
分散式排程框架大集合
分散式任務排程框架
1、什麼是分散式任務排程?
2、常見的分散式任務排程框架有哪些?
3、分散式任務排程框架的技術選型?
4、分散式任務排程框架的安裝與使用?
大對比表格:https://pan.baidu.com/s/1CZAjTFqIhinzlVLnrrMUKQ
分散式任務排程,三個關鍵詞:分散式、任務排程、配置中心。
分散式:平臺是分散式部署的,各個節點之間可以無狀態和無限的水平擴充套件;
任務排程:涉及到任務狀態管理、任務排程請求的傳送與接收、具體任務的分配、任務的具體執行;(這裡又會遇到一共要處理哪些任務、任務要分配到哪些機器上處理、任務分發的時候判斷哪些機器可以用等問題,所以又需要一個可以感知整個叢集執行狀態的配置中心)
配置中心:可以感知整個叢集的狀態、任務資訊的註冊
一個分散式任務排程系統需要以下內容:
web模組、server模組、Scheduler模組、worker模組、註冊中心。
1、Web模組:用來提供任務的資訊,控制任務的狀態、資訊展示等。
2、Server模組:負責接收web端傳來的任務執行的資訊,下發任務排程請求給Scheduler,會去註冊中心進行註冊
3、Scheduler模組:接收server端傳來的排程請求,將任務進行更加細化的拆分然後下發,到註冊中心進行註冊,獲取到可以幹活的worker。
4、Worker模組:負責具體的任務執行。
5、註冊中心。
1、什麼是分散式任務排程?
任務排程是指基於給定的時間點,給定的時間間隔或者給定執行次數自動的執行任務。任務排程是是作業系統的重要組成部分,而對於實時的作業系統,任務排程直接影響著作業系統的實時效能。任務排程涉及到多執行緒併發、執行時間規則定製及解析、執行緒池的維護等諸多方面的工作。
WEB伺服器在接受請求時,會建立一個新的執行緒服務。但是資源有限,必須對資源進行控制,首先就是限制服務執行緒的最大數目,其次考慮以執行緒池共享服務的執行緒資源,降低頻繁建立、銷燬執行緒的消耗;然後任務排程資訊的儲存包括執行次數、排程規則以及執行資料等。一個合適的任務排程框架對於專案的整體效能來說顯得尤為重要。
2、常見的任務排程框架有哪些?
我們在實際的開發工作中,或多或少的都會用到任務排程這個功能。常見的分散式任務排程框架有:cronsun、Elastic-job、saturn、lts、TBSchedule、xxl-job等。
2.1cronsun
crontab是Linux系統裡面最簡單易用的定時任務管理工具,在Linux上由crond來週期性的執行指令列表,執行的任務稱為cron job,多個任務就稱為crontab。crontab任務排程指令的基本格式為:
* * * * * command
分 時 日 月 周 命令
但是時間久了之後會發現,crontab會存在一些問題:
- 大量的crontab分散在各臺伺服器,帶來了很高的維護成本;
- 任務沒有按時執行,過了很長的時間才能發現,需要重試或者排查;
- crontab分散在很多叢集上,需要一臺一臺的去檢視日誌;
- crontab存在單點問題,對於不能重複執行的定時任務很傷腦;
- ……
因此非常需要一個集中管理定時任務的系統,於是就有了cronsun。cronsun是一個分散式任務系統,單個節點和Linux機器上的contab近似,是為了解決多臺Linux機器上crontab任務管理不方便的問題,同時提供了任務高可用的支援(當某個節點宕機的時候可以自動調整到正常的節點執行)。與此同時,它還支援介面管理機器上的任務,支援任務失敗郵件提醒,安裝簡單,使用簡便,是替換crontab的一個不錯的選擇。
cronsun中主要有三個元件,都是通過etcd通訊的。cronnode負責節點的分組及節點的狀態,cronweb是用來管理任務的、任務的執行結果都可以在上面看。

cronsun的系統架構如下圖所示,簡單的來說就是,所有的任務都會儲存在一個分散式etcd裡,單個crond部署成一個服務,也就是圖中所示的node.1、node.2、node.n等,然後再由web介面去管理。如果任務執行失敗的話,會發送失敗的郵件,當單個節點宕機的時候,也會自動調整到正常的節點去執行任務。
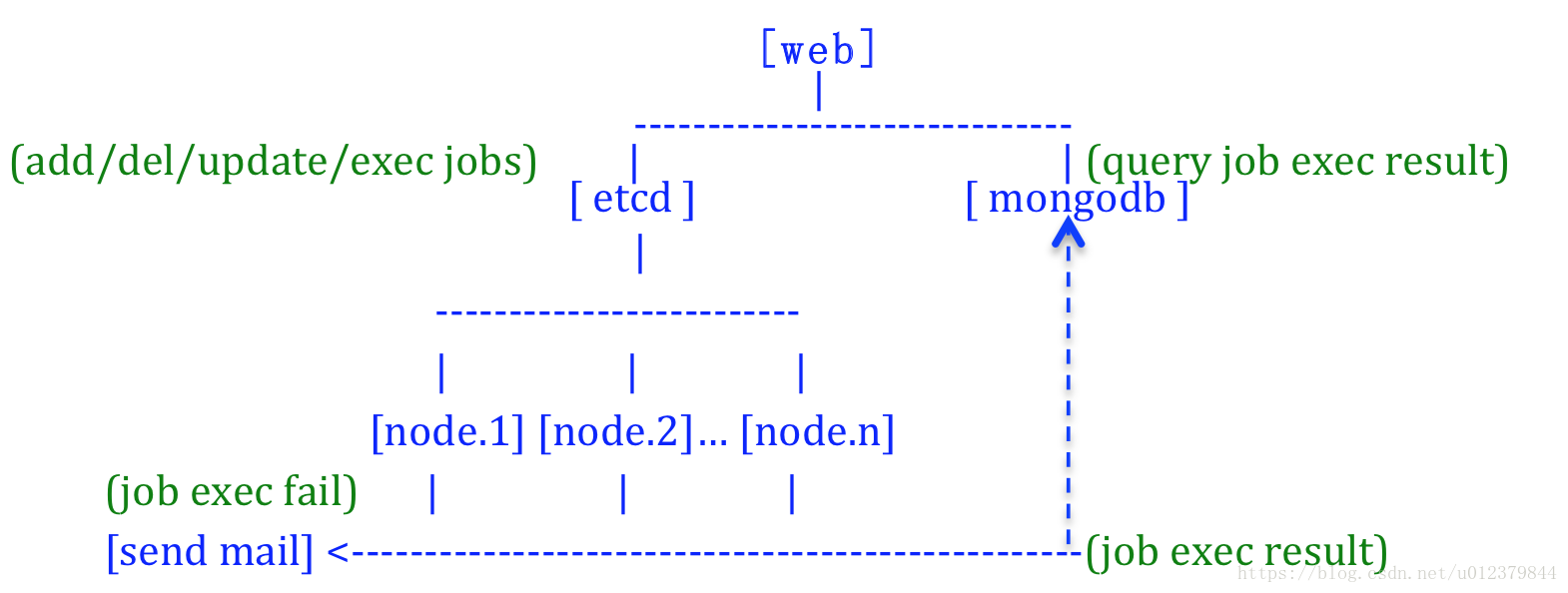
cronsun是在管理後臺新增任務的,所以一旦管理後臺洩漏出去了,則存在一定的危險性,所以cronsun支援security.json的安全設定:
{
"open": true,
"#users": "允許選擇執行指令碼的使用者", "users": [
"www", "db" ],
"#ext": "允許新增以下副檔名結束的指令碼", "ext": [
".cron.sh", ".cron.py" ]
}如以上設定開啟安全限制,則新增和執行任務的時候只允許選擇配置裡面指定的使用者來執行指令碼,並且指令碼的副檔名要在配置的指令碼的副檔名限制的列表裡面。
2.2、Elastic-job
Elastic-job是噹噹開源的一款非常好用的作業框架,Elastic-job在2.x之後,出現了兩個相互獨立的產品線:Elastic-job-lite和Elastic-job-cloud。
2.2.1、Elastic-job-lite
Elastic-job-lite定位為輕量級無中心化的解決方案,使用jar包的形式提供分散式任務的協調服務,外部依賴僅依賴於zookeeper。

Elastic-job-lite的架構圖如下圖所示:
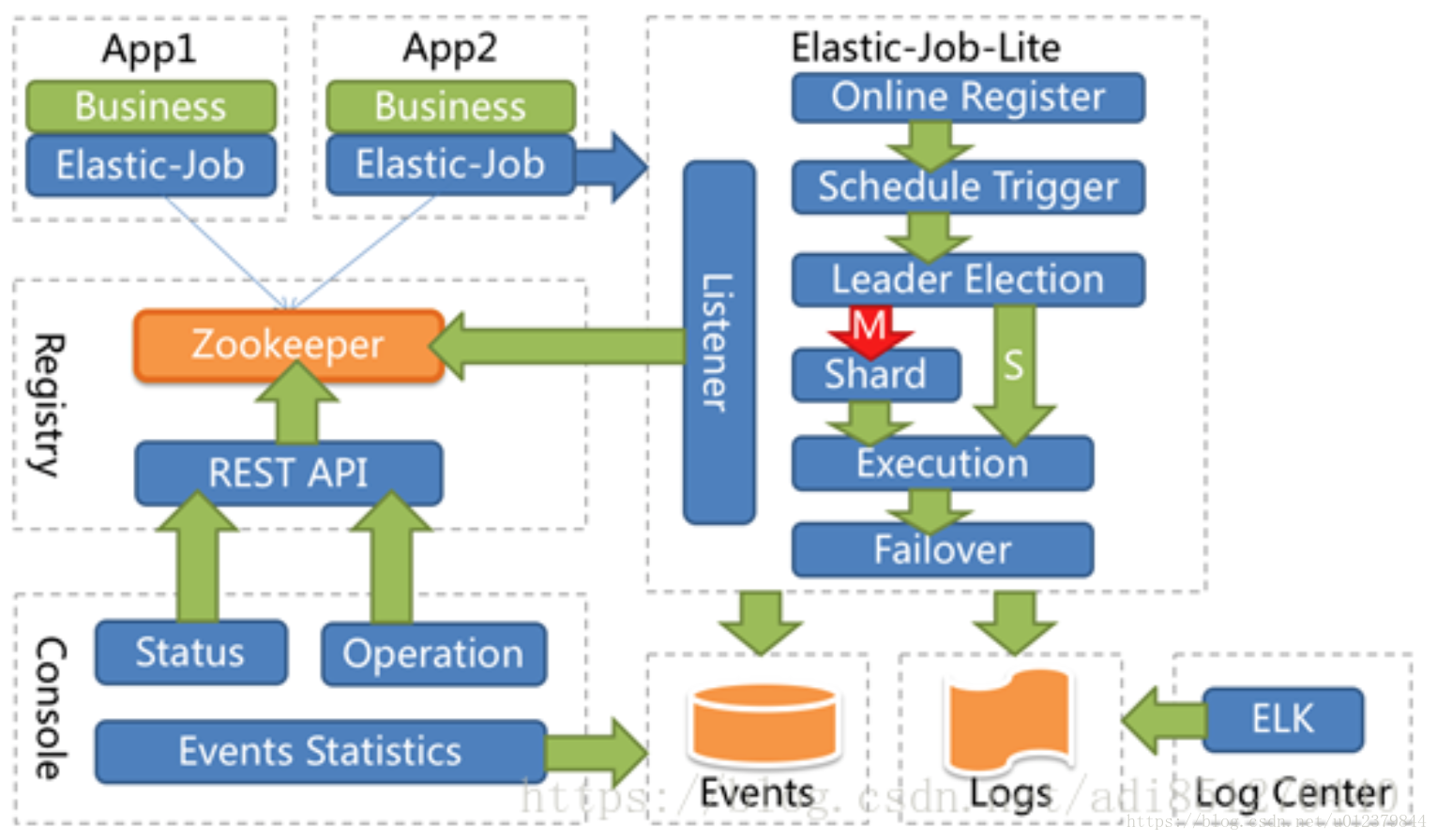
從上面的框架圖中可以看出,Elastic-job-lite框架使用zookeeper作為註冊中心,Elastic-job-lite框架通過監聽感知zookeeper資料的變化,並做相應的處理;運維平臺也僅是通過讀取zk資料來展現作業狀態,或是更新zk資料修改全域性配置。運維平臺和Elastic-job-lite沒有直接的關係,完全解耦合。Elastic-job-lite並不直接提供資料處理的功能,框架只會將分片項分配給各個正在執行中的伺服器,分片項與真是資料的對應關係需要開發者在應用程式中自行處理。
Elastic-job-lite並無作業排程中心節點,而是基於部署作業框架的程式在到達相應時間點時各自觸發排程。註冊中心僅用於作業註冊和監控資訊儲存,而主作業節點僅用於處理分片和清理的功能。
(1)註冊中心的資料結構
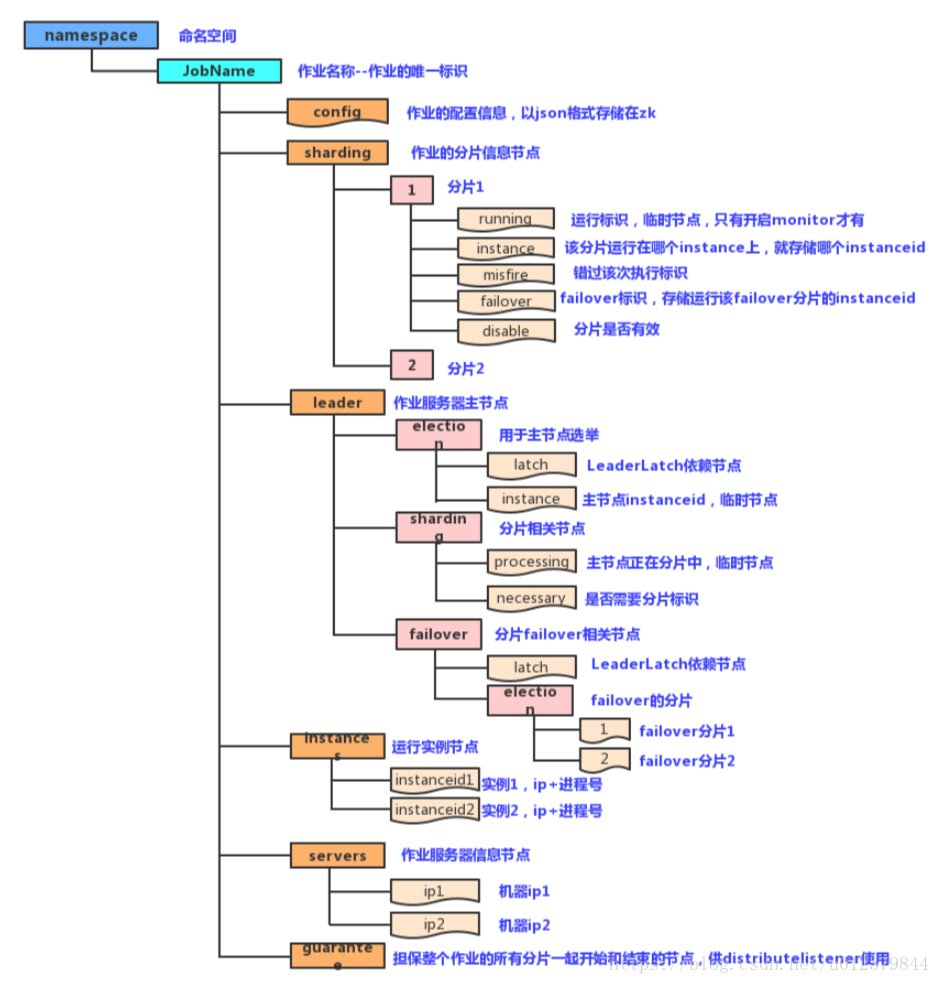
我們先來了解一下該框架在zookeeper上的節點情況。首先註冊中心在命名的空間下建立作業名稱節點(作業名稱用來區分不同的作業,一旦修改名稱,則認為是新的作業),作業名稱節點下又包含5個子節點:
config:儲存作業的配置資訊,以JSON格式儲存
sharding:儲存作業的分片資訊,它的子節點是分片項序號,從零開始,至分片總數減一
leader:該節點儲存作業伺服器主節點的資訊,分為election、sharding和failover三個子節點,分別用於主節點的選舉、分片和失效轉移
instances:該節點儲存的是作業執行例項的資訊,子節點是當前作業執行例項的主鍵
servers:該節點儲存作業伺服器的資訊,子節點是作業伺服器的IP地址
(2)實現原理
- 第一臺伺服器上線觸發主伺服器選舉,主伺服器一旦下線,則重新觸發選舉,選舉過程中阻塞,只有當主伺服器選舉完成,才會去執行其他的任務;
- 某伺服器上線時會自動將伺服器的資訊註冊到註冊中心,下線時會自動更新伺服器的狀態;
- 主節點選舉,伺服器上下線,分片總數變更均更新重新分片標記;
- 定時任務觸發時,如需重新分片,則通過主伺服器分片,分片過程中阻塞,分片結束後才可以執行任務。如分片過程中主伺服器下線,則先選舉主伺服器在分片;
- 由上一項說明可知,為了維持作業執行時的穩定性,執行過程中只會標記分片的狀態,不會重新分片,分片僅可能發生在下次任務觸發前;
- 每次分片都會按照ip排序,保證分片結果不會產生較大的波動;
- 實現失效轉移功能,在某臺伺服器執行完畢後主動抓取未分配的分片,並且在某臺伺服器下線後主動尋找可用的伺服器執行任務。
elastic底層的任務排程還是使用的quartz,通過zookeeper來動態給job節點分片。如果很大體量的使用者需要我們在特定的時間段內計算完成,那麼我們肯定是希望我們的任務可以通過叢集達到水平的擴充套件,叢集裡的每個節點都處理部分的使用者,不管使用者的數量有多大,我們只需要增加機器就可以了。舉個例子:比如我們希望3臺機器跑job,我麼將我們的任務分成3片,框架通過zk的協調,最終會讓3臺機器分配到0,1,2的任務片,比如server0->0、server1->1、server2->2,當server0執行時,可以只查詢id%3==0的使用者,server1可以只查詢id%3==1的使用者,server2可以只查詢id%3==2的使用者。
在以上的基礎上再增加一個server3,此時,server3分不到任何的分片,沒有分到任務分片的程式將不執行。如果此時server2掛了,那麼server2被分到的任務分片將會分配給server3,所以server3就會代替server2執行。如果此時server3也掛了,那麼框架也會自動的將server3的任務分片隨機分配到server0或者server1,那麼就可能成:server0->0、server1->1,2。
這種特性稱之為彈性擴容。
2.2.2、Elastic-job-cloud
Elastic-job-cloud包含了Elastic-job-lite的全部功能,它是以私有云平臺的方式提供集資源、排程以及分片為一體的全量級解決方案,依賴於Mesos和Zookeeper,它額外提供了資源治理、應用分發以及程序隔離等服務。他們兩個提供同一套API開發作業,開發者僅需一次開發,然後可根據需要以lite或cloud的方式部署。
2.3、saturn
Saturn(定時任務排程系統)是唯品會自主研發的分散式的定時任務的排程平臺,它是基於Elastic-job版本1開發的。目標是取代傳統的Linux Cron/Spring Batch Job/Quartz的方式,做到全域統一配置、統一監控、任務高可用以及分片。Saturn的任務可以使用多種語言開發,比如python、Go、Shell、Java、Php等。
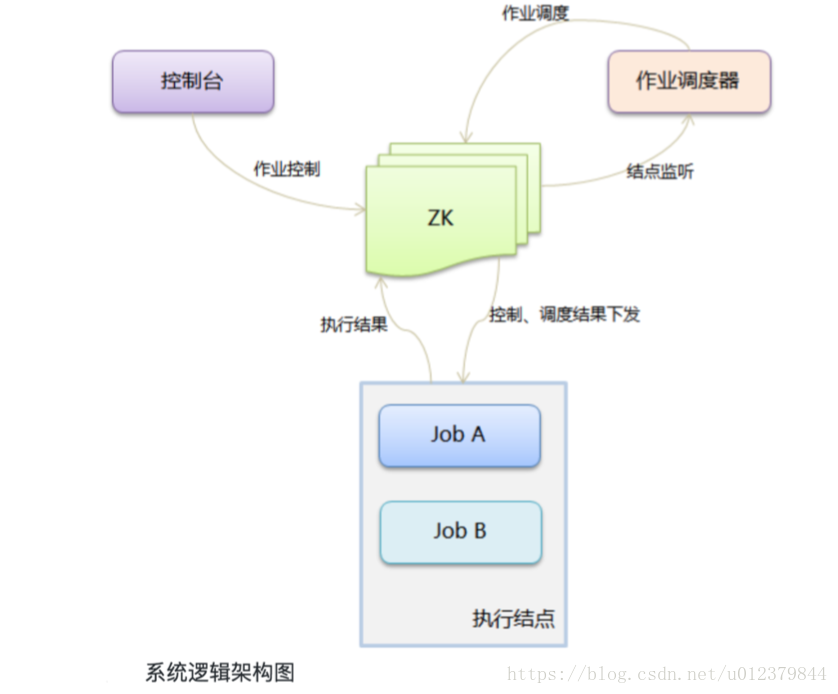
Saturn包括兩大部分,Saturn Console和Saturn Executor。Console是一個WEB UI,用來對作業/Executor的管理,統計報表展現等。他同時也是整個排程系統的大腦:將作業任務分配到各Executor。Executor是執行任務的worker:按照作業配置的要求去執行部署於Executor所在容器或物理機當中的作業指令碼和程式碼。Saturn高度依賴於zookeeper,每個executor及排程服務都會在zookeeper上進行註冊,確保排程程式能夠及時得到executor的狀態。
Saturn定時任務排程的最小單位是分片,即任務的一個執行單元。Saturn的基本任務就是將任務分成多個分片,並將每個分片通過演算法排程到對應的executor上去執行。
2.3.1、Staurn基本原理
Saturn的基本原理是將作業在邏輯上劃分為若干個分片,通過作業分片排程器將作業分片指派給特定的執行節點。執行節點通過quartz觸發執行作業的具體實現,在執行的時候,會將分片序號和引數作為引數傳入。作業的實現邏輯需分析分片序號和分片引數,並以此為依據來呼叫具體的實現(比如一個批量處理資料庫的作業,可以劃分0號分片處理1-10號資料庫,1號分片可以處理11-20號資料庫)。

2.3.2、Saturn作業排程演算法
(1)方案的設計
原理是給每個作業分片一個負載值和優先執行節點(prefer list),當需要重新分片時,參考作業優先設定和執行節點的負載值來進行域內節點之間的資源分配,從而達到資源平衡。
(2)前置條件
A:每個分片都引入一個負載值(load),由使用者通過Saturn UI介面輸入
B:為每一個作業引入新的屬性prefer list(優先列表,或者叫欲分配列表),由管理員通過ui介面編輯
C:作業引入啟用狀態(enabled/disabled),使用者通過UI介面改變這個狀態;啟用狀態的作業會被節點執行,且不可編輯、刪除,不可對prefer list進行調整,禁用狀態的作業不會被執行
(3)實施步驟
第一步,摘取;第二步,放回(將這些作業分片按照負載值從大到小順序逐個分配給負載最小的執行節點)。
(3.1)executor上線
摘取:
第一步,找出新上線節點的全部可執行作業列表;對於每個作業,判斷prefer list中是否包含了新上線的節點;如果是,則摘取其中全部的分片;這些已經處理過的作業稱為預處理作業;
第二步,從新上線節點的作業列表中減去預分配作業,然後使用以下的方法依次摘取:
- 假如上線的executor為a,它能處理的作業型別為j1,j2(已減去預分配列表)。遍歷當前域下的executor列表,拿掉全部作業型別為j1,j2的分片,加上尚未分配的j1,j2作業分片列表,作為演算法的待分配列表
- 在處理每個節點時,每拿掉一個作業分片後判斷被拿掉的負載(load)是否已經超過了自身處理前總負載(load)的1/n(n為當前executor節點的總數量),如果超過,則本執行節點摘取完成,繼續處理下一個執行節點;如果不超過則繼續摘取,直到超過(大於等於)為止。
放回:
a.構造需要新增的作業分片列表,我們起名為待分配列表,長度為n,待分配列表按照負載(load)從大到小排序,排序時需保證相同作業的所有分片時連續的
b.構造每種作業型別的executor列表(如果有prefer list,且有存活,則該作業的executor列表就是prefer list),得到一個map<jobName,executorList>’
c.從待分配列表中依次取出第0到第n-1個作業分片jobi
d.從map中取出可執行jobi的executor列表listi
e.將jobi分配給listi中負載總和最小的executor
舉例如下:

(3.2)executor下線
摘取:取出下線的executor當前分配到的全部作業分片,作為演算法的待分配列表
放回:使用平衡演算法逐個處理待分配列表中的作業分片
(3.3)作業啟動
摘取:從所有executor中摘取將被啟動作業的全部分片作為演算法的待分配列表
放回:使用調整後的平衡演算法放回
(3.4)作業停止
摘取:將被停止的作業分片從各節點刪除
返回:無
注:Saturn架構文件請見https://github.com/vipshop/Saturn/wiki/Saturn架構文件
2.4、lts
LTS是一個輕量級分散式任務排程框架,主要用於解決分散式任務的排程問題,支援實時任務、定時任務和Cron任務,有較好的伸縮性、擴充套件性以及健壯穩定性。他參考hadoop的思想,主要有以下四個節點:
- JobClient:主要負責提交任務,並接收任務執行的反饋結果
- JobTracker:負責接收並分配任務,任務排程
- TaskTracker:負責執行任務,執行完反饋給JobTracker
- LTS-Admin:(管理後臺)主要負責節點管理,任務佇列管理,監控管理等
其中JobClient、JobTracker、TaskTracker是無狀態的,可以部署多個並動態的進行刪減,來實現負載均衡,實現更大的負載量,並且框架採用FailStore策略使得LTS具有很好的容錯能力。

一個典型的定時任務,大概的執行流程如下:
- 新增任務以後在註冊中心進行註冊,zk叢集會暴露各個節點的資訊,進行master節點選舉等
- JobClient將任務進行提交,如果成功的話將進行下一步;否則的話進入FailStore,重試
- JobTracker接收並分配任務,如果任務已經存在,則結束;否則任務進入可執行佇列ExecutableJobQueue,接著進入執行中任務佇列ExecutingJobQueue,最後傳送給TaskTracker進行執行
- TaskTracker執行完畢後,將結果反饋給客戶端;如果反饋成功,則回到JobClient執行下一個任務;否則的話進入FeedbackJobQueue重試
2.5、quartz
Quartz是OpenSymphony開源組織在任務排程領域的一個開源專案,完全基於java實現。作為一個優秀的開源框架,Quartz具有以下特點:強大的排程功能、靈活的應用方式、分散式和叢集能力,另外作為spring預設的排程框架,很容易實現與Spring整合,實現靈活可配置的排程功能。
Quartz的核心元素如下:
- Scheduler:任務排程器,是實際執行任務排程的控制器
- Trigger;觸發器,用於定義任務排程的時間規則
- Calendar:它是一些日曆特定時間的集合,一個Trigger可以包含多個Calendar,以便於排除或包含某些時間點
- JobDetail:用來描述Job實現類及其他相關的靜態資訊,如Job的名字、關聯監聽器等資訊
- Job:是一個介面,只有一個方法void execute(JobExecutionContext context),開發者實現該介面定義執行任務,JobExecutionContext類提供了排程上下文的各種資訊
Quartz的單機版大家應該都比較熟悉,它的叢集方案是使用資料庫來實現的。叢集架構如下:
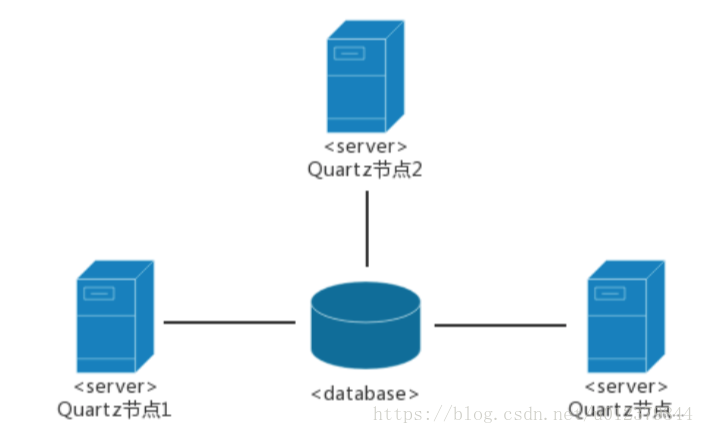
上圖3個節點在資料庫中都有同一份Job定義,如果某一個節點失效,那麼Job會在其他節點上執行。因為每個節點上的程式碼都是一樣的,那麼如何保證只有一臺機器上觸發呢?答案是使用了資料庫鎖。在quartz叢集解決方案了有張scheduler_locks,採用了悲觀鎖的方式對triggers表進行了行加鎖,以保證任務同步的正確性。
簡單來說,quartz的分散式排程策略是以資料庫為邊界的一種非同步策略。各個排程器都遵守一個基於資料庫鎖的操作規則從而保證了操作的唯一性,同時多個節點的非同步執行保證了服務的可靠。但這種策略有自己的侷限性:叢集特性對於高CPU使用率的任務效果特別好,但是對於大量的短任務,各個節點都會搶佔資料庫鎖,這樣就出現大量的執行緒等待資源。Quartz的分散式只解決了任務高可用的問題,並沒有解決任務分片的問題,還是會有單機處理的極限。
2.6、TBSchedule
TBSchedule是一款非常優秀的分散式排程框架,廣泛應用於阿里巴巴、淘寶、支付寶、京東、汽車之家等很多網際網路企業的流程排程系統。TBSchedule在時間排程方面雖然沒有quartz強大,但是它支援分片的功能。和quartz不同的是,TBSchedule使用zk來實現任務排程的高可用和分片。純java開發。

TBSchedule專案實際上可以分為兩部分。1)schedule管理控制檯。負責控制、監控任務執行狀態。2)實際執行job的客戶端程式。在實際使用時,需要先啟動zk,然後部署TBSchedule web介面的管理控制檯,最後啟動實際執行job的客戶端程式。這裡的zk並不實際控制任務排程,它只是負責與N臺執行job任務的客戶端進行通訊,協調、管理、監控這些機器的執行資訊。實際分配任務的是管理控制檯,控制檯從zk獲取job的執行資訊。TBSchedule通過控制ZNode的建立、修改、刪除來間接控制job的執行,執行任務的客戶端監聽它們對應ZNode的狀態更新事件,從而達到TBSchedule控制job執行的目的。特點:
- TBSchedule的分散式機制是通過靈活的Sharding方式實現的,比如可以按所有資料的ID按10取模分片、按月份分片等,根據不同的場景由客戶端配置分片規則。
- TBSchedule的宿主伺服器可以進行動態的擴容和資源回收,這個特點主要是因為它後端依賴的zooKeeper,這裡的zooKeeper對於TBSchedule來說相當於NoSQL,用於儲存策略、任務、心跳等資訊資料,他的資料結構類似於檔案系統的目錄結構,他的節點有臨時節點、持久節點之分。一個新的伺服器上線後,會在zk中建立一個代表當前伺服器的一個唯一性路徑(臨時節點),並且新上線的伺服器會和zk保持長連線,當通訊斷開後,節點會自動刪除。
- TBSchedule會定時掃描當前伺服器的數量,重新進行任務分配。
- TBSchedule不僅提供了服務端的高效能排程服務,還提供了一個scheduleConsole war隨著宿主應用的部署直接部署到伺服器,可以通過web的方式對排程的任務、策略進行監控管理,以及實時更新調整。
2.7、xxl-job
xxl-job是一個輕量級的分散式任務排程框架,其核心設計目標是開發迅速、學習簡單、輕量級、易擴充套件。
xxl-job的設計思想為:
(1)將排程行為抽象形成“排程中心”公共平臺,而平臺自身並不承擔業務邏輯,“排程中心”負責發起排程請求
(2)將任務抽象成分散的JobHandler,交由執行器統一管理,執行器負責接收排程請求並執行對應的JobHandler中業務邏輯
因此,“排程”和“任務”可以互相解偶,提高系統整體的穩定性和擴充套件性。
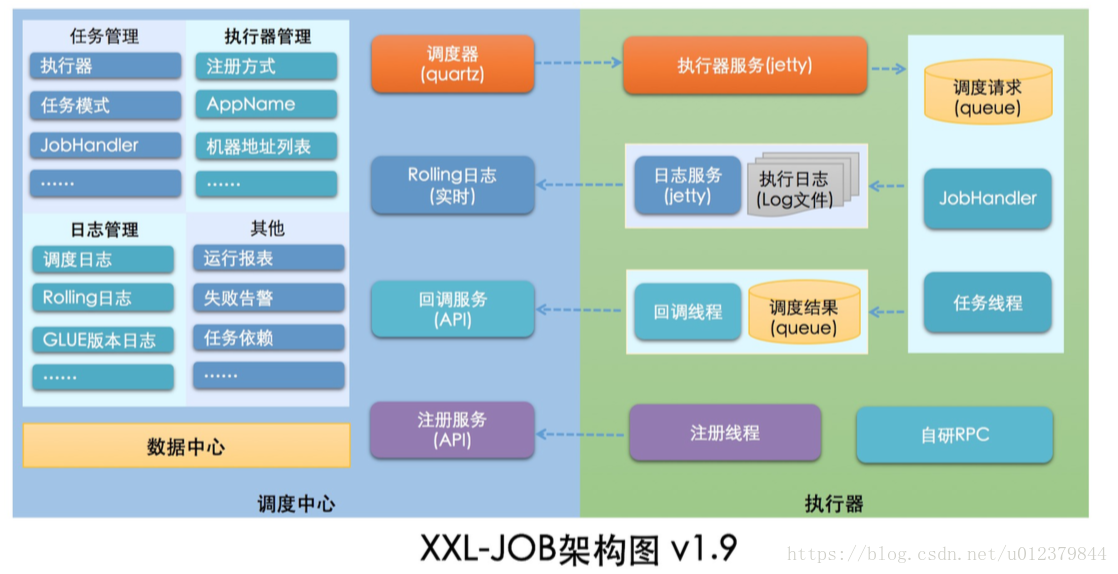
xxl-job系統的組成分為:
(1)排程模組(排程中心):負責管理排程資訊,按照排程配置發出排程請求,自身不承擔業務程式碼。排程系統與任務解耦,提高了系統可用性和穩定性,同時排程系統性能不再受限於任務模組;支援視覺化、簡單且動態的管理排程資訊,包括任務新建,更新,刪除,GLUE開發和任務報警等,所有上述操作都會實時生效,同時支援監控排程結果以及執行日誌,支援執行器Failover。
(2)執行模組(執行器):負責接收排程請求並執行任務邏輯。任務模組專注於任務的執行等操作,開發和維護更加簡單和高效;接收“排程中心”的執行請求、終止請求和日誌請求等。
Xxl-job的執行流程:
首先準備一個將要執行的任務,任務開啟後到執行器中註冊任務的資訊,載入執行器的配置檔案,初始化執行器的資訊,然後執行器start。在admin端配置任務資訊,配置執行器的資訊。就可以控制任務的狀態了。
xxl-job的特性為:
- 簡單:支援通過web頁面對任務進行CRUD操作,操作簡單
- 動態:支援動態修改任務狀態、暫停/恢復任務,以及終止執行中的任務,即時生效
- 排程中心HA(中心式):排程採用中心式設計,“排程中心”基於叢集Quartz實現並支援叢集部署,可保證排程中心HA
- 執行器HA:任務分散式執行,任務執行器支援叢集部署,可保證任務執行HA
- 註冊中心:執行器會週期性自動註冊任務並觸發執行。同時,也支援手動錄入執行器地址
- 彈性擴容縮容:一旦有新的執行器機器上線或下線,下次排程時會重新分配任務
- 路由策略:執行器叢集部署時提供豐富的路由策略,包括:第一個、最後一個、輪詢、隨機、最不經常使用、故障轉移等
- 故障轉移:任務路由策略選擇"故障轉移"情況下,如果執行器叢集中某一臺機器故障,將會自動Failover切換到一臺正常的執行器傳送排程請求。
- 阻塞處理策略:排程過於密集執行器來不及處理時的處理策略,策略包括:單機序列、丟棄後續排程、覆蓋之前排程
- 任務超時控制:支援自定義任務超時時間,任務執行超時將會主動中斷任務;
- 任務失敗重試:支援自定義任務失敗重試次數,當任務失敗時將會按照預設的失敗重試次數主動進行重試;
- 失敗處理策略;排程失敗時的處理策略,預設提供失敗告警、失敗重試等策略;
- 分片廣播任務:執行器叢集部署時,任務路由策略選擇"分片廣播"情況下,一次任務排程將會廣播觸發叢集中所有執行器執行一次任務,可根據分片引數開發分片任務;
- 動態分片:分片廣播任務以執行器為維度進行分片,支援動態擴容執行器叢集從而動態增加分片數量,協同進行業務處理;在進行大資料量業務操作時可顯著提升任務處理能力和速度。
- 事件觸發:除了"Cron方式"和"任務依賴方式"觸發任務執行之外,支援基於事件的觸發任務方式。排程中心提供觸發任務單次執行的API服務,可根據業務事件靈活觸發。
- 任務進度監控:支援實時監控任務進度;
- Rolling實時日誌:支援線上檢視排程結果,並且支援以Rolling方式實時檢視執行器輸出的完整的執行日誌;
- GLUE:提供Web IDE,支援線上開發任務邏輯程式碼,動態釋出,實時編譯生效,省略部署上線的過程。支援30個版本的歷史版本回溯。
- 指令碼任務:支援以GLUE模式開發和執行指令碼任務,包括Shell、Python、NodeJS等型別指令碼;
- 任務依賴:支援配置子任務依賴,當父任務執行結束且執行成功後將會主動觸發一次子任務的執行, 多個子任務用逗號分隔;
- 一致性:“排程中心”通過DB鎖保證叢集分散式排程的一致性, 一次任務排程只會觸發一次執行;
- 自定義任務引數:支援線上配置排程任務入參,即時生效;
- 排程執行緒池:排程系統多執行緒觸發排程執行,確保排程精確執行,不被堵塞;
- 資料加密:排程中心和執行器之間的通訊進行資料加密,提升排程資訊保安性;
- 郵件報警:任務失敗時支援郵件報警,支援配置多郵件地址群發報警郵件;
- 推送maven中央倉庫: 將會把最新穩定版推送到maven中央倉庫, 方便使用者接入和使用;
- 執行報表:支援實時檢視執行資料,如任務數量、排程次數、執行器數量等;以及排程報表,如排程日期分佈圖,排程成功分佈圖等;
- 全非同步:系統底層實現全部非同步化,針對密集排程進行流量削峰,理論上支援任意時長任務的執行;
- 國際化:排程中心支援國際化設定,提供中文、英文兩種可選語言,預設為中文;
xxl-job-lite的執行器實際是一個ConcurrentHashMap容器。
3、任務排程框架的技術選型?
1、Quartz:Java事實上的定時任務標準,但是關注點在於定時任務而非資料,雖然實現了高可用,但是缺少分散式並行排程的功能,效能低。
2、TBSchedule:阿里早期開源的分散式任務排程系統。程式碼略陳舊,使用的是Timer而不是執行緒池執行任務排程。TBSchedule的作業型別比較單一,只能是獲取/處理資料一種模式,文件缺失比較嚴重。
3、詳見分散式排程框架對比表格~
4、分散式任務排程框架的安裝與使用?
4.1、Elastic-job
1、環境準備:
jdk1.7+、zookeeper3.4.6+、maven3.0.4+
2、安裝zookeeper3.4.12並啟動

這裡zookeeper佔用了2181埠。

3、建立簡單任務
新增依賴:

寫一個簡單的任務:

在專案入口處新增作業的配置和zk的配置:

執行,得到結果:
4、下載Elastic-job-lite原始碼,使用maven進行打包。在elastic-job-lite/elastic-job-lite-console/target/elastic-job-lite-console-3.0.0.M1-SNAPSHOT/中,然後解壓,會有start.bat和start.sh兩個指令碼,啟動。
瀏覽器中輸入localhost:8899,就可以管理任務了。
4.2、xxl-job-lite
1、排程資料庫初始化,tables_xxl-job.sql
2、下載原始碼:包括排程中心+公共依賴+執行器示例
3、配置部署“排程中心”:修改資料庫配置——將專案進行打包——將xxl-job-admin包部署到tomcat上
4、輸入localhost:8080/xxl-job-admin即可訪問排程中心
5、配置部署執行器:xxl-job-executor-sample-springboot打成jar包直接執行,其他的打成war包部署在tomcat上。
6、寫一個任務,執行,去執行器上進行註冊,然後排程中心配置執行器資訊,新增任務
附錄
1、etcd
etcd是一個開源的、分散式的鍵值對資料儲存系統,提供共享配置、服務的註冊和發現。etcd內部採用raft協議作為一致性演算法,是基於Go語言實現的。
2、zookeeper
zookeeper是一個開源的分散式協調服務,它為分散式應用提供了高效且可靠的分散式協調服務,提供了諸如統一名稱空間服務、配置服務和分散式鎖等分散式基礎服務。
3、分散式鎖
假如我們由三臺機器,每臺機器上都有一個程序。假設我們在第一臺機器上掛載了一個資源,三個程序都要來競爭這個資源。我們不希望這三個程序同時來訪問,那麼就需要有一個協調器,來讓他們有序的對該資源進行訪問。這個協調器就是我們所說的那個鎖,比如說“程序1”在使用該資源的時候,就會先去獲得鎖,“程序1”就對該資源保持獨佔,這樣其他的程序就無法訪問該資源。“程序1”用完該資源後就會將鎖釋放掉,讓其他的程序來獲得鎖。因此這個鎖機制就能保證我們的程序有序的訪問該資源。就稱作為“分散式鎖”,是分散式協調技術實現的核心內容
4、分片
任務的分散式執行,需要將一個任務拆分為多個獨立的任務項,然後由分散式的伺服器分別執行某一個或幾個分片項。
5、單點故障
通常分散式系統採用主從模式,就是一個主控機連線多個處理節點。主節點負責分發任務,從節點負責處理任務,當我們的主節點發生故障時,那麼整個系統就癱瘓了,這就叫做單點故障。
傳統的解決辦法:
就是準備一個備用節點,這個備用節點定期給當前主節點發送ping包,主節點收到ping包後向備用節點發送回復Ack,當備用節點收到回覆後就會認為主節點還活著,讓他繼續提供服務。
當主節點掛了,那麼備用節點就收不到Ack回覆了,然後備用節點就代替它成為了主節點。
但是存在一個安全隱患,那就是當發生網路故障時,備用節點收不到主節點的回覆Ack,他會認為主節點死了,它會代替主節點成為新的主節點。
zookeeper解決方案:
在引入了zookeeper後我們啟用了兩個主節點,A和B啟動後他們都會去Zookeeper去註冊一個節點,假設A註冊的節點為master-01,B註冊的節點為master-02,註冊完之後進行選舉,編號最小的節點將被選舉為主節點。
如果A掛了,它在zookeeper註冊的節點將會被自動刪除,Zookeeper感知到節點的變化,然後再次發出選舉,這時候B將獲勝成為新的主節點。如果A恢復了,它會去zookeeper再註冊一個節點,編號為master-03。這時zookeeper感知到節點的變化,會再次發起選舉,此時還是B勝出。那麼B繼續擔任主節點,A則成為備用節點。
6、Mesos
——像用一臺電腦一樣使用整個資料中心
是Apache下的開源分散式資源管理框架,它被稱為分散式系統的核心,是以與Linux核心同樣的原則而建立的,不同點僅僅是在於抽象的層面。使用ZooKeeper實現Master和Slave的容錯。
7、FailStore策略
FailStrore,顧名思義就是Fail and Store,這個主要是用於失敗了儲存的,主要用於節點容錯,當遠端資料互動失敗後,儲存在本地,等待遠端通訊恢復後,再將資料進行提交。