
K-means 演算法【基本概念篇】
寫在前面的話
k-means 演算法是一個聚類的演算法 也就是clustering 演算法。是屬於無監督學習演算法,也是就樣本沒有label(標籤)的算分,然後根據某種規則進行“分割”, 把相同的或者相近的objects 物體放在一起。
在這裡K就是我們想要分割的的聚類的個數。
當然了,很多資料都會說這個演算法吧,畢竟簡單粗暴可依賴
演算法描述
首先我們有以下的幾個點
| A1 | (2,10) |
| A2 | (2,5) |
| A3 | (8,4) |
| A4 | (5,8) |
| A5 | (7,5) |
| A6 | (6,4) |
| A7 | (1,2) |
| A8 | (4,9) |
這個演算法不能幫助我們自動分類,所以我們需要指定我們需要的個數。其實在很多實際應用當中,我們很難知道我們的資料是什麼分佈的,應該分成幾類比較好。這也是k-means自身的一個缺陷,所以不能幫助我們自動的聚類。
注:如果我在本文中說了分類,其實是分割的意思,我想表達的意思是聚類。
中文和英文切換,在意思上表達真的有點差距。
現在假設我們需要把上面的資料點分成三類。我們需要遵循下面的幾個步驟
- 選取三個類的初始中心
- 計算剩餘點到這三個中心的距離
- 將距離中心點距離最短的點歸為一類
- 依次劃分好所有的資料點
- 重新計算中心
- 重複2-5 個步驟,直到中心點不會在變化為止
現在看完步驟,其實可能會有一些疑問:
1. 怎麼選擇我們的初始中心點?
2. 怎麼計算點之間的距離呢。
選擇中心點
中心點怎麼選擇,一般情況下我們是隨機的從我們的資料集中選擇的。當然還會有其他的方法,我們在之後的文章中可能會討論。如果我還有時間去寫的話,一般我會有時間寫的。
甚至這個中心點的選擇可以是完全隨機的,甚至都不需要從我們的資料集中選取,在這裡,我們的資料集是一個二維的,所以我們可以選擇在XY座標上的任意三個點,隨你高興都是可以的
注意:中心點的選取不同,最後的聚類結果可能大不相同
在這裡我們假設我們的三個初始點是A,
在這裡我們選取的初始點是A1,A4,A7
在這裡我們定義兩個點之間的距離用曼哈頓聚類距離,也可以叫做城市街區距離。
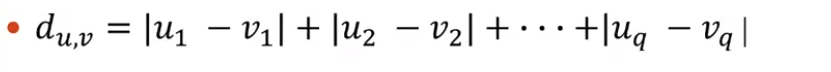
在這裡我們是二維座標,所以我們可以按照下面這個公式:
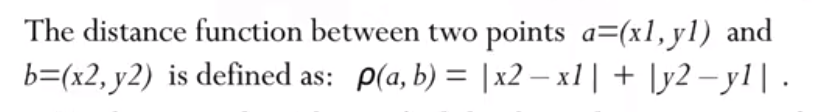
下面是一個例子:

計算的一般過程:
我們先看第一輪:

選取距離最近的歸為一類
這個時候我們得到的聚類的結果:

得到了第一輪的結果我們需要重新的計算每個聚類的中心
cluster1
對於第一個聚類只有一個點所以它的聚類的中心就是它自己。
Cluster2
X:
(8+5+7+6+4)/5 = 6
Y:
(4+8+5+4+9)/5 = 6
這個時候它的中心就變成了(6,6)
Cluster3:
X:
(2+1)/2 = 1.5
Y:
(5+2)/2 = 3.5
這個時候在進行第二輪迭代:

這個時候再次計算中心:

這個時候用我們的新的中心再來計算一遍:

這個時候我們在重新根據新的聚類重新計算我們的中心:

得到新的點之後我們在重新計算新的聚類

這個時候發現和上一次的結果是一致的,這個時候我們就可以停止我們的演算法了。
下面我們來看一下這個迭代過程的圖譜。
這個是我們的的初始過程

之後是我們選取中心點:

依次迭代的過程:


