
卷積神經網路對CIFAR資料集分類
阿新 • • 發佈:2018-12-22
本例通過一個具有全域性平局池化層的神經網路對CIFAR資料集分類
1.匯入標頭檔案引入資料集
這部分使用cifar10_input裡面的程式碼,在cifar10資料夾下建立卷積檔案,部分程式碼如下:
import cifar10_input import tensorflow as tf import numpy as np batch_size = 128 data_dir = 'cifar-10-batches-bin/' print("begin") images_train, labels_train = cifar10_input.inputs(eval_data = False, data_dir = data_dir, batch_size = batch_size) images_test, labels_test = cifar10_input.inputs(eval_data = True, data_dir = data_dir, batch_size = batch_size) print("bedin data")
2.定義網路結構
對於權重w的定義,統一用函式truncated_normal 來生成標準差為0.1的隨機數為其初始化,對於權重b的定義,統一初始化為0.1。
#定義網路結構 def weight_variable(shape): initial = tf.truncated_normal(shape = shape,stddev = 0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape = shape) return tf.Variable(initial) def conv2d(x, W): return tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding = 'SAME') def max_pool_2x2(x): return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = 'SAME' ) def avg_pool_6x6(x): return tf.nn.avg_pool(x, ksize = [1, 6, 6, 1], strides = [1, 6, 6, 1], padding = 'SAME') #定義佔位符 x = tf.placeholder(tf.float32, [None, 24, 24, 3])#cifar data的shape為24*24*3 y = tf.placeholder(tf.float32, [None, 10])#0~9數字分類=>10 classes W_conv1 = weight_variable([5, 5, 3, 64]) b_conv1 = bias_variable([64]) x_image = tf.reshape(x, [-1, 24, 24, 3]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) W_conv2 = weight_variable([5, 5, 64, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) W_conv3 = weight_variable([5, 5, 64, 10]) b_conv3 = bias_variable([10]) h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3) nt_hpool3 = avg_pool_6x6(h_conv3)#10 nt_hpool3_flat = tf.reshape(nt_hpool3, [-1,10]) y_conv = tf.nn.softmax(nt_hpool3_flat) cross_entropy = -tf.reduce_sum(y*tf.log(y_conv)) train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) correct_perdiction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_perdiction, "float"))
3.執行session進行訓練
啟動session,迭代15000次。
sess = tf.Session() sess.run(tf.global_variables_initializer()) tf.train.start_queue_runners(sess = sess) for i in range(15000):#20000 image_batch, label_batch = sess.run([images_train, labels_train]) label_b = np.eye(10, dtype = float)[label_batch]#one hot編碼 train_step.run(feed_dict = {x:image_batch, y:label_b}, session = sess) if i%200 == 0: train_accuracy = accuracy.eval(feed_dict = {x:image_batch, y:label_b}, session = sess) print("step %d, training accuracy %g "%(i, train_accuracy))
4.評估結果
從測試資料集裡面將資料取出,放到模型裡面執行,檢視模型的正確率。
image_batch, label_batch = sess.run([images_test, labels_test])
label_b = np.eye(10, dtype = float)[label_batch] #onehot編碼
print("Finished! test accuracy %g" %accuracy.eval(feed_dict = {x: image_batch, y: label_b}, session = sess))執行程式碼後,輸出如下(部分截圖):
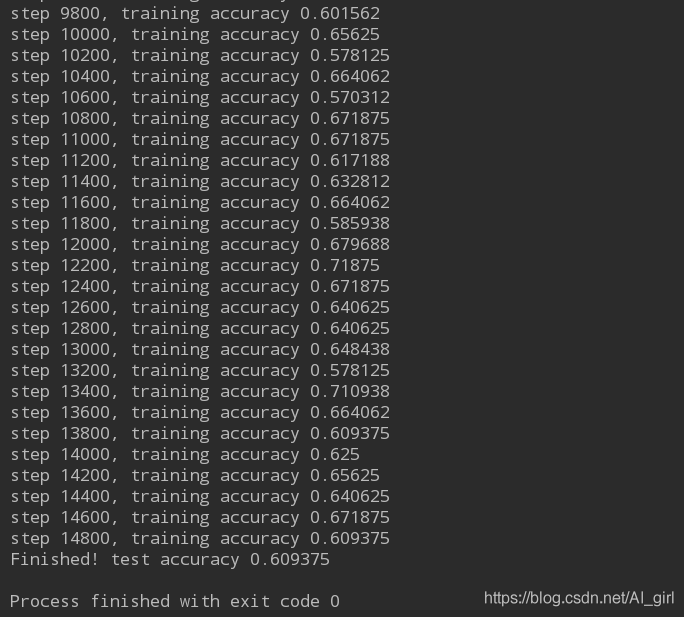
識別效果得到了收斂,正確率在0.6左右,正確率不高,主要是模型相對較為簡單,只用了兩層卷積操作,需要進行優化來提高準確率。