
播放器核心設計
播放器核心設計
1 背景
前幾年負責過搜狐影音的播放器核心,這裡主要記錄、總結一下。
2 主要功能
- 播放線上mp4/flv;
- 疊加字幕/彈幕。
3 模組層次結構


- PlayerEngine.dll:主要提供對外介面,並進行音視訊的同步;
- PlayerCodecs.dll:主要負責音視訊分離、音視訊解碼,也就是Demux和Decoder;
- VADSDisplay.dll:主要呼叫DirectSound、DirectShow的Filter實現音視訊的渲染;
- flyfoxDSFilter.dll:實現了一個自定義的Source Filter,用於將視訊資料推送給DirectShow渲染器;
- flyfoxLocalPlayer.dll:實現了一個由DirectShow Filter組成的本地播放器。
4 執行緒模型/資料流
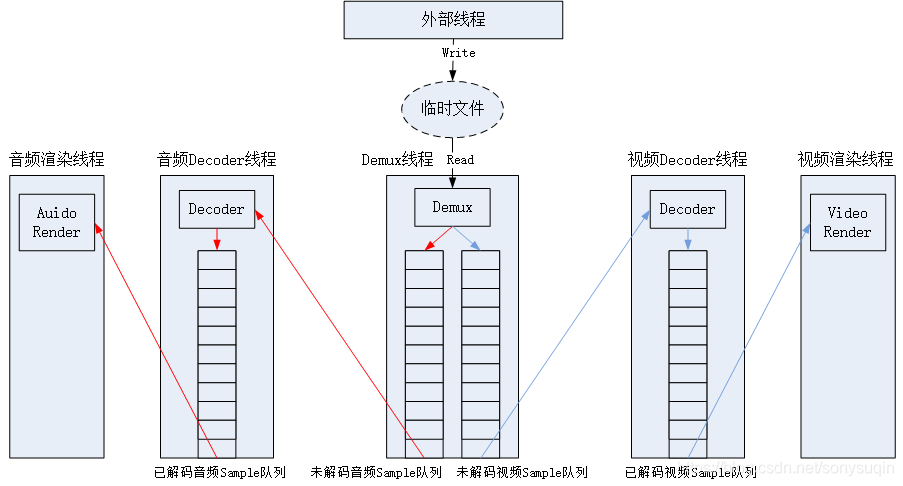
- 外部執行緒將視訊資料寫入臨時檔案;
- Demux執行緒將資料從臨時檔案讀入,並解析成未解碼的音訊、視訊Sample,放入各自的未解碼Samle佇列中;
- 音訊解碼執行緒、視訊解碼執行緒分別從未解碼的音訊、視訊佇列中獲取Sample,進行解碼,並放入各自的已解碼Sample佇列中;
- 音訊渲染執行緒從已解碼的音訊Sample佇列讀取已經解碼的PCM資料,放入DirectSound緩衝中進行播放;
- 視訊渲染執行緒從已解碼的視訊Sample佇列中讀取已經解碼的YUV影象幀,以音訊當前的播放時間戳為準進行音視訊同步,同步後視訊資料交給視訊渲染器進行渲染。
5 線上播放關鍵用例
5.1 Play mp4
5.1.1 單個分段
單個mp4分段是一個完整的mp4檔案,為了播放一個mp4檔案,需要:
- 解析mp4中的音、視訊Sample;
- 解碼這些音、視訊Sample;
- 渲染這些音、視訊Sample。
實際上播放任何一個檔案都需要3個模組來分別提供這些能力: - Demux:分離器,將封裝在一個檔案中的音、視訊Sample分離出來;
- Decoder:解碼器,將未解碼的音訊Sample解碼成PCM資料,將未解碼的視訊Sample解碼成YUV資料,分為音訊解碼器和視訊解碼器;
- Render:渲染器,分為音訊渲染和視訊渲染,分別用於渲染音訊、視訊資料,在系統底層將這些資料送入指定的硬體,從而實現播放聲音、視訊的效果。

5.1.1.1 解封裝
由Demux進行音、視訊Sample的解析,這裡啟動一個Demux執行緒,讀取檔案中的音、視訊Sample,分別放入待解碼音、視訊佇列。
執行緒函式:flyfox_player_mov_demux_read_cb
這個執行緒首先要解析mp4頭,只有解析完mp4頭才能進行後續的音、視訊Sample的讀取。下面通過讀取視訊Sample來展示需要哪些mp4頭中的資訊。
在快取資料足夠的情況下,讀取視訊Sample的過程:
- 首先維護一個當前需要讀取的視訊Sample的索引,這個索引將會持續累加;
- 查詢stsc box,得到視訊Sample索引對應的Chunk索引,以及該Sample在Chunk內的偏移數;
- 查詢stco box,得到該Chunk的偏移;
- 查詢stsz,通過累加Chunk的偏移和在Chunk的各個Sample的大小,得到指定Sample的偏移以及大小;
- 從檔案中的指定偏移讀取指定大小的資料,得到一個視訊Sample,但是該Sample在送入待解碼視訊Sample佇列之前需要先做一些調整;
- 如果該Sample是檔案第一個Sample,那麼是IDR幀,需要重置解碼器,傳遞一些解碼引數。在第一個Sample前需要增加AVC Decoder Configuration Record,該資訊位於moov->trak->mdia->minf->stbl->avc1->avcC中,主要包含sps、pps等資料,目的是將解碼器需要的一些引數告訴解碼器,否則解碼器無法正常工作;
- 在Sample中包含若干個NALU,視訊資料送入解碼器之前需要將每個NALU前面的x個位元組的NALU長度修改成分隔符“00 00 00 01”,x也是從 AVC Decoder Configuration Record中獲得,一般是4,mp4中放x個位元組的NALU長度是為了方便讀取NALU,而解碼器需要NALU之間通過“00 00 00 01”進行分隔,否則解碼器無法正常解碼;
- 經過上述步驟讀取並處理後的Sample是一個解碼器可以處理的Sample,可以放入待解碼視訊Sample佇列。
根據上述描述可以知道,解析視訊Sample需要用到的mp4 box如下:
| 序號 | Box | 欄位 | 作用 |
|---|---|---|---|
| 1. | stsc | First Chunk、Sample Per Chunk | 可以從Sample索引獲得Chunk索引,以及Sample在Chunk內的索引。 |
| 2. | stco | Chunk Offset | 每個Chunk的Offset。 |
| 3. | stsz | Sample Size | 每個Sample的大小。 |
| 4. | avcC | AVC Decoder Configuration Record | 獲得NALU長度以及ssp、pps等解碼引數。 |
對音訊Sample的讀取來說就比較簡單,直接通過stsc、stco、stsz獲取到指定的Sample的偏移、大小,然後從檔案中讀取Sample即可,也就是隻需要實現讀取視訊Sample的1~5步對應的操作,然後將讀到的音訊Sample直接放入待解碼音訊Sample佇列。
5.1.1.2 解碼
這裡使用ffmpeg進行音、視訊的解碼。
- 視訊解碼步驟
以H264解碼為例:
a) 初始化:
//註冊所有編解碼器。
avcodec_register_all();
//初始化AVPacket,作為輸入引數。
AVPacket packet; //宣告AVPacket。
av_init_packet(&packet); //輸入Sample將傳入packet。
//建立AVFrame,作為解碼輸出引數。
AVFrame* pFlyfoxAVFrame = avcodec_alloc_frame();
//找到H264解碼器
AVCodec *pAVCodec = avcodec_find_decoder(AV_CODEC_ID_H264);
//建立AVCodecContext
AVCodecContext* pAVCodecContext = avcodec_alloc_context3(pAVCodec);
//開啟解碼器
avcodec_open2(pAVCodecContext, pAVCodec,0);
b) 解碼
//設定輸入引數
packet.data = src;
packet.size = size;
//解碼
int got_pic = false;
avcodec_decode_video2(&pAVCodecContext,pFlyfoxAVFrame,&got_pic,&packet);
c) 拷貝資料
解碼出來的YUV資料存放在AVFrame結構中,Pixel Format預設為YUV420P(I420P)型別,拷貝資料用到的成員如下:
//拷貝Y分量
for(i = 0; i < pFlyfoxAVFrame->height; i++)
{
pSrc = pFlyfoxAVFrame->data[0] + i * pFlyfoxAVFrame->linesize[0];
memcpy(pDst, pSrc, pFlyfoxAVFrame->width);
pDst += pFlyfoxAVFrame->width;
}
//拷貝U分量
for(i = 0; i< pFlyfoxAVFrame ->height/2; i++) //行數減半
{
pSrc = pFlyfoxAVFrame->data[1] + i * pFlyfoxAVFrame->linesize[1];
memcpy(pDst, pSrc, pFlyfoxAVFrame->width/2);
pDst += pFlyfoxAVFrame->width/2; //列數減半
}
//拷貝V分量
for(i = 0; i < g_pFlyfoxAVFrame->height/2; i++) //行數減半
{
pSrc = pFlyfoxAVFrame->data[2] + i * pFlyfoxAVFrame->linesize[2];
memcpy(pDst, pSrc, pFlyfoxAVFrame->width/2);
pDst += pFlyfoxAVFrame->width/2; //列數減半
}
- 音訊解碼步驟:
音訊解碼過程跟視訊解碼基本相同,主要區別:
- 尋找的解碼器是AAC的解碼器;
- 在解碼前,在輸入的音訊資料前要加一個AAC ADTS頭;
- 要呼叫avcodec_decode_audio4解碼;
- 解碼後得到AV_SAMPLE_FMT_FLTP型別的資料,根據渲染器需要必須轉換成AV_SAMPLE_FMT_S16型別,也就是浮點型別轉換成16位整型。
其他步驟完全相同。
a) 初始化:
//註冊所有編解碼器。
avcodec_register_all();
//初始化AVPacket,作為輸入引數。
AVPacket packet; //宣告AVPacket。
av_init_packet(&packet); //輸入Sample將傳入packet。
//建立AVFrame,作為解碼輸出引數。
AVFrame* pFlyfoxAVFrame = avcodec_alloc_frame();
//找到AAC解碼器
AVCodec *pAVCodec = avcodec_find_decoder(CODEC_ID_AAC);
//建立AVCodecContext
AVCodecContext* pAVCodecContext = avcodec_alloc_context3(pAVCodec);
//開啟解碼器
avcodec_open2(pAVCodecContext, pAVCodec,0);
b) 解碼
//設定輸入引數
packet.data = src;
packet.size = size;
//解碼
int got_audio = false;
avcodec_decode_audio4 (&pAVCodecContext,pFlyfoxAVFrame,&got_audio,&packet);
//如果是AV_SAMPLE_FMT_FLTP型別需要轉換成AV_SAMPLE_FMT_S16
SwrContext *swr = NULL;
swr = swr_alloc_set_opts(swr,AV_SAMPLE_FMT_S16);
swr_init(swr);
if (pAVCodecContext->sample_fmt == AV_SAMPLE_FMT_FLTP)
{
swr_convert(swr,dst_buffer);
}
5.1.1.3 渲染
這裡採用的是DirectShow框架來播放視訊,在DirectShow框架中,所有的功能被封裝在各個Filter中。DirectShow中提供了一些Render Filer來渲染視訊,例如evr、vmr7、vmr9等,可以充分利用顯示卡進行硬體加速,達到比較好的顯示效果。為了將已經解碼的視訊資料交給Render Filer,需要建立一個Source Filer,通過管腳將Source Filer和Render Filer進行連線,類似一個管道,在Source Filer的輸出管腳上PushFrame時,Render Filer將能通過輸入管腳獲得視訊資料,交給顯示卡渲染播放。
flyfoxDSFilter.dll實現了一個視訊的Source Filer,作為一個COM元件,其實現了COM元件的相關介面,並實現了一個IFlyfoxDirectSrc介面,用於向外部提供Source Filter的相關功能,PushFrame就是其中一個方法,用於推送視訊資料。
在VADSDisplay.dll中,封裝了音、視訊Render Filer的相關介面,並將Render Filter與Source Filter連線,解碼器在解碼得到裸資料後,播放執行緒呼叫VADSDisplayer的介面,將解碼後的視訊資料分別送入各自的Render Filer。
注意這裡沒有使用DirectShow的音訊DirectSound Filter,而是直接呼叫DirectSound的介面,這樣可以不用實現音訊的Source Filter,同時更靈活運用DirectSound的特性。
5.1.1.4 音視訊同步
這裡採用的時鐘源是音訊流的時鐘,因為音效卡基本都有自己的時鐘源。
在開啟檔案後,從檔案頭中獲得了音訊的位元速率,從而得到了音訊資料偏移跟音訊播放時間戳的關係:音訊播放時間戳=音訊資料偏移/音訊位元速率。
這個播放時間在DirectShow中稱為流時間(Stream Time),是描述相對於某個參考位置(如開始播放時間)的時間差。
音訊播放會呼叫DirectSound的介面,DirectSound維護了當前播放的音訊資料緩衝的播放偏移,因此可以通過上述公式換算成音訊時間戳。
視訊渲染執行緒首先獲得這個音訊時間戳ta,然後檢查當前準備播放的視訊Sample的時間戳tv,如果ta≥tv,則該視訊Sample沒有提前到來,應該立刻播放,如果時間差過大,則考慮丟棄;如果ta<tv,說明還沒有到該Sample的顯示時間,應該等待tv-ta的時間。
5.1.2 多個分段
搜狐視訊的單個劇一般由多個分段構成,每個分段一般是5分鐘,在播放一個劇的多個分段的過程中需要面臨的一個問題是不同分段之前的切換,如果分段切換的過程中出現卡頓,則會影響使用者的觀看體驗,這裡採用了預載入下一分段的辦法來解決這個問題。

在flyfox_demux_decoder_filter中維護一個Demux demux[2]的陣列,分別表示播放中的和預載入中的Demux,每個Demux將處理不同的分段檔案。Decoder與Demux是解耦的,使用一個nSourceFilterIndex索引來表示當前正在使用的Demux,在需要切換的時候,關閉掉當前播放的Demux後,nSourceFilterIndex設定為正在預載入的Demux的索引,Decoder只需要從nSourceFilterIndex指定的Demux獲取資料即可。
注意預載入啟動的時機,如果太快啟動預載入則可能會造成浪費。比如使用者可能看到分段中間位置就Seek到檔案的最後一個分段,而不是下一個分段。這裡採取的策略是在當前分段播放到最後30秒的時候啟動下一個分段的預載入,這個時候可以認為使用者期望觀看下一分段。
5.2 Seek MP4
5.2.1 Seek前的準備
在進行實際的mp4 seek之前有一些操作,因為seek的時間可能不在當前已經快取的資料裡面。

影音的seek是基於整劇時間的seek,由於一個劇是由多段檔案組成,在進行實際的mp4檔案seek前,需要將seek絕對時間換算成對應的分段i和分段內的時間偏移t,如果已經快取了第i個分段mp4的完整資料,那麼直接在這個分段內seek到時間t,否則需要下載第i個分段的資料。注意這裡並不是下載整個分段的完整資料,而是下載seek到時間t後的分段mp4,對播控來說實際上是一個完整的mp4,但是並不是原始的完整分段,這樣做可以減少mp4頭的下載量,提高啟播速度。播控需要維護這個偏移時間t,在下次seek的時候,如果定位到同一分段i的時間t1,並且t1>=t,那麼可以直接在上次下載的mp4檔案中seek到t1-t位置。下面需要判斷資料是否足夠,如果資料足夠就直接在mp4檔案內seek,如果不夠的話,需要等待或者去請求t1開始的檔案。
如果seek的時間被定位到預載入的分段裡面,那麼上述的時間判斷可以省去,因為預載入的是完整的分段資料,這個時候只需要判斷資料是否足夠即可。
5.2.2 實際的seek
Seek的目標就是將時間換算成檔案偏移offset,從offset開始的位置開始讀取音、視訊的Sample,達到修改播放時間的目的。
mp4檔案內的seek跟mp4頭關係緊密,需要解析mp4頭中的若干box才能提供足夠的資訊。主要涉及的Box以及提供的資訊如下:
| 序號 | Box | 欄位 | 作用 |
|---|---|---|---|
| 1 | mdhd | time scale | 1秒的時間單位數,其倒數就是時間單位; |
| 2 | stts | Sample delta | 每個Sample的時間單位數,Sample的時間=Sample delta / time scale; |
| 3 | stss | Sample number | 這個表存放視訊關鍵幀的索引,可以通過該表得到距離指定Sample最近的關鍵幀Sample索引。 |
| 4 | stsc | First Chunk、Sample Per Chunk | 可以從Sample索引獲得Chunk索引,以及Sample在Chunk內的索引。 |
| 5 | stco | Chunk Offset | 每個Chunk的Offset |
| 6 | stsz | Sample Size | 每個Sample的大小 |
視訊Seek的步驟:
- 通過視訊trak->mdia->mdhd box得到Time Scale,也就是一秒有多少個時間單位;
- 查詢stss box,這個box裡面是一個表,每個記錄包含:一個Sample包含的時間單位數,擁有相同時間單位數的Sample的個數,遍歷這個表,累加訪問到的每個Sample的時間,直到累積時間≥seek time,這個時候得到最接近seek time的Sample索引;
- 查詢stss,這個box裡面是一個表,裡面有序地記錄了每個關鍵幀的索引,通過二分查詢,可以得到距離步驟2中的Sample索引最近的關鍵幀Sample索引,之所以尋找關鍵幀,是因為只有關鍵幀才能夠獨立解碼,普通幀需要參考幀,仍然需要等待關鍵幀;
- 再次查詢stss box,得到該關鍵幀對應的時間real seek time,也就是實際上能夠seek到的時間;
- 查詢stsc box,該box是一個表,裡面的每個記錄是一個Chunk組,組內的每個Chunk包含相同的Sample個數,每個記錄包含:Chunk組的開始Chunk索引,每個Chunk的Sample數,從表開始遍歷這個表,疊加Sample數,直到累加的Sample數=關鍵幀的Sample索引,這個時候可以得到其所處的Chunk索引以及在Chunk內的Sample偏移數;
- 查詢stco,得到步驟5中的Chunk索引對應的偏移;
- 查詢stsz,利用關鍵幀Sample索引和其在Chunk內的Sample偏移數,得到這個關鍵幀Sample相對於Chunk開始位置的偏移,這個偏移加上Chunk的偏移,就得到關鍵幀Sample的偏移。
音訊Seek的步驟和視訊Seek基本一樣,但是比視訊Seek簡單,沒有查詢關鍵幀的過程,直接通過普通Sample查詢其偏移即可。
5.3 Play flv
由於flv的音訊、視訊編碼與mp4完全相同,所以複用解碼的邏輯。實際上除了封裝格式不同,flv播放的其他邏輯跟mp4播放基本相同(56的flv只有一個分段,比多段的mp4更好處理),因此只需要實現一個flv Demux來解析flv中的頭、音訊、視訊資料。
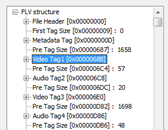
flv的解析包括解析flv頭和資料tag,實際上,flv除了9個位元組的沒有多少資訊的固定頭之外,所有資料都是由tag組成。flv有3種tag,分為Metadata Tag(或者叫指令碼tag)、Video Tag、Audio Tag。其前3個tag比較特殊,基本可以認為是flv頭,解析了這3個頭,就可以進行正常的flv播放、seek。這個3個tag分別是:
- 第1個Tag,Metadata Tag:包含了關鍵幀列表、視訊寬高、時間長度、檔案大小等;
- 第2個tag,Vidao Tag:主要包含AVC Decoder Configuration Record、視訊的格式等;
- 第3個tag,Audio Tag主要包含Audio Specifig Config、音訊的格式等。
後續的所有tag基本都是攜帶音訊、視訊資料的Tag,可以由前面的3個tag的資訊進行解析。例如視訊IDR幀需要的pps、sps來自第1個Video Tag的AVC Decoder Configuration Record,音訊解碼需要的一些ADTS資訊來自第1個Audio Tag的Audio Specifig Config。
5.4 Seek flv
Flv的seek操作與mp4有所區別,mp4的seek基於時間,將seek的絕對時間換算成分段號和分段內的時間偏移之後,向伺服器請求某個分段某個時間偏移的mp4檔案。這個操作成立的前提是:CDN支援這樣的介面。
但是對flv來說CDN並沒有這樣的介面,只有基於Http Range請求的介面,也就是基於檔案偏移。因此,flv的Seek需要播放引擎先獲得flv seek依賴的完整資訊,最主要的是關鍵幀列表,注意這個關鍵幀列表可能位於Script Tag中,但它並不是標準。如果沒有關鍵幀列表,那麼flv的seek將會變得低效,必須按照位元速率計算seek時間對應的檔案偏移,這個偏移並不是準確的tag偏移,只是估計tag偏移,必須下載這個位置之前的flv資料,累加tag的偏移,直達指標位置首次超過seek的估計tag偏移,並且需要繼續尋找關鍵幀對應的tag,這個時候才能完成一次seek。
幸好,絕大多數flv都遵守這麼一個規則,在Script Tag中按照時間順序存放了關鍵幀列表,這個列表中,每個欄位包含了關鍵幀的時間和偏移,這樣flv的Seek就只有一個簡單的二分查表的過程,比mp4的seek更簡單。
Seek過程:
- 檢查flv的頭是否完整,如果不,則繼續下載flv頭;
- 如果flv頭完整,則檢查關鍵幀列表,如果沒有,則返回失敗;
- 二分查詢flv關鍵幀列表,獲得離目標時間最接近的關鍵幀位置和偏移;
- 從關鍵幀偏移位置開始讀取tag和裡面的Sample。
5.5 軟字幕的實現
在Source Filter和Render Filer中間增加一個VsFilter,由VsFilter實現所有的字幕疊加操作,並向外提供相關的介面。其主要原理:VsFilter通過獲取輸出的文字路徑點集合,轉化成形狀,並光柵化成Bitmap畫素,然後與輸入的影象進行Alpha混合,達到字幕疊加的目的,實際上是影象疊加。所有的操作都是使用CPU進行計算,所以會明顯增加CPU的開銷。
官方老版本的VsFilter效能較差,這裡使用的是第3方優化後的XyVsFilter,與官方版本的主要區別是進行了大量的快取,省去一些重複性的渲染以降低CPU使用率。
主要流程:
- 載入VsFilter.dll,建立VsFilter的com例項,並獲取IID_IDirectVobSub介面,此時將建立檔案監控執行緒;
- 連線Source Filter、VsFilter、Render Filter,此時將建立字幕圖片生成執行緒;
- 呼叫IID_IDirectVobSub介面的put_FileName方法,設定字幕檔案,VsFilter將載入該字幕檔案,同時字幕圖片生成執行緒將建立字幕圖片快取;
- Filter Graph開始工作後,CDirectVobSubFilter::Transform函式獲得輸入Sample以及時間戳,通過輸入sample的時間戳查詢SubPic快取佇列中的圖片,如果查不到,則從Entry中查詢並生成bitmap,然後將字幕bitmap與輸入sample的surface進行疊加(alphablt),疊加完成進行適當的轉換(轉成YUY2),然後拷貝到輸出Sample。SubPic快取佇列維持長度為10,每消耗一條,則補充一條。

5.6 快取策略
上層的資料會寫入一個臨時檔案,在載入完成後,該臨時檔案是一個完整的mp4分段檔案,並在播放完成後刪除。在Demux內部維護一個初始大小為2M的記憶體快取,Demux從臨時檔案一次讀64KB資料到這個快取,每次解析mp4頭、解析Sample的時候其資料來源都直接來自這個記憶體快取。
在播放DRM視訊時,對快取有了新的需求:
- 涉及版權安全,不能寫檔案;
- 單個檔案可能比較大,mp4頭可能會大於2M,記憶體快取無法一次容納一個mp4頭;
因此在播放DRM視訊時,虛擬了一個記憶體的檔案快取,與磁碟檔案快取提供一樣的介面,用於為Demux提供資料。同時Demux的記憶體快取大小可變,在快取大小不夠時進行擴充套件。

由於DRM mp4檔案在記憶體中快取,所以不能將整個mp4完全快取在記憶體中,任何時刻,記憶體虛擬檔案中只保留mp4連續的一部分資料。記憶體虛擬檔案接收到Demux的讀取請求後檢查快取內是否有指定偏移的資料,如果有則拷貝返回,如果沒有則向傳輸層“拉”資料。每次記憶體虛擬檔案的資料被讀走,檢查有效的可用資料大小如果不到一半的快取總大小,則再次向傳輸層“拉”資料,期望填充滿整個快取。
5.7 VMR9和D3D的應用-全景視訊播放
VMR9有3種模式:Window、Windowless、Renderless。
- Window模式:需要Render建立自己的播放視窗並設定為上層應用視窗的子視窗,為響應父視窗的訊息,需要進行父視窗與子視窗的訊息互動;
- Windowless模式:Render無需建立自己的播放視窗,直接在上層應用視窗上繪製,在應用視窗重繪、修改視窗時需要通知Render;
- Renderless模式:VMR不再內部渲染,需要在外部藉助D3D等手段自行渲染。
在使用VMR9渲染的情況下,使用的策略是優先使用Renderless模式,如果無法使用Renderless模式,則使用Windowless模式。
在Renderless模式下,需要建立一個Presenter-Allocator,用於替代VMR9內部的渲染機制,並接受VMR9傳遞的影象資料,使用D3D進行渲染。

D3D對影象資料的處理流程:建立某個形狀的頂點緩衝,並建立一個紋理,將影象資料拷貝到紋理上,然後將紋理貼圖到頂點緩衝對應的形狀,之後就是D3D內部的渲染過程。
CPlaneScene與CSphereScene的區別是CPlaneScene建立矩形頂點緩衝而CSphereScene建立球面頂點緩衝,分別對應普通視訊播放和全景視訊播放。
在全景視訊播放時,影象一般是2:1的寬高比,可以完整覆蓋在球面上,這樣通過球面的扭曲可以將本身就扭曲的360°全景視訊在視場內還原,另外通過響應滑鼠、鍵盤等事件調整視點、透視矩陣,可以完整實現全景視訊的播放以及旋轉、拉近、拉遠等互動。
6 本地播放
本地播放視訊全部通過DirectShow的Filter實現。
在DirectShow內部,Filter的連線一般由GraphBuilder自動完成,稱為智慧連線。但是在這裡自定義了類似智慧連線的過程,使用策略是:先使用自定義的的連線策略,如果自定義連線策略失敗則使用DirectShow的智慧連線。
自定義連線流程:
- 定義一個FilterInfo.xml,描述了所有支援的Filter以及資訊,初始化時將這些Filter的資訊全部載入;
- 從Source Filter開始,先列舉這項Filter資訊,找到所有Source Filter,檢查該Filter是否支援傳入的檔案url和媒體型別,如果支援則設定其為使用的Source Filter並從該Source Filter開始渲染;
- 進入渲染Filter流程,不論是什麼型別的Filter都走這個流程:
1) 列舉輸出管腳,渲染該管腳:
1> 列舉該管腳上的所有媒體型別,渲染該媒體型別;
a) 列舉Filter Graph上的所有Filter,嘗試用該媒體型別連線這些Filter;
b) 如果連線成功,則遞迴呼叫渲染Filter流程繼續向下渲染該Filter。
用以上迭代+遞迴的辦法直到連線到Render Filter,最後完成整個連線過程。一個典型的Filter連線圖如下:
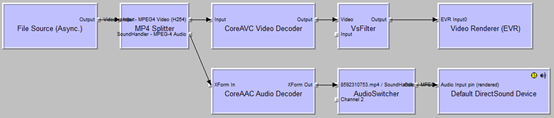
- File Source(Async.):Source Filter,實現檔案的讀取,屬於“拉”模式;
- MP4 Splitter:Transform Filter,Demux,用於分離音、視訊流;
- CoreAVC Video Decoder:Transform Filter,Decoder,用於視訊解碼;
- VsFilter:Transform Filter,字幕外掛;
- Video Render(EVR):Render Filter,用於視訊渲染;
- CoreAAC Audio Decoder,Transform Filter,Decoder,用於音訊解碼;
- AudioSwitcher:Transform Filter,用於切換聲道;
- Default DirectSound Device:Render Filter,用於聲音渲染。