
幾種運維工具的對比
運維行業有句話:“無監控、不運維”,是的,一點也不誇張,監控俗稱“第三隻眼”。沒了監控,什麼基礎運維,業務運維都是“瞎子”。
所以說監控是運維這個職業的根本。尤其是在現在DevOps這麼火的時候,用監控資料給自己撐腰,這顯得更加必要。
有人說運維是背鍋俠,那麼,有了監控,有了充足的資料,一切以資料說話,運維還需要背鍋嗎,所以作為一個運維工程師,如何構建一套監控系統是你的第一件工作。
在《無監控,不運維》中讓我們以全域性的眼光,探討一下運維監控工具如何選型以及構建運維監控平臺的設計思路。(PS:現在訂閱,享早鳥價,今天結束!)
1.常見的運維監控工具
現在運維監控工具非常多,哪個好,哪個不好,哪個適合你,哪個不適合你,其實只有你瞭解了他們的特性後,才知道,所以從這裡開始講起。
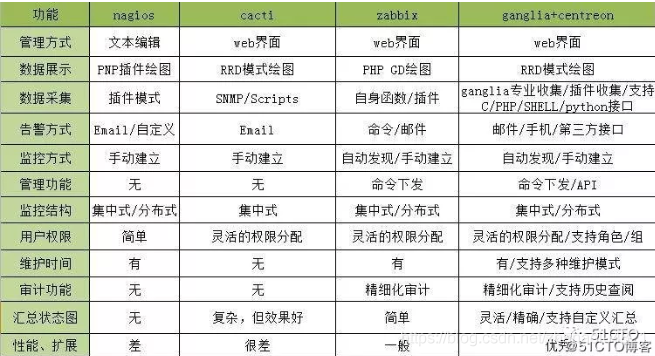
Cacti
Cacti是一套基於PHP,MySQL,SNMP及RRDTool開發的網路流量監測圖形分析工具。
簡單的說Cacti就是一個PHP程式。它通過使用SNMP協議獲取遠端網路裝置和相關資訊,(其實就是使用Net-SNMP 軟體包的snmpget 和snmpwalk 命令獲取)並通過RRDTOOL工具繪圖,通過PHP程式展現出來。我們使用它可以展現出監控物件一段時間內的狀態或者效能趨勢圖。
Cacti是很老的一款監控工具了,其實說它是一款流量監控工具更合適,對流量監控比較精準,但缺點很多,出圖不好看,不支援分散式,也沒有告警功能,所以使用的人會越來越少。
Nagios
Nagios是一款開源的免費網路監視工具,能有效監控Windows、Linux和Unix的主機狀態,交換機路由器等網路設定,印表機等。在系統或服務狀態異常時發出郵件或簡訊報警第一時間通知網站運維人員,在狀態恢復後發出正常的郵件或簡訊通知。
Nagios主要的特徵是監控告警,最強大的就是告警功能,可支援多種告警方式,但缺點是沒有強大的資料收集機制,並且資料出圖也很簡陋,當監控的主機越來越多時,新增主機也非常麻煩,配置檔案都是基於文字配置的,不支援web方式管理和配置,這樣很容易出錯,不宜維護。
Zabbix
Zabbix是一個基於WEB介面的提供分散式系統監視以及網路監視功能的企業級的開源解決方案。zabbix能監視各種網路引數,保證伺服器系統的安全運營;並提供強大的通知機制以讓系統運維人員快速定位/解決存在的各種問題。
Zabbix由2部分構成,zabbix server與可選元件zabbix agent。zabbix server可以通過SNMP,zabbix agent,ping,埠監視等方法提供對遠端伺服器/網路狀態的監視,資料收集等功能,它可以執行在Linux, Solaris, HP-UX, AIX, Free BSD, Open BSD, OS X等平臺上。
Zabbix解決了cacti沒有告警的不足,也解決了nagios不能通過web配置的缺點,同時還支援分散式部署,這使得它迅速流行起來,zabbix也成為目前中小企業監控最流行的運維監控平臺。
當然,Zabbix也有不足之處,它消耗的資源比較多,如果監控的主機非常多時,可能會出現監控超時、告警超時等現象,不過也有很多解決辦法,比如提高硬體效能、改變zabbix監控模式等。
Ganglia
Ganglia是一款為HPC(高效能運算)叢集而設計的可擴充套件的分散式監控系統,它可以監視和顯示叢集中的節點的各種狀態資訊,它由執行在各個節點上的gmond守護程序來採集CPU 、記憶體、硬碟利用率、I/O負載、網路流量情況等方面的資料,然後彙總到gmetad守護程序下,使用rrdtool儲存資料,最後將歷史資料以曲線方式通過PHP頁面呈現。
Ganglia監控系統有三部分組成,分別是gmond、gmetad、webfrontend。gmond安裝在需要收集資料的客戶端,gmetad是服務端,webfrontend是一個php的web ui介面,ganglia通過gmond收集資料,然後在webfrontend進行展示。
Ganglia的主要特徵是收集資料,並集中展示資料,這是ganglia的優勢和特色,ganglia可以將所有資料彙總到一個介面集中展示,並且支援多種資料介面,可以很方面的擴充套件監控,同時,最為重要的是,ganglia收集資料非常輕量級,客戶端的gmond程式基本不耗費系統資源,而這個特點剛好彌補了zabbix消耗效能的不足。
最後,Ganglia在對大資料平臺的監控更為智慧,只需要一個配置檔案,即可開通Ganglia對hadoop、spark的監控,監控指標有近千個,完全滿足了對大資料平臺的監控需求。
Centreon
Centreon是一款功能強大的分散式IT監控系統,它通過第三方元件可以實現對網路、作業系統和應用程式的監控:首先,它是開源的,我們可以免費使用它;其次,它的底層採用類似nagios的監控引擎作為監控軟體,同時監控引擎通過ndoutil模組將監控到的資料定時寫入資料庫中,而Centreon實時從資料庫讀取該資料並通過Web介面展現監控資料;最後,我們可以通過Centreon web一鍵管理和配置主機,或者說Centreon就是nagios的一個管理配置工具,通過Centreon提供的Web配置介面,可以輕鬆完成nagios需要手工配置主機和服務的不足。
Centreon的強項是一鍵配置和管理,並支援分散式監控,nagios能夠完成的功能,通過centreon都能實現,同時,centreon還可以和ganglia進行整合,centreon將ganglia收集到的資料進行整合,可以實現主機自動加入監控以及自動告警的功能。
Prometheus
Prometheus是一套開源的系統監控報警框架,它既適用於面向伺服器等硬體指標的監控,也適用於高動態的面向服務架構的監控。對於現在流行的微服務,Prometheus的多維度資料收集和資料篩選查詢語言也是非常的強大。Prometheus是為服務的可靠性而設計的,當服務出現故障時,它可以使你快速定位和診斷問題。
Grafana
Grafana是一個開源的度量分析與視覺化套件,通俗的說,Grafana就是一個圖形視覺化展示平臺,它通過各種炫酷的介面效果展示我們的監控資料,
如果你覺得zabbix的出圖介面不夠好看,逼格不夠高,就可以使用Grafana的視覺化展示,同時,Grafana支援許多不同的資料來源,Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB都可以完美支援。
對比圖
2.統一運維監控平臺設計思路
運維監控平臺不是簡單的下載一個開源工具,然後搭建起來就行了,它需要根據監控的環境和特點進行各種整合和二次開發,以達到與自己的需求完全吻合的程度。那麼下面就談談運維監控平臺的設計思路。
構建一個智慧的運維監控平臺,必須以執行監控和故障報警這兩個方面為重點,將所有業務系統中所涉及的網路資源、硬體資源、軟體資源、資料庫資源等納入統一的運維監控平臺中,並通過消除管理軟體的差別。
資料採集手段的差別,對各種不同的資料來源實現統一管理、統一規範、統一處理、統一展現、統一使用者登入、統一許可權控制,最終實現運維規範化、自動化、智慧化的大運維管理。
智慧的運維監控平臺,設計架構從低到高可以分為6層,三大模組,如下圖:
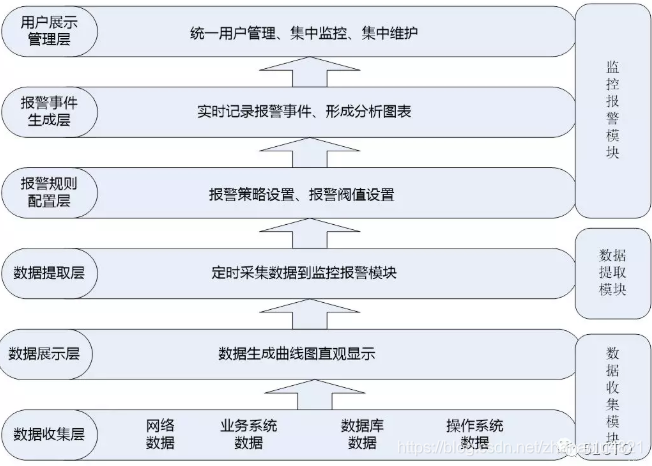
資料收集層:位於最底層,主要收集網路資料、業務系統資料、資料庫資料、作業系統資料等,然後將收集到的資料進行規範化並進行儲存。
資料展示層:位於第二層,是一個Web展示介面,主要是將資料收集層獲取到的資料進行統一展示,展示的方式可以是曲線圖、柱狀圖、餅狀態等,通過將資料圖形化,可以幫助運維人員瞭解一段時間內主機或網路的執行狀態和執行趨勢,並作為運維人員排查問題或解決問題的依據。
資料提取層:位於第三層,主要是對從資料收集層獲取到的資料進行規格化和過濾處理,提取需要的資料到監控報警模組,這個部分是監控和報警兩個模組的銜接點。
報警規則配置層:位於第四層,主要是根據第三層獲取到的資料進行報警規則設定、報警閥值設定、報警聯絡人設定和報警方式設定等。
報警事件生成層:位於第五層,主要是對報警事件進行實時記錄,將報警結果存入資料庫以備呼叫,並將報警結果形成分析報表,以統計一段時間內的故障率和故障發生趨勢。
使用者展示管理層:位於最頂層,是一個Web展示介面,主要是將監控統計結果、報警故障結果進行統一展示,並實現多使用者、多許可權管理,實現統一使用者和統一許可權控制。
在這6層中,從功能實現劃分,又分為三個模組,分別是資料收集模組、資料提取模組和監控報警模組,每個模組完成的功能如下:
資料收集模組:此模組主要完成基礎資料的收集與圖形展示。資料收集的方式有很多種,可以通過SNMP實現,也可以通過代理模組實現,還可以通過自定義指令碼實現。常用的資料收集工具有Cacti、Ganglia等。
資料提取模組:此模板主要完成資料的篩選過濾和採集,將需要的資料從資料收集模組提取到監控報警模組中。可以通過資料收集模組提供的介面或自定義指令碼實現資料的提取。
監控報警模組:此模組主要完成監控指令碼的設定、報警規則設定,報警閥值設定、報警聯絡人設定等,並將報警結果進行集中展現和歷史記錄。常見的監控報警工具有Nagios、Centreon等。
在瞭解了運維監控平臺的一般設計思路之後,接下來詳細介紹下如何通過軟體實現這樣一個智慧運維監控系統。
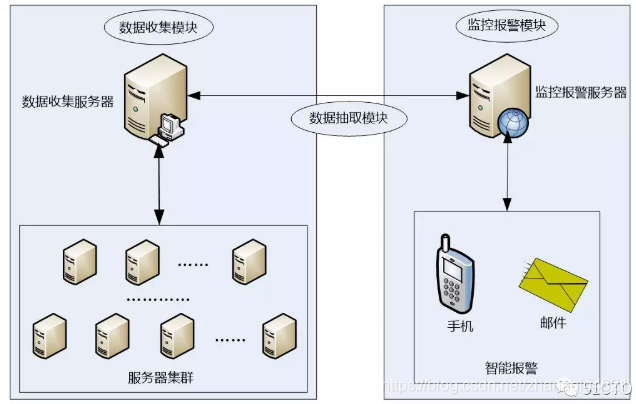
下圖是根據上圖的設計思路形成的一個運維監控平臺實現拓撲圖,從圖中可以看出,主要有三大部分組成,分別是資料收集模組、監控報警模組和資料提取模組。
其中,資料提取模組用於其他兩個模組之間的資料通訊,而資料收集模組可以有一臺或多臺資料收集伺服器組成,每個資料收集伺服器可以直接從伺服器群組收集各種資料指標,經過規範資料格式,最終將資料儲存到資料收集伺服器中。
監控報警模組通過資料抽取模組從資料收集伺服器獲取需要的資料,然後設定報警閥值、報警聯絡人等,最終實現實時報警。報警方式支援手機簡訊報警、郵件報警等,另外,也可以通過外掛或者自定義指令碼來擴充套件報警方式。這樣一整套監控報警平臺就基本實現了。
3.企業運維監控平臺選型
中小企業監控平臺選擇Zabbix
Zabbix是一款綜合了資料收集、資料展示、資料提取、監控報警配置、使用者展示等方面的一款綜合運維監控平臺。
Zabbix學習入門較快,功能也很強大,是一個可以迅速用起來的監控軟體,能夠滿足中小企業的監控報警需求,因此是中小型企業運維監控的首選平臺。
但是,Zabbix當監控伺服器數量較多時,會產生很多問題,如監控資料不準確、報警超時等等問題,這是因為Zabbix對伺服器效能要求較高,當監控的伺服器數量超過500臺後,監控效能急劇下降,此時需要進行分散式監控部署,並且需要提升監控伺服器的效能。
安全性方面,Zabbix客戶端的agent如果故障,收集到的資料將丟失,同時Zabbix Server也是單點,可能還需要對Zabbix Server做HA保證資料的安全和監控的高可用。
網際網路大企業監控平臺選擇Ganglia+Centreon
開源監控軟體組合應用+二次開發是大型網際網路企業構建監控平臺的一個基本策略,對於有海量伺服器、多業務系統的複雜監控,沒有哪個軟體能獨立完成企業的所有監控需求,因此,多種開源監控軟體組合應用+二次開發才是監控平臺的最終方向。
推薦ganglia是因為ganglia客戶端軟體對服務資源佔用非常低,並且擴充套件外掛非常多,監控擴充套件也非常容易,同時結合專業的web監控平臺centreon,可以實現在資料收集、資料展示、資料提取、監控報警配置、使用者展示等方面的完美配合,因此這裡對海量伺服器進行監控我們推薦ganglia+centreon組合。
4.說說我們運維監控平臺的演變歷程
這是一個經驗和總結,我結合這麼多年我們監控平臺的演變,總結了一下不同階段、不同機器數量,監控平臺需要的構建思路和策略。
機器數量小於100臺的階段
這個時期由於機器數量較少,因此,對監控的需求也很簡單,監控的用途可能主要用於通知問題、快速定位與解決問題,大致總結一下,此階段監控平臺的特點如下:
1>部署簡單,上手易用
2>穩定執行,不出故障
3>可進行報警,以郵件、簡訊等形式
基於以上特點和需求,可以使用比較流行開源的監控軟體Nagios,Cacti,Zabbix,Ganglia等等。流行的開源產品文件很多,可快速上手,並且有大量的前人使用經驗,遇到問題也很容易解決。
最初我們選擇了nagios,因為這款軟體是最早流行的,後來因為主機和服務新增不方便,切換到了zabbix上了,此階段,zabbix應該是最好的選擇。
機器數量200到1000的階段
這個階段,由於機器數量變多,監控需求也開始變得複雜,不過主要還是用於通知、告警,發現問題,並避免同樣的問題再次發生,根據這個階段的特點,我們在這個時期主要對監控平臺做了以下工作:
1>監控內容分類:由於要監控的機器很多,監控內容也隨之增多,於是我們將監控根據用途不同,進行了分類,主要分為系統基礎監控資料、網路監控資料和業務監控資料。
2>全覆蓋式監控:將所有機器均納入監控中,主要包含軟體監控和硬體監控,硬體監控主要是監控硬體效能和故障,軟體監控除了第一步提到的各種基礎監控資料外,還增加了業務邏輯監控,儘可能的覆蓋業務流程,通過大量自定義監控減少和去除重複的問題,保障業務穩定執行。
3>多種告警方式,確保無漏報:將所有監控根據重要程度、緊急程度進行分類,分別用郵件,微信,簡訊,電話等不同級別的方式進行通知,每個監控對應到不同的人,確保每個監控都有人處理,並且對於重要的業務採用持續通知的方式,不處理就一直通知。
這個階段的難點是對告警資訊的處理,由於機器越來越多,需要監控的服務也越來越多,告警資訊就出現了爆發式增長,每天收到上千封報警郵件是經常的事情。 過多的郵件出現,其實就失去了告警的意義,因為我們不可能去檢視每一封郵件,而這麼多告警郵件中,很多都是非必要的告警,例如系統負載偶爾增高一下,就發了告警郵件,這完全是不需要的。
因此,這個階段,主要是對監控告警策略進行配置和優化,儘量減少不必要的告警郵件,例如,對系統負載的監控,可以選擇連續幾次負載超過閥值,然後持續多久之後才進行告警操作,通過對告警策略的優化,告警資訊大大減少,每天最多幾十封,這樣的話,就不會錯過任何告警資訊了。
機器數量超過1000臺的階段
由於業務持續增長,對伺服器需求越來越多,當我們的伺服器超過1000臺以後,監控的情況發生了變化,或者說監控出現了很多奇怪的問題,主要有如下一些:
1>告警不及時
當我們伺服器超過1000臺以後,我們的zabbix就經常罷工,有時候監控資料不能及時顯示,有時候告警遲遲不來,特別是告警延時,這個是最恐怖的事情,線上業務7*24小時不能出現故障,雖然監控到了異常,但是通過監控系統發出來已經是1個或者幾個小時之後了,那監控還有什麼意義呢,及時性是監控系統的第一要求,這個是必須要解決的問題。
如何解決這個問題呢,除了對監控進行優化,例如分散式proxy方式部署,開啟zabbix主動模式,還對資料收集進行了擴充套件和優化,我們對基礎資料的收集,拋棄了zabbix來實現,而採用ganglia,而對業務資料部分實現仍然採用zabbix完成,通過將收集資料的負載進行分擔,大大減低了zabbix的負載,資料收集的準確性,及時性又恢復正常了。
2>告警系統出現了單點故障
由於伺服器眾多,收集的資料也飛速增長,曾經有一次,監控伺服器突然意外宕機了,等系統恢復啟動起來,已經是一個小時以後了,這一個小時運維就變成了睜眼瞎了,多可怕的事情。
自從發生監控系統宕機事故後,我們對監控伺服器進行了分散式高可用部署,以避免單點故障,同時對監控到的資料進行遠端異地備份,當監控伺服器故障後,會自動切換到備用監控系統上,並且監控資料自動儲存同步。
3>告警需求監控系統無法滿足
業務的增加,客戶對業務穩定性要求變得更加苛刻,為了保證業務系統穩定執行,業務邏輯監控需求被提出來了,業務邏輯監控就是對業務系統的執行邏輯進行監控,當業務執行邏輯故障時候,也需要進行告警,很顯然,對業務邏輯的監控,沒有現成的工具和程式碼,只能根據業務邏輯自行開發,通過提高業務邏輯介面,彙報資料等方式,我們對zabbix進行了多項二次開發,以滿足對業務邏輯的監控。
最後,運維監控平臺是運維工作中不可或缺的一部分,如何構建適合自己的運維監控平臺,每個公司的需求不一樣,每個運維面對的痛點也不盡相同,但,不管有什麼需求,多少需求,萬變不離其宗,有了機器上的各種監控資料,運維就能做很多事情。運維監控的路上,我們一起前行。