
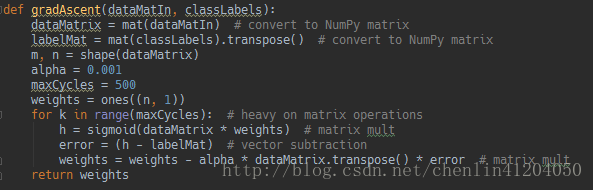
機器學習實戰—第5章:Logistic迴歸中程式清單5-1中的數學推導
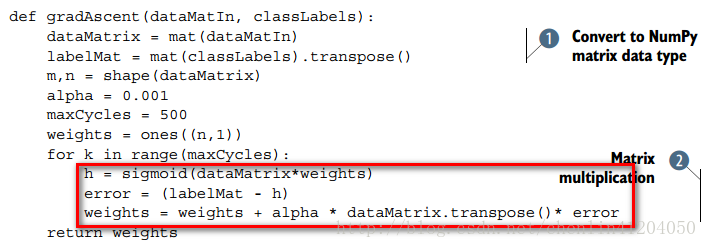
如圖中梯度上升法給出的函式程式碼。
假設函式為:
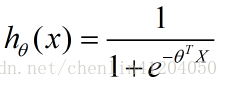
1、梯度上升演算法(引數極大似然估計值):
通過檢視《統計學習方法》中的模型引數估計,分類結果為類別0和類別1的概率分別為:
則似然函式為:
對數似然函式為:
最大似然估計求使得對數似然函式取最大值時的引數
對
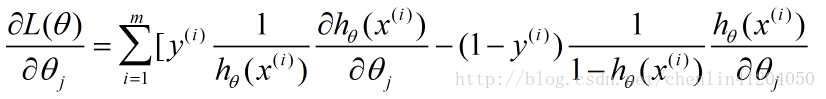
即為:
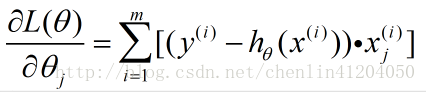
則單個特徵係數的梯度上升法的迭代公式為:
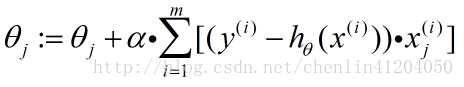
對整個特徵引數向量的梯度上升法的迭代公式為:
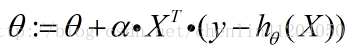
2、當然也可以採用梯度下降方法(代價函式最小化)
這部分可以參考吳恩達老師的《機器學習》視訊,就不詳細說明了。
代價函式為:
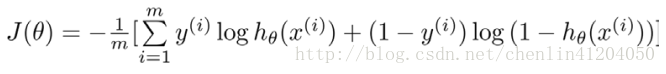

求導得到:
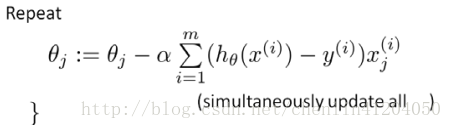
對引數向量有:
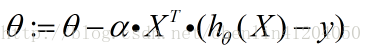
相關推薦
機器學習實戰—第9章:樹迴歸 程式程式碼中的小錯誤
提示:本人程式碼執行在Python3的環境下 1、程式清單9-1: 應改為: list(map(float, curLine)) 解釋:map()返回結果是一個Iterator,Iterator是惰性序列,因此通過list()函式讓它把整個序列都計算出來並返回
【機器學習實戰—第4章:基於概率論的分類方法:樸素貝葉斯】程式碼報錯(python3)
1、報錯:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xae in position 199: illegal multibyte sequence 原因:這是檔案編碼的問題,檔案中有非法的多位元組字元。 解決辦法:開啟Ch04\
機器學習實戰—第5章:Logistic迴歸中程式清單5-1中的數學推導
如圖中梯度上升法給出的函式程式碼。 假設函式為: 1、梯度上升演算法(引數極大似然估計值): 通過檢視《統計學習方法》中的模型引數估計,分類結果為類別0和類別1的概率分別為: 則似然函式為: 對數似然函式為: 最大似然估計求使得對數似然函式取最大值時的引數
《機器學習實戰》第五章:Logistic迴歸(1)基本概念和簡單例項
最近感覺時間越來越寶貴,越來越不夠用。不過還是抽空看了點書,然後整理到部落格來。 加快點節奏,廢話少說。 Keep calm & carry on. ----------------------------------------------------------
《機器學習實戰》筆記--第五章:Logistic迴歸
知識點1:python strip()函式和Split函式的用法總結原文程式碼:def loadDataSet(): dataMat = [] labelMat = [] fr = open('testSet.txt') for line in
機器學習實戰第五章Logistic回歸
表示 article err () tail mat cycle col transpose def gradAscent(dataMatIn, classLabels): dataMatrix = mat(dataMatIn) #co
機器學習實戰第8章預測數值型數據:回歸
矩陣 向量 from his sca ima 用戶 targe 不可 1.簡單的線性回歸 假定輸入數據存放在矩陣X中,而回歸系數存放在向量W中,則對於給定的數據X1,預測結果將會是 這裏的向量都默認為列向量 現在的問題是手裏有一些x
程式碼註釋:機器學習實戰第2章 k-近鄰演算法
寫在開頭的話:在學習《機器學習實戰》的過程中發現書中很多程式碼並沒有註釋,這對新入門的同學是一個挑戰,特此貼出我對程式碼做出的註釋,僅供參考,歡迎指正。 1、匯入資料: #coding:gbk from numpy import * import operator de
程式碼註釋:機器學習實戰第12章 使用FP-growth演算法來高效發現頻繁項集
寫在開頭的話:在學習《機器學習實戰》的過程中發現書中很多程式碼並沒有註釋,這對新入門的同學是一個挑戰,特此貼出我對程式碼做出的註釋,僅供參考,歡迎指正。 #coding:gbk #作用:FP樹中節點的類定義 #輸入:無 #輸出:無 class treeNode:
機器學習實戰第7章——利用AdaBoost元算法提高分類性能
nes 重要性 function mine spl 技術 可能 copy elar 將不同的分類器組合起來,這種組合結果被稱為集成方法或元算法(meta-algorithm)。 使用集成方法時會有多種形式:(1)可以是不同算法的集成(2)可以是同一種算法在不同設置下的集成
機器學習實戰第11章——使用 Apriori 演算法進行關聯分析
從大規模資料集中尋找物品間的隱含關係被稱作關聯分析(association analysis)或者關聯規則學習(association rule learning)。 優點:簡單 缺點:對大資料集比較慢 使用資料型別:數值型或者標稱型
機器學習實戰-第六章(支援向量機)
1 拉格朗日乘子法(等式約束): 目標函式:f(x)=b+wTxi+∑(αihi),s.t.hi=0 最優解條件:∂h∂xi=0 2 kkt(不等式約束): 目標函式:f(x)=b+wTxi+∑(αigi)+∑(βihi),s.t.hi=0,gi≤0
機器學習實戰第四章——樸素貝葉斯分類(原始碼解析)
樸素貝葉斯分類 #coding=utf-8 ''' Created on 2016年1月9日 @author: admin ''' from numpy import * # 載入資料集函式 def loadDataSet(): # 定義郵件列表 p
機器學習實戰 第九章回歸樹錯誤
最近一直在學習《機器學習實戰》這本書。感覺寫的挺好,並且在網上能夠輕易的找到python原始碼。對學習機器學習很有幫助。 最近學到第九章樹迴歸。發現程式碼中一再出現問題。在網上查了下,一般的網上流行的錯誤有兩處。但是我發現原始碼中的錯誤不止這兩處,還有個錯誤在
機器學習實戰第三章——決策樹(原始碼解析)
機器學習實戰中的內容講的都比較清楚,一般都能看懂,這裡就不再講述了,這裡主要是對程式碼進行解析,如果你很熟悉python,這個可以不用看。 #coding=utf-8 ''' Created on 2016年1月5日 @author: ltc ''' from mat
《機器學習實戰》第二章:k-近鄰演算法(3)手寫數字識別
這是k-近鄰演算法的最後一個例子——手寫數字識別! 怎樣?是不是聽起來很高大上? 呵呵。然而這跟影象識別沒有半毛錢的關係 因為每個資料樣本並不是手寫數字的圖片,而是有由0和1組成的文字檔案,就像這樣: 嗯,這個資料集中的每一個樣本用圖形軟體處理過,變成了寬高
機器學習實戰第六章支援向量機照葫蘆畫瓢演算法實踐
支援向量機簡要介紹 一些概念: 1.分隔超平面:在二維中直觀來說就是將資料集分隔開來的直線,三維中則是一個平面。觸類旁通。 2.超平面:分類的決策邊界,分佈在超平面一側的所有資料都屬於某個類別,另一側屬於另一個。 3.支援向量:離分隔超平面最近的那些
機器學習實戰第三章程式碼3-2註釋
按照給定特徵劃分資料集 ""splitDataSet函式引數: dataSet為輸入資料集,包含label值;axis為每行的第axis元素,value為對應元素的值,即特徵值。 函式功能:找出所有
《機器學習實戰》第二章:k-近鄰演算法(1)簡單KNN
收拾下心情,繼續上路。 最近開始看Peter Harrington的《Machine Learning in Action》... 的中文版《機器學習實戰》。準備在部落格裡面記錄些筆記。 這本書附帶的程式碼和資料及可以在這裡找到。 這本書裡程式碼基本是用python寫的
機器學習實戰第三章——決策樹程式
在閱讀理解決策樹之後,按照《機器學習實戰》的程式碼,實現ID3決策樹 程式如下: from math import log def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts