
淺析x86架構中cache的組織結構
這篇文章誕生的源頭是我之前在stackoverflow看到的一個問題:
Why is transposing a matrix of 512×512 much slower than transposing a matrix of 513×513 ?
這個問題雖然國外的大神給出了完美的解釋,但是我當時看過之後還是一頭霧水。想必對x86架構上的cache沒有較深入瞭解過的童鞋看過之後也是一樣的感受吧。於是趁著寒假回家第一天還沒有過多外界干擾的時候,我們就來詳細的研究下x86架構下cache的組織方式吧。
我們就由這個問題開始討論吧。這個問題說為什麼轉置一個512×512的矩陣反倒比513×513的矩陣要慢?(不知道什麼是矩陣轉置的童鞋補習線性代數去)提問者給出了測試的程式碼以及執行的時間。
不過我們不知道提問者測試機器的硬體架構,不過我的測試環境就是我這檯筆記本了,x86架構,處理器是Intel Core i3-2310M 2.10GHz。順便囉嗦一句,在linux下,直接用cat命令檢視/proc/cpuinfo這個虛擬檔案就可以檢視到當前CPU的很多資訊。
首先,我們將提問者給出的程式碼修改為C語言版,然後編譯執行進行測試。提問者所給出的這段程式碼有邏輯問題,但是這和我們的討論主題無關,所以請無視這些細節吧 :),程式碼如下:
1 |
#include <stdio.h> |
我的機器上得出瞭如下的測試結果:
Average for a matrix of 513 : 0.003879 s
Average for a matrix of 512 : 0.004570 s
512×512的矩陣轉置確實慢於513×513的矩陣,但是有意思的是我並沒有提問者那麼懸殊的執行結果。不過在編譯命令列加上引數 -O2 優化後差異很明顯了:
Average for a matrix of 513 : 0.001442 s
Average for a matrix of 512 : 0.005469 s
也就是說512×512的矩陣居然比513×513的矩陣轉置平均慢了近4倍!
那麼,是什麼原因導致這個神奇的結果呢?
- 如果真是cache的緣故,那麼cache又是如何影響程式碼執行的效率呢?
- 如果是因為cache具體的組織方式帶來的特殊現象,那cache究竟是怎麼組織的呢?
- 除此之外,僅僅是512×512的矩陣轉置慢嗎?其它的數字又會怎樣呢?
- 搞明白了cache的組織方式之後,能給我們平時寫程式碼定義變數有怎樣的啟示呢?
好了,我們提出的問題足夠多了,現在我們來嘗試在探索中逐一解答這些問題,並嘗試分析一些現代CPU的特性對程式碼執行造成的影響。
我們從cache的原理說起,cache存在的目的是在高速的CPU和較低速的主儲存器之間建立一個數據儲存的緩衝地帶,通常由SRAM製造,訪問速度略慢於CPU的暫存器,但是卻高於DRAM製造的主儲存器。因為製造成本過高,所以cache的容量一般都很小,一般只有幾MB甚至幾十到幾百KB而已。那你可能會說,這麼小的cache怎麼可能有大作用。有趣的是還真有大作用,由於程式的區域性性原理的存在,小容量的cache在工作時能輕易達到90%以上的讀寫命中率。區域性性原理分為時間區域性性和空間區域性性,這裡不再詳述,有興趣的童鞋請參閱其他資料。
順便插一句嘴,不光金字塔型的儲存器體系結構和製造成本相關,甚至我覺得計算機體系結構很大程度受制於成本等因素的考量。假設主儲存器的儲存速率能和CPU暫存器比肩的話,cache肯定就會退出歷史的舞臺了。如果磁碟的讀寫速度能達到暫存器級別並且隨機存取,那恐怕記憶體也就沒有存在的必要的……
言歸正傳,我們如何檢視自己機器上CPU的cache資訊呢?/proc/cpuinfo這裡是沒有的,我們需要使用lscpu命令檢視,這條命令在我的機器上得到了如下的輸出結果:
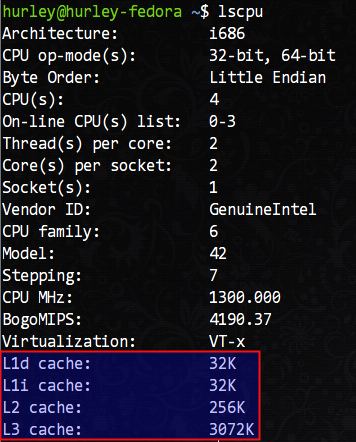
可以看到,我的機器擁有L1d(L1資料cache)和L1i(L1指令cache)各32KB、L2 cache 256KB、L3 cache 3072KB(3MB)。
L1快取居然分為資料快取和指令快取,這不是哈佛架構麼?x86不是馮·諾伊曼架構麼,怎麼會在儲存區域區分指令和資料?其實,教科書中講述的都是完全理想化的模型,在實際的工程中,很難找到這種理想化的設計。就拿作業系統核心而言,儘管所謂的微核心組織結構更好,但是在目前所有知名的作業系統中是找不到完全符合學術意義上的微核心的例子。工程上某些時候就是一種折衷,選擇更“接地氣”的做法,而不是一味的契合理論模型。
既然cache容量很有限,那麼如何組織資料便是重點了。接下來,我們談談cache和記憶體資料的對映方式。一般而言,有所謂的全相聯對映,直接相聯對映和組相聯對映三種方式。
CPU和cache是以字為單位進行資料交換的,而cache卻是以行(塊)(即Cache Block,或Cache Line)為單位進行資料交換的。在cache中劃分若干個字為一行,在記憶體中劃分若干個字為一塊,這裡的行和塊是大小相等的。CPU要獲取某記憶體地址的資料時會先檢查該地址所在的塊是否在cache中,如果在稱之為cache命中,CPU很快就可以讀取到所需資料;反之稱為cache未命中,此時需要從記憶體讀取資料,同時會將該地址所在的整個記憶體塊複製到cache裡儲存以備再次使用。
我們依次來看這三種對映方式,首先是全相聯對映,這種對映方式很簡單,記憶體中的任意一塊都可以放置到cache中的任意一行去。為了便於說明,我們給出以下的簡單模型來理解這個設計。
我們假設有一個4行的cache,每行4個字,每個字佔4個位元組,即64位元組的容量。另外還有256位元組(16塊,每塊4字,每字4位元組)的一個RAM儲存器來和這個cache進行對映。對映結構如圖所示:
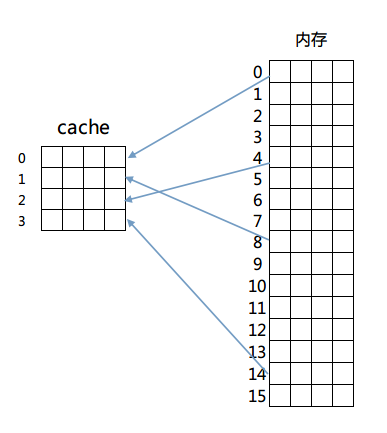
那麼如何判斷cache是否命中呢?由於記憶體和cache是多對一的對映,所以必須在cache儲存一行資料的同時標示出這些資料在記憶體中的確切位置。簡單的說,在cache每一行中都有一個Index,這個Index記錄著該行資料來自記憶體的哪一塊(其實還有若干標誌位,包括有效位(valid bit)、髒位(dirty bit)、使用位(use bit)等。這些位在保證正確性、排除衝突、優化效能等方面起著重要作用)。那麼在進行一個地址的判斷時,採用全相聯方式的話,因為任意一行都有可能存在所需資料,所以需要比較每一行的索引值才能確定cache中是否存在所需資料。這樣的電路延遲較長,設計困難且複雜性高,所以一般只有在特殊場合,比如cache很小時才會使用。
然後是第二種方法:直接相連對映。這個方法固定了行和塊的對應關係,例如記憶體第0塊必須放在cache第0行,第一塊必須放在第一行,第二塊必須放在第二行……迴圈放置,即滿足公式:
記憶體塊放置行號 = 記憶體塊號 % cache總行數
對映如圖所示:
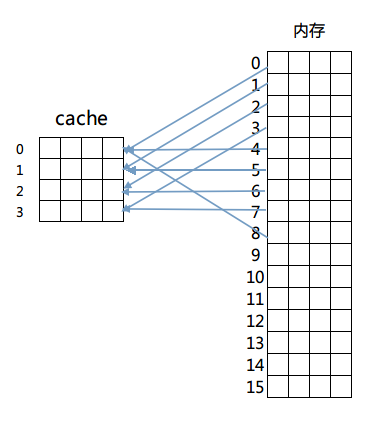
這樣做解決了比較起來困難的問題,由於每一塊固定到了某一行,只需要計算出目標記憶體所在的行號進行檢查即可判斷出cache是否命中。但是這麼做的話因為一旦發生衝突就必須換出cache中的指定行,頻繁的更換快取內容造成了大量延遲,而且未能有效利用程式執行期所具有的時間區域性性。
綜上,最終的解決方案是最後的組相聯對映方式(Set Associativity),這個方案結合了以上兩種對映方式的優點。具體的方法是先將cache的行進行分組,然後記憶體塊按照組號求模來決定該記憶體塊放置到cache的哪一個組。但是具體放置在組內哪一行都可以,具體由cache替換演算法決定。
我們依舊以上面的例子來說明,將cache裡的4行分為兩組,然後採用記憶體裡的塊號對組號求模的方式進行組號判斷,即記憶體0號塊第一組裡,2號塊放置在第二組裡,3號塊又放置在第一組,以此類推。這麼做的話,在組內發生衝突的話,可以選擇換出組內一個不經常讀寫的記憶體塊,從而減少衝突,更好的利用了資源(具體的cache替換策略不在討論範圍內,有興趣的童鞋請自行研究)。同時因為組內行數不會很多,也避免了電路延遲和設計的複雜性。
x86中cache的組織方式採用的便是組相聯對映方式。
上面的闡述可能過於簡單,不過大家應該理解了組相聯對映方式是怎麼回事了。那麼我們接下來結合我的機器上具體的cache對映計算方法繼續分析。
我們剛說過組相聯對映方式的行號可以通過 塊號 % 分組個數 的公式來計算,那麼直接給出一個記憶體地址的話如何計算呢?其實記憶體地址所在的塊號就是 記憶體地址值 / 分塊位元組數,那麼直接由一個記憶體地址計算出所在cache中的行分組的組號計算公式就是:
記憶體地址所在cache組號 = (記憶體地址值 / 分塊位元組數) % 分組個數
很簡單吧?假定一個cache行(記憶體塊)有4個字,我們畫出一個32位地址拆分後的樣子:

因為字長32的話,每個字有4個位元組,所以需要記憶體地址最低2位時位元組偏移,同理每行(塊)有4個字,塊內偏移也是2位。這裡的索引位數取決於cache裡的行數,這個圖裡我畫了8位,那就表示cache一共有256個分組(0~255)存在,每個分組有多少行呢?這個隨意了,這裡的行數是N,cache就是N路組相聯對映。具體的判斷自然是取tag進行組內逐一匹配測試了,如果不幸沒有命中,那就需要按照cache替換演算法換出組內的一行了。順帶畫出這個地址對應的cache結構圖:
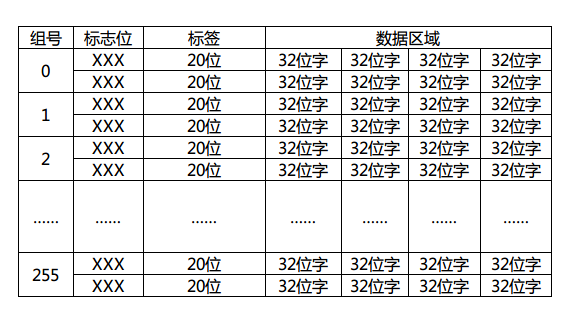
標誌位是有效位(valid bit)、髒位(dirty bit)、使用位(use bit)等,用於該cache行的寫回演算法,替換演算法使用。這裡簡單期間我就畫了一個2路組相聯對映的例子出來。現在大家應該大致明白cache工作的流程了吧?首先由給出的記憶體地址計算出所在cache的組號(索引),再由判斷電路逐一比較標籤(tag)值來判斷是否命中,若命中則通過行(塊)內偏移返回所在字資料,否則由cache替換演算法決定換出某一行(塊),同時由記憶體調出該行(塊)資料進行替換。
其實工作的流程就是這樣,至於cache寫回的策略(寫回法,寫一次法,全寫法)不在本文的討論範圍之內,就不細說了。
有了以上鋪墊,我們終於可以來解釋那個512×512的矩陣轉置問題了。很艱難的鋪墊,不是嗎?但我們距離勝利越來越近了。
512×512的矩陣,或者用C語言的說法稱之為512×512的整型二維陣列,在記憶體中是按順序儲存的。
那麼以我的機器為例,在上面的lscpu命令輸出的結果中,L1d(一級資料快取)擁有32KB的容量。但是,有沒有更詳細的行大小和分組數量的資訊?當然有,而且不需要多餘的命令。在/sys/devices/system/cpu目錄下就可以看到各個CPU核的所有詳細資訊,當然也包括cache的詳細資訊,我們主要關注L1d快取的資訊,以核0為例,在/sys/devices/system/cpu/cpu0/cache目錄下有index0~index4這四個目錄,分別對應L1d,L1i,L2,L3的資訊。我們以L1d(index0)為例檢視詳細引數。
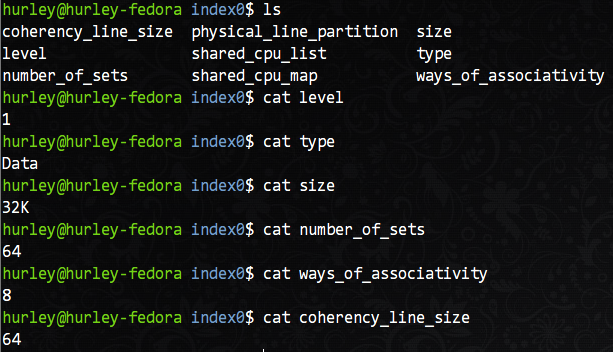
從圖中我們可以知道,這是L1資料快取的相關資訊:共有64個組,每組8行,每行16字(64位元組),共有32KB的總容量。按照我們之前的分析,相信你很容易就能說出這個機器上L1d快取的組織方式。沒錯,就是8路組相聯對映。
順帶貼出Intel的官方文件證明我不是在信口開河:

此時32位記憶體地址的拆分如下:
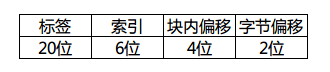
對應的cache圖想必也難不倒大家吧?和上邊的cache結構不同的就是改變了分組數量、每組行數和每行大小。
我們繼續分析轉置問題。每個cache行(塊)擁有64個位元組,正好是16個int變數的大小。一個n階矩陣的一個行正好填充n / 16個cache行。512階矩陣的話,每個矩陣的行就填充了32個組中的行,2個矩陣的行就覆蓋了64個組。之後的行若要使用,就必然牽扯到cache的替換了。如果此時二維陣列的array[0][0]開始從cache第一行開始放置。那麼當進入第二重for迴圈之後,由於記憶體地址計算出的cache組號相同,導致每一個組中的正在使用的cache行發生了替換,不斷髮生的組內替換使得cache完全沒有發揮出效果,所以造成了512×512的矩陣在轉置的時候耗時較大的原因。具體的替換點大家可以自行去計算,另外513×513矩陣大家也可以試著去分析沒有過多cache失效的原因。不過這個問題是和CPU架構有關的,所以假如你的機器沒有產生同樣的效果,不妨自己研究研究自己機器的cache結構。
另外網上針對這個問題也有諸多大牛給出的解釋,大家不妨參照著理解吧。別人說過的我就不說了,大家可以參考著分析。
原本想把這篇作為上篇,再去寫一個下篇講述一些程式設計中要注意的問題。不過偶然間看到了微軟大牛Igor Ostrovsky的博文《Gallery of Processor Cache Effects》,瞬間感覺自己不可能寫的更好了。所以推薦大家去讀這篇文章。如果感覺英文吃力的話,耗子叔這裡有@我的上鋪叫路遙做的翻譯解釋《7個示例科普CPU Cache》。
另外,開源中國這裡的一篇譯文也有參考價值:《每個程式設計師都應該瞭解的 CPU 快取記憶體》。