選擇打分最高的主機,進行binding操作,結果儲存到etcd中。 (7)kubelet根據排程結果執行Pod建立操作: 繫結成功後,scheduler會呼叫APIServer的API在etcd中建立一個boundpod物件,描述在一個工作節點上繫結執行的所有pod資訊。執行在每個工作節點上的kubelet也會定期與etcd同步boundpod資訊,一旦發現應該在該工作節點上執行的boundpod物件沒有更新,則呼叫Docker API建立並啟動pod內的容器。
排程約束
https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
scheduler元件
k8s排程器會將pod排程到資源滿足要求並且評分最高的node上。
我們可以使用多種規則比如:
1.設定cpu、記憶體的使用要求
2.增加node的label,並通過pod.Spec.NodeSelector進行強匹配;
3.直接設定pod的nodeName,跳過排程直接下發。
k8s 1.2加入了一個實驗性的功能:affinity。意為親和性。這個特性的設計初衷是為了替代nodeSelector,並擴充套件更強大的排程策略。
排程器的工作機制是這樣的
一、預備工作 1、快取所有的node節點,記錄他們的規格:cpu、記憶體、磁碟空間、gpu顯示卡數等; 2、快取所有執行中的pod,按照pod所在的node進行區分,統計每個node上的pod request了多少資源。request是pod的QoS配置。 3、list & watch pod資源,當檢查到有新的Pending狀態的pod出現,就將它加入到排程佇列中。 4、排程器的worker元件從佇列中取出pod進行排程。 二、排程過程 1、先將當前所有的node放入佇列; 2、執行predicates演算法,對佇列中的node進行篩選。這裡演算法檢查了一些pod執行的必要條件,包括port不衝突、cpu和記憶體資源QoS(如果有的話)必須滿足、掛載volume(如果有的話)型別必須匹配、nodeSelector規則必須匹配、硬性的affinity規則(下文會提到)必須匹配、node的狀態(condition)必須正常,taint_toleration硬規則(下文會提到)等等。 3、執行priorities演算法,對佇列中剩餘的node進行評分,這裡有許多評分項,各個專案有各自的權重:整體cpu,記憶體資源的平衡性、node上是否有存在要求的映象、同rs的pod是否有排程、node affinity的軟規則、taint_toleration軟規則(下文會提到)等等。 4、最終評分最高的node會被選出。即程式碼中suggestedHost, err := sched.schedule(pod)一句(plugin/pkg/scheduler/scheduler.go)的返回值。 5、排程器執行assume方法,該方法在pod排程到node之前,就以“該pod執行在目標node上” 為場景更新排程器快取中的node 資訊,也即預備工作中的1、2兩點。這麼做是為了讓pod在真正排程到node上時,排程器也可以同時做後續其他pod的排程工作。 6、排程器執行bind方法,該方法建立一個Binding資源,apiserver檢查到建立該資源時,會主動更新pod的nodeName欄位。完成排程
nodeSelector用於將Pod排程到匹配Label的Node上
將標籤附加到node
[[email protected] ~]# kubectl label nodes 192.168.0.126 env_role=dev node/192.168.0.126 labeled [[email protected]-master1 ~]# kubectl label nodes 192.168.0.125 env_role=test node/192.168.0.125 labeled [[email protected]-master1 ~]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS 192.168.0.125 Ready <none> 2d4h v1.13.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=test,kubernetes.io/hostname=192.168.0.125 192.168.0.126 Ready <none> 2d4h v1.13.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=dev,kubernetes.io/hostname=192.168.0.126
將nodeSelector欄位新增到pod配置中
[[email protected] ~]# vim pod2.yaml apiVersion: v1 kind: Pod metadata: name: nginx
labels:
app: nginx spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent nodeSelector: env_role: dev [[email protected]-master1 ~]# kubectl create -f pod2.yaml pod/nginx created
檢視pod


[[email protected] ~]# kubectl get pod NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 115s [[email protected]-master1 ~]# kubectl describe pod nginx Name: nginx Namespace: default Priority: 0 PriorityClassName: <none> Node: 192.168.0.126/192.168.0.126 Start Time: Fri, 21 Dec 2018 14:07:49 +0800 Labels: <none> Annotations: <none> Status: Running IP: 172.17.92.2 Containers: nginx: Container ID: docker://8c7e442cc83b6532b3bda707f389fa371861d173e9395149bbede9e166bf559c Image: nginx Image ID: docker-pullable://[email protected]:1a0043cfb1987774c6981c41e49f758c58ace64c30e1c4ecff5cedff0b5c88da Port: <none> Host Port: <none> State: Running Started: Fri, 21 Dec 2018 14:07:50 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-7vs6s (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-7vs6s: Type: Secret (a volume populated by a Secret) SecretName: default-token-7vs6s Optional: false QoS Class: BestEffort Node-Selectors: env_role=dev Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m11s default-scheduler Successfully assigned default/nginx to 192.168.0.126 Normal Pulled 2m11s kubelet, 192.168.0.126 Container image "nginx" already present on machine Normal Created 2m10s kubelet, 192.168.0.126 Created container Normal Started 2m10s kubelet, 192.168.0.126 Started containerView Code
nodeName用於將Pod排程到指定的Node名稱上
spec.nodeName用於強制約束將Pod排程到指定的Node節點上,這裡說是“排程”,但其實指定了nodeName的Pod會直接跳過Scheduler的排程邏輯,直接寫入PodList列表,該匹配規則是強制匹配。
[[email protected] ~]# vim pod3.yaml apiVersion: v1 kind: Pod metadata: name: pod-example labels: app: nginx spec: nodeName: 192.168.0.125 containers: - name: nginx image: nginx:1.15 [[email protected]-master1 ~]# kubectl create -f pod3.yaml pod/pod-example created
檢視pod
[[email protected] ~]# kubectl get pod NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 10m pod-example 1/1 Running 0 22s [[email protected]-master1 ~]# kubectl describe pod pod-example Name: pod-example Namespace: default Priority: 0 PriorityClassName: <none> Node: 192.168.0.125/192.168.0.125 Start Time: Fri, 21 Dec 2018 14:17:47 +0800 Labels: app=nginx Annotations: <none> Status: Running IP: 172.17.19.2 Containers: nginx: Container ID: docker://5e33eacb41e9b4ffd072141af63209229543105feb804d23b72a09be9e414409 Image: nginx:1.15 Image ID: docker-pullable://[email protected]:5d32f60db294b5deb55d078cd4feb410ad88e6fe77500c87d3970eca97f54dba Port: <none> Host Port: <none> State: Running Started: Fri, 21 Dec 2018 14:17:48 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-7vs6s (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-7vs6s: Type: Secret (a volume populated by a Secret) SecretName: default-token-7vs6s Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulled 31s kubelet, 192.168.0.125 Container image "nginx:1.15" already present on machine Normal Created 31s kubelet, 192.168.0.125 Created container Normal Started 30s kubelet, 192.168.0.125 Started containerView Code
從私有映象倉庫拉取映象
參考:https://kubernetes.io/docs/concepts/containers/images/
檢視docker登陸私有倉庫的憑據
[[email protected] ~]# cat .docker/config.json |base64 -w 0
ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjAuMTIyIjogewoJCQkiYXV0aCI6ICJiM0J6T2xCQWMzTjNNSEprIgoJCX0KCX0sCgkiSHR0cEhlYWRlcnMiOiB7CgkJIlVzZXItQWdlbnQiOiAiRG9ja2VyLUNsaWVudC8xOC4wOS4wIChsaW51eCkiCgl9Cn0=
建立Secret
[[email protected] tomcat]# vim registry-pull-secret.yaml apiVersion: v1 kind: Secret metadata: name: registry-pull-secret data: .dockerconfigjson: ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjAuMTIyIjogewoJCQkiYXV0aCI6ICJiM0J6T2xCQWMzTjNNSEprIgoJCX0KCX0sCgkiSHR0cEhlYWRlcnMiOiB7CgkJIlVzZXItQWdlbnQiOiAiRG9ja2VyLUNsaWVudC8xOC4wOS4wIChsaW51eCkiCgl9Cn0= type: kubernetes.io/dockerconfigjson [[email protected]-master1 tomcat]# kubectl create -f registry-pull-secret.yaml secret/registry-pull-secret created [[email protected]-master1 tomcat]# kubectl get secret NAME TYPE DATA AGE default-token-7vs6s kubernetes.io/service-account-token 3 44h registry-pull-secret kubernetes.io/dockerconfigjson 1 23s
建立pod時,設定從私有倉庫拉取映象
[[email protected]master1 tomcat]# vim tomcat.yaml apiVersion: apps/v1beta2 kind: Deployment metadata: name: tomcat-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: tomcat template: metadata: labels: app: tomcat spec: imagePullSecrets: - name: registry-pull-secret #secret 登陸倉庫的憑據 containers: - name: tomcat image: 192.168.0.122/ceba/tomcat #映象地址 imagePullPolicy: Always #設定每次建立pod都重新拉取映象 ports: - containerPort: 8080 --- apiVersion: v1 kind: Service metadata: name: tomcat-service labels: app: tomcat spec: type: NodePort ports: - port: 80 targetPort: 8080 selector: app: tomcatView Code
映象拉取策略
•IfNotPresent:預設值,映象在宿主機上不存在時才拉取
•Always:每次建立Pod 都會重新拉取一次映象
•Never:Pod 永遠不會主動拉取這個映象
檢視拉取的映象正常啟動
[[email protected]master1 tomcat]# kubectl get pod,svc,deploy NAME READY STATUS RESTARTS AGE pod/tomcat-deployment-6bb6864d4f-4xj82 1/1 Running 0 65s pod/tomcat-deployment-6bb6864d4f-drcjc 1/1 Running 0 47s pod/tomcat-deployment-6bb6864d4f-wmkxx 1/1 Running 0 45s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 44h service/tomcat-service NodePort 10.0.0.3 <none> 80:49014/TCP 8m20s NAME READY UP-TO-DATE AVAILABLE AGE deployment.extensions/tomcat-deployment 3/3 3 3 8m20s
資源限制
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
建立Pod的時候,可以指定計算資源(目前支援的資源型別有CPU和記憶體),即指定每個容器的資源請求(Request)和資源限制(Limit),資源請求是容器所需的最小資源需求,資源限制則是容器不能超過的資源上限。它們的大小關係是:0<=request<=limit<=infinity
Pod的資源請求就是Pod中容器資源請求之和。Kubernetes在排程Pod時,會根據Node中的資源總量(通過cAdvisor介面獲得),以及該Node上已使用的計算資源,來判斷該Node是否滿足需求。
資源請求能夠保證Pod有足夠的資源來執行,而資源限制則是防止某個Pod無限制地使用資源,導致其他Pod崩潰。特別是在公有云場景,往往會有惡意軟體通過搶佔記憶體來攻擊平臺。
原理:Docker 通過使用Linux Cgroup來實現對容器資源的控制,具體到啟動引數上是--memory和--cpu-shares。Kubernetes中是通過控制這兩個引數來實現對容器資源的控制。
Pod和Container的資源請求和限制:
•spec.containers[].resources.limits.cpu
•spec.containers[].resources.limits.memory
•spec.containers[].resources.requests.cpu
•spec.containers[].resources.requests.memory
示例
以下Pod有兩個容器。每個Container都有0.25 cpu和64MiB記憶體的請求。每個Container的記憶體限制為0.5 cpu和128MiB。你可以說Pod有0.5 cpu和128 MiB記憶體的請求,並且限制為1 cpu和256MiB的記憶體。
[[email protected] ~]# vim pod1.yaml apiVersion: v1 kind: Pod metadata: name: frontend spec: containers: - name: db image: mysql env: - name: MYSQL_ROOT_PASSWORD value: "password" resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" - name: wp image: wordpress resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
檢視node節點資源使用情況
[[email protected] ~]# kubectl describe pod frontend | grep -A 3 Events Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 19m default-scheduler Successfully assigned default/frontend to 192.168.0.125 [[email protected]-master1 ~]# kubectl describe nodes 192.168.0.125 Name: 192.168.0.125 Roles: <none> Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/hostname=192.168.0.125 Annotations: node.alpha.kubernetes.io/ttl: 0 volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Wed, 19 Dec 2018 09:54:14 +0800 Taints: <none> Unschedulable: false Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Thu, 20 Dec 2018 17:26:03 +0800 Thu, 20 Dec 2018 10:29:48 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Thu, 20 Dec 2018 17:26:03 +0800 Thu, 20 Dec 2018 10:29:48 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Thu, 20 Dec 2018 17:26:03 +0800 Thu, 20 Dec 2018 10:29:48 +0800 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Thu, 20 Dec 2018 17:26:03 +0800 Thu, 20 Dec 2018 10:29:48 +0800 KubeletReady kubelet is posting ready status OutOfDisk Unknown Wed, 19 Dec 2018 09:54:14 +0800 Wed, 19 Dec 2018 13:23:20 +0800 NodeStatusNeverUpdated Kubelet never posted node status. Addresses: InternalIP: 192.168.0.125 Hostname: 192.168.0.125 Capacity: cpu: 2 ephemeral-storage: 80699908Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3861520Ki pods: 110 Allocatable: cpu: 2 ephemeral-storage: 74373035090 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3759120Ki pods: 110 System Info: Machine ID: def36d2abcbe49839534858f6f1e13c5 System UUID: 86B24D56-709A-3467-6DDB-966B3B807949 Boot ID: 949f73c9-b14b-4e94-9137-78b2ac83d046 Kernel Version: 3.10.0-957.1.3.el7.x86_64 OS Image: CentOS Linux 7 (Core) Operating System: linux Architecture: amd64 Container Runtime Version: docker://18.9.0 Kubelet Version: v1.13.0 Kube-Proxy Version: v1.13.0 Non-terminated Pods: (3 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE --------- ---- ------------ ---------- --------------- ------------- --- default frontend 500m (25%) 1 (50%) 128Mi (3%) 256Mi (6%) 20m default tomcat-deployment-6bb6864d4f-drcjc 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3h25m default tomcat-deployment-6bb6864d4f-wmkxx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3h25m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 500m (25%) 1 (50%) memory 128Mi (3%) 256Mi (6%) ephemeral-storage 0 (0%) 0 (0%) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Starting 9m29s kube-proxy, 192.168.0.125 Starting kube-proxy. Normal Starting 8m42s kubelet, 192.168.0.125 Starting kubelet. Normal NodeHasSufficientMemory 8m42s kubelet, 192.168.0.125 Node 192.168.0.125 status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 8m42s kubelet, 192.168.0.125 Node 192.168.0.125 status is now: NodeHasNoDiskPressure Normal NodeHasSufficientPID 8m42s kubelet, 192.168.0.125 Node 192.168.0.125 status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 8m42s kubelet, 192.168.0.125 Updated Node Allocatable limit across pods Warning Rebooted 8m42s kubelet, 192.168.0.125 Node 192.168.0.125 has been rebooted, boot id: 949f73c9-b14b-4e94-9137-78b2ac83d046View Code
健康檢查(Probe)
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
在實際生產環境中,想要使得開發的應用程式完全沒有bug,在任何時候都執行正常,幾乎 是不可能的任務。因此,我們需要一套管理系統,來對使用者的應用程式執行週期性的健康檢查和修復操作。這套管理系統必須執行在應用程式之外,這一點非常重要一一如果它是應用程式的一部分,極有可能會和應用程式一起崩潰。因此,在Kubernetes中,系統和應用程式的健康檢查是由Kubelet來完成的。
1、程序級健康檢查
最簡單的健康檢查是程序級的健康檢查,即檢驗容器程序是否存活。這類健康檢查的監控粒 度是在Kubernetes叢集中執行的單一容器。Kubelet會定期通過Docker Daemon獲取所有Docker程序的執行情況,如果發現某個Docker容器未正常執行,則重新啟動該容器程序。目前,程序級的健康檢查都是預設啟用的。
2.業務級健康檢查
在很多實際場景下,僅僅使用程序級健康檢查還遠遠不夠。有時,從Docker的角度來看,容器程序依舊在執行;但是如果從應用程式的角度來看,程式碼處於死鎖狀態,即容器永遠都無法正常響應使用者的業務為了解決以上問題,Kubernetes引人了一個在容器內執行的活性探針的概念,以支援使用者自己實現應用業務級的健康檢查。
Probe有以下兩種型別:
livenessProbe:如果檢查失敗,將殺死容器,根據Pod的restartPolicy來操作。
readinessProbe:如果檢查失敗,Kubernetes會把Pod從service endpoints中剔除。
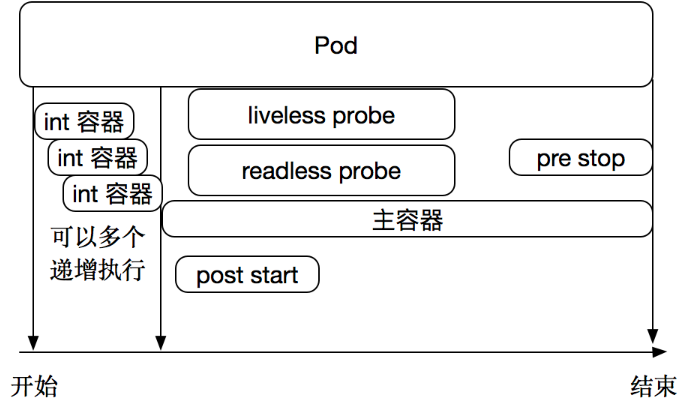
Probe支援以下三種檢查方法:
- ExecAction:在容器內執行指定命令。如果命令退出時返回碼為 0 則認為診斷成功。
- TCPSocketAction:對指定埠上的容器的 IP 地址進行 TCP 檢查。如果埠開啟,則診斷被認為是成功的。
- HTTPGetAction:對指定的埠和路徑上的容器的 IP 地址執行 HTTP Get 請求。如果響應的狀態碼大於等於200 且小於 400,則診斷被認為是成功的。
livenessProbe解析
[[email protected] ~]# kubectl explain pod.spec.containers.livenessProbe KIND: Pod VERSION: v1 RESOURCE: livenessProbe <Object> exec command 的方式探測 例如 ps 一個程序 failureThreshold 探測幾次失敗 才算失敗 預設是連續三次 periodSeconds 每次的多長時間探測一次 預設10s timeoutSeconds 探測超市的秒數 預設1s initialDelaySeconds 初始化延遲探測,第一次探測的時候,因為主程式未必啟動完成 tcpSocket 檢測埠的探測 httpGet http請求探測
exec探針的示例:
[[email protected] ~]# vim exec-liveness.yaml apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 5 [[email protected]-master1 ~]# kubectl create -f exec-liveness.yaml pod/liveness-exec created [[email protected]-master1 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE frontend 2/2 Running 106 16h liveness-exec 1/1 Running 0 16s
在配置檔案中,您可以看到Pod具有單個Container。該periodSeconds欄位指定kubelet應每5秒執行一次活躍度探測。該initialDelaySeconds欄位告訴kubelet它應該在執行第一次探測之前等待5秒。要執行探測,kubelet將cat /tmp/healthy在Container中執行命令。如果命令成功,則返回0,並且kubelet認為Container是活動且健康的。如果該命令返回非零值,則kubelet會終止Container並重新啟動它。
再等30秒,確認Container已重新啟動,RESTARTS已增加
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 57s default-scheduler Successfully assigned default/liveness-exec to 192.168.0.126 Normal Pulling 55s kubelet, 192.168.0.126 pulling image "busybox" Normal Pulled 47s kubelet, 192.168.0.126 Successfully pulled image "busybox" Normal Created 47s kubelet, 192.168.0.126 Created container Normal Started 47s kubelet, 192.168.0.126 Started container Warning Unhealthy 5s (x3 over 15s) kubelet, 192.168.0.126 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory [[email protected] ~]# kubectl get pod NAME READY STATUS RESTARTS AGE frontend 2/2 Running 106 16h liveness-exec 1/1 Running 1 107s
pod生命週期
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
Pod 的 status 在資訊儲存在 PodStatus 中定義,其中有一個 phase 欄位。
Pod 的相位(phase)是 Pod 在其生命週期中的簡單巨集觀概述。該階段並不是對容器或 Pod 的綜合彙總,也不是為了做為綜合狀態機。
Pod 相位的數量和含義是嚴格指定的。除了本文件中列舉的狀態外,不應該再假定 Pod 有其他的 phase值。
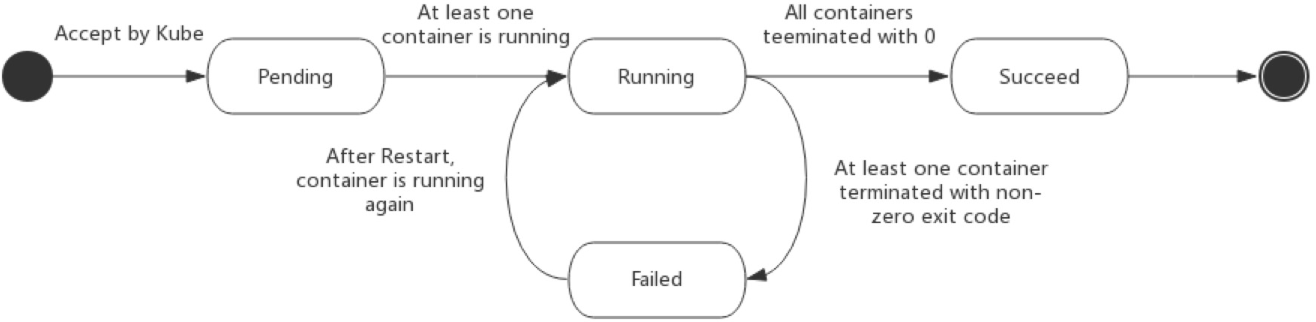
下面是 phase 可能的值:
- 掛起(Pending):Pod 已被 Kubernetes 系統接受,但有一個或者多個容器映象尚未建立。等待時間包括排程 Pod 的時間和通過網路下載映象的時間,這可能需要花點時間。
- 執行中(Running):該 Pod 已經繫結到了一個節點上,Pod 中所有的容器都已被建立。至少有一個容器正在執行,或者正處於啟動或重啟狀態。
- 成功(Succeeded):Pod 中的所有容器都被成功終止,並且不會再重啟。
- 失敗(Failed):Pod 中的所有容器都已終止了,並且至少有一個容器是因為失敗終止。也就是說,容器以非0狀態退出或者被系統終止。
- 未知(Unknown):因為某些原因無法取得 Pod 的狀態,通常是因為與 Pod 所在主機通訊失敗。
下圖是Pod的生命週期示意圖,從圖中可以看到Pod狀態的變化。
故障排查
kubectl describe TYPE/NAME kubectl logs TYPE/NAME [-c CONTAINER] kubectl exec POD [-c CONTAINER] --COMMAND [args...]