
商品評價判別,文字分類——學習筆記
FASTTEXT(Facebook開源技術)
二分類任務,監督學習。
自然語言
NLP自然語言處理
語料Corpus:好評和差評
分詞Words Segmentation:基於HMM構建dict tree
構建詞向量Construct Vector:
one-hot獨熱編碼
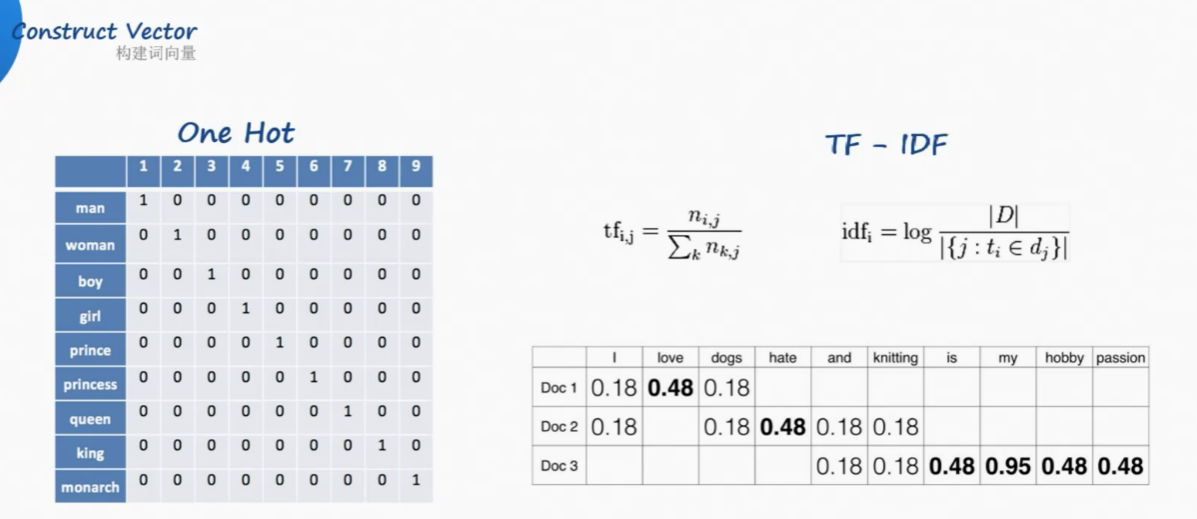
但是漢語中詞太多了,獨熱編碼的詞向量隨著詞庫中詞彙的增長,會變得非常大。
而且one hot沒法判斷順序
Google開山之作:TF-IDF(term frequency–inverse document frequency)
解決了頻率和特殊性的關係。TF即詞頻(Term Frequency),IDF即逆向文件頻率(Inverse Document Frequency)。
TF(詞頻)就是某個詞在文章中出現的次數,此文章為需要分析的文字。為了統一標準,有如下兩種計算方法:
(1)TF(詞頻) = 某個詞在文章中出現的次數 / 該篇文章的總次數;
(2)TF 詞頻 = 某個詞在文章中出現的次數 / 該篇文章出現最多的單詞的次數;
IDF(逆向文件頻率)為該詞的常見程度,需要構建一個語料庫來模擬語言的使用環境。
IDF 逆向文件頻率 =log (語料庫的文件總數 / (包含該詞的文件總數+1));
如果一個詞越常見,那麼其分母就越大,IDF值就越小。
但還是有詞向量長度的問題。
word2vec
將獨熱編碼當作輸入,經過神經網路,判斷one hot輸出的是什麼詞
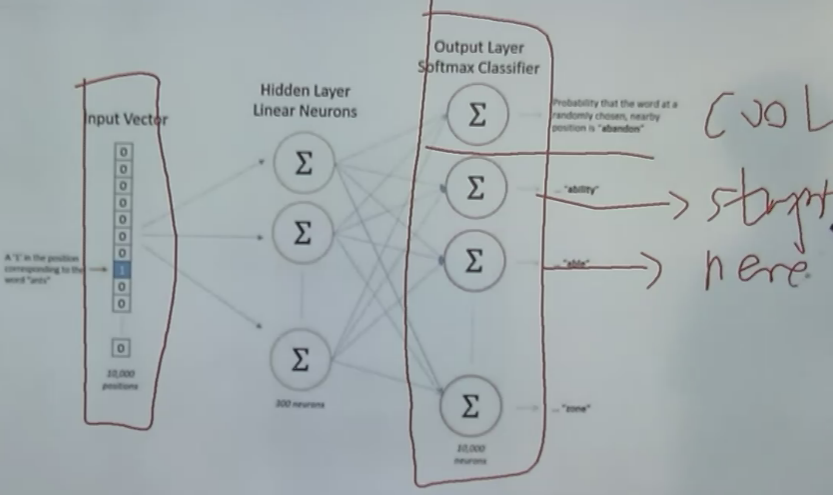
但是並沒有關心輸出的詞是什麼。隱藏層,100個隱藏神經元,100個權重。
而是將神經網路過程中的該層的權重作為了詞向量。vector。